Нещодавно я відкрив для себе канал Charm CLI і вирішив cпробувати деякі з розроблених ними продуктів та оновити свої навички написання bash скриптів. Вибір пав на gum - інструмент для створення ефектних шел скриптів. Перш за все всі проекти Charm написані на Go. Тому треба інсталювати Go і налаштувати шляхи. Після цього можна встановлювати gum.
Подивимось які можливості нам пропонує gum:
[cr1m3s@cr1m3spc:]$ gum -h
Usage: gum <command>
A tool for glamorous shell scripts.
Flags:
-h, --help Show context-sensitive help.
-v, --version Print the version number
Commands:
choose Choose an option from a list of choices
confirm Ask a user to confirm an action
file Pick a file from a folder
filter Filter items from a list
format Format a string using a template
input Prompt for some input
join Join text vertically or horizontally
pager Scroll through a file
spin Display spinner while running a command
style Apply coloring, borders, spacing to text
table Render a table of data
write Prompt for long-form text
Run "gum <command> --help" for more information on a command.З усього переліку нам знадобляться наступні інструменти:
choose - для вибору дії в головному меню та обрання статті з переліку знайдених;
input - для можливості вводу слів для пошуку;
spin - для інформування користувача про таймаут під час завантаження результатів запитів.
Тепер можна перейти до написання самого скрипту. Іноді доводиться гуглити дуже прості речі, і одним з перших джерел інформації є Вікіпедія. Тому напишемо просту програму, яка дозволить шукати статті та вибирати з результатів пошуку ту, яка