Всім привіт! Хочу спробувати підтримати друкарню та запустити на ній свій цикл статей, в якому я буду писати про розробку та автоматизацію.
Назва профілю “ретранслятор” була обрана не просто так. Більшість статей які будуть написані - теоретична/практична довідка для якогось модуля, з яким я попередньо ознайомився в інтернеті, та зібрав до купи інформацію про нього.
В пілотному, нульовому випуску, поговоримо про те, як штучний інтелект здатен заощаджувати кошти компанії, та як, компанія в якій я працюю, планує використовувати ChatGPT.
Abstract/:
Мені слід розробити модель ШІ на базі OpenAI використовуючи їх API для того, щоб аналізувати інформацію про людей. Результат повинен вміти розрізняти посади людей та визначати в якій області вони працюють: IT, Finance, Sales etc.
Ця робота розкаже про типи задач які здатен вирішувати ШІ, про те як звертатись до ШІ використовуючи JavaScript та які є особливості у використанні API.
Робота містить в собі код, який задля безпеки не рекомендується використовувати у своїх проєктах, він призначений виключно для навчальних цілей.
Theory/:
ChatGPT від OpenAI - дуже потужний інструмент для створення/аналізу/розрахунку чогось, особливо на базі GPT4. Зазвичай вже велика частина сайтів/телеграм каналів роблять контент саме штучним інтелектом, при цьому ви можете не помічати різниці в контенті.
Якось в одному з чату телеграму люди обговорювали що політика конфіденційності - пишеться ШІ. Не вірите? Що ж, перевірмо це :)
Відкриємо політику конфіденційності друкарні -https://drukarnia.com.ua/rules
Я вирішив обрати пункти про “Ваш обліковий запис і обов'язки” та “Модерація”.
Далі слід перекласти текст абияк, результати можна переглянути нижче на рисунку 1:
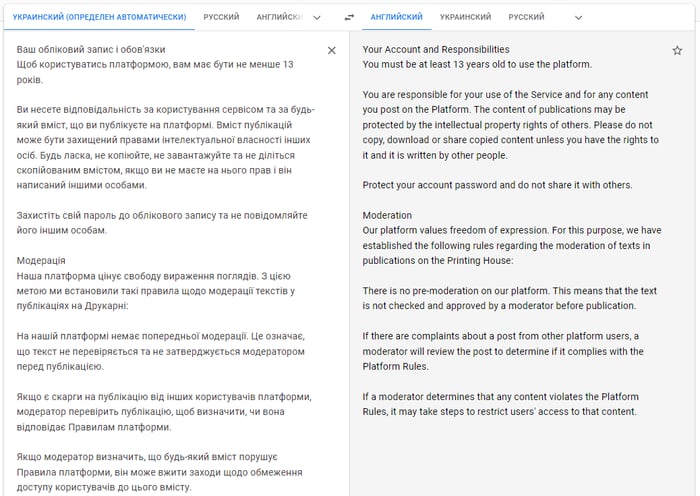
Далі йдемо на сайт https://www.zerogpt.com/ дивитись результати:

Чи дійсно Друкарня писала це з використанням ШІ чи ні, знає лише вона. Головна проблема цих “тестів” - швидке розвинення штучного інтелекту, через що стає все складніше відстежувати текст, який придумав ШІ. Якщо для цікавости ви візьмете мою статтю, та кинете на цей сайт без перекладу, там теж буде великий відсоток начеб-то “ШІ” - але це через те, що “тестер” не працює з кирилицею :(
p.s. якщо ви знайдете або вже знаєте такий, який працює з кирилицею - поділіться в коментарях.
Practice/:
В моїй компанії ШІ буде використовуватись для аналізу даних. Наприклад є текст, його треба проаналізувати та віднести до певної категорії - цей метод має назву Кластеризація.
Загалом є три методи: Класифікація, Кластеризація, та Регресія.
Класифікація – найбільш популярна задача машинного навчання. Вона в чомусь схожа з тим, як дитина вчиться визначати форму і розмір предметів, складаючи їх у роздільні купки.
Регресія – це коли за заданим набором ознак необхідно спрогнозувати якусь цільову змінну.
Кластерний аналіз – задача розбиття заданої вибірки даних (об'єктів) таким чином, щоб кожен кластер складався зі схожих об'єктів, а об'єкти різних кластерів значно відрізнялися одне від одного.
Джерело: https://evergreens.com.ua/ua/articles/classical-machine-learning.html
Мені, як розробнику, треба розробити модель, яка б виконувала рутинну роботу замість людей. Проблема яка наразі вже виникла, це навчити ШІ працювати за правилами моєї компанії (далі правила компанії будуть згадуватись як “мої правила”).
Від самого OpenAI існують Fine-Tune моделі. В чому їх перевага? В тому, що в вас є змога продовжити навчання моделі за своїми правилами.
З кожним випуском інформація буде доповнюватись, стосовно Fine-Tune. Там далеко не все так просто як може здаватись. Пілотний номер лише розкаже про “грубе” звернення до чату з використанням API.
На жаль не знаю від чого залежить сума, але OpenAI видає гранти на користування їх API. В мене, на обліковому записі університету був грант на 18$, який дозволяв мені використовувати моделі ШІ через API:
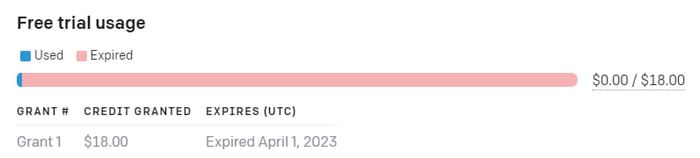
На особистому теж є грант, але на суму 5$:

Я грався з чатом використовуючи JavaScript. Ось простий код, який дозволяє звертатись до чату, але я не рекомендую його використовувати, бо якщо ви залишите такий код у вашому застосунку, ваш ключ можуть вкрасти. Код нижче слід використовувати виключно для тестів:
const apiKey = 'your_key'; //ваш API ключ
const prompt = 'your_prompt'; //ваш запит до чату
const model = 'text-davinci-002'; //модель яку ви використовуєте
fetch('https://api.openai.com/v1/engines/' + model + '/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer ' + apiKey
},
body: JSON.stringify({
prompt: prompt,
max_tokens: 50,
n: 1,
stop: null,
temperature: 1,
})
})
.then(response => response.json())
.then(data => {
console.log('Completion:', data.choices[0].text);
})
.catch(error => {
console.error('Error fetching completions:', error);
});
Трохи поясню код:
prompt - ваше звернення, його бажано редагувати в шапці коду.
max_tokens - об’єм відповіді який буде надано чатом. Тобто чат не буде відповідати більше ніж 50 токенів*
n - це скільки разів буде згенерована відповідь на ваш запит.
stop - стоп слово. (поки що не повністю розумію як то краще використовувати).
temperature - унікальність тексту. Чим вище значення, тим унікальніше текст (від 0 до 1)
*що таке токен можна дізнатись за посиланням та на скриншоті наведеному нижче: https://platform.openai.com/docs/quickstart/adjust-your-settings

Ціль яку мені треба виконати: навчити власну модель яка буде аналізувати інформацію за моїми правилами. Чіткого розуміння що за чим робити в мене немає, буду розбиратись крок за кроком та по можливості доповнювати це в цьому циклі статей.
!!! НЕАКТУАЛЬНО !!!*
API - це не теж саме що чат з яким ми можемо взаємодіяти. Особливість API в тому, що кожен запит надсилається без попередньої історії звернень, ШІ не буде пам’ятати що ви в нього спитали в минулому запиті. На основі цього є розуміння що необхідно буде або надавати всю необхідну інформацію в запиті(токен коштує грошей) - або ж вчити модель розуміти що я в неї питаю
!!! НЕАКТУАЛЬНО !!!*
*дякую за уточнення користувача @Farg0 - API з побудовою в форматі чату підтримує попередню історію спілкування з ШІ. Документація за посиланням: https://platform.openai.com/docs/api-reference/chat
F.A.Q./:
Де взяти ключ API? - створити в власному кабінеті OpenAI https://platform.openai.com/account/api-keys
Як використати цей тестовий код? - знаходячись в браузері натисніть на клавіатурі клавішу “F12”, або якщо ви з ноутбука “Fn + F12” - далі знайдіть вкладку “Console”:
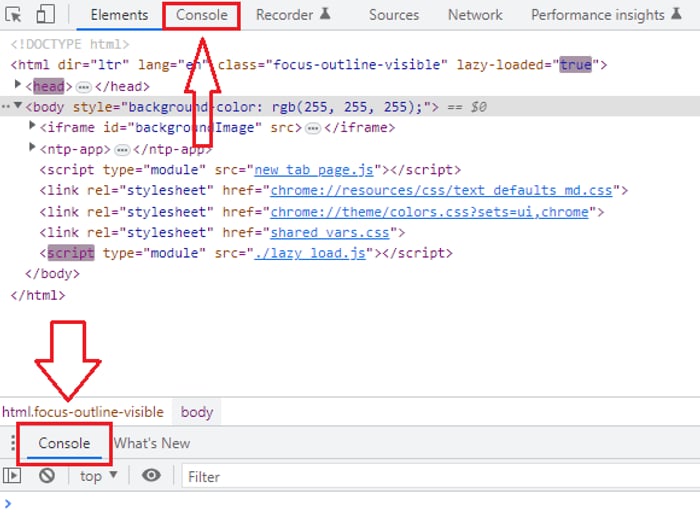
Останнє, що слід зробити - це скопіювати код, змінивши деякі змінні на свої параметри/дані та вставити в консоль, після чого ви повинні отримати відповідь від моделі “text-davinci-002” або іншої, якщо ви змінювали цей показник.
Conclusion/:
API влаштовано дуже цікавим чином. Вам може здатися що плата буде зніматись за кількість запитів, але це не так. Гроші знімаються лише за кількість відправлених та отриманих токенів. Витрати можна легко відстежувати в особистому кабінеті за посиланням: https://platform.openai.com/account/usage
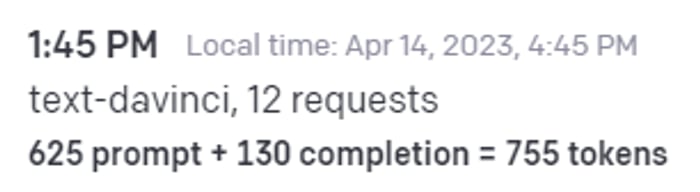
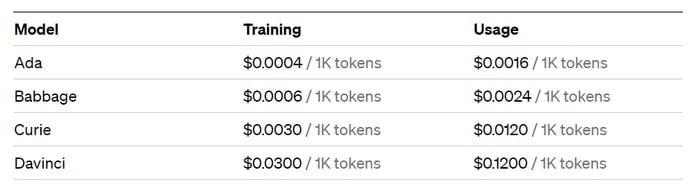
Якщо дивитись на рисунок 7, то можна зрозуміти що я надіслав чату 625 токенів як запит, та отримав відповідь у кількості 130 токенів - разом я заплатив за 755 токенів. Ціни зазвичай вказуються за тисячу токенів. Ціну до кожної моделі можна дізнатись тут: https://openai.com/pricing
Від автора:
Зазвичай я не буду писати що на вас очікує в наступному випуску, бо сам не буду цього знати, але наступна тема буде зав’язана на створені локального сервера та надіслання запитів до ШІ через свій сервер + пояснення того, як створювати якісні запити до ШІ (за моїм досвідом).
Буду також вдячний за відгук стосовно цієї статті, чи всі питання які були підняті - розкриті повною мірою? Всім гарного дня, скоро ще побачимось! :)
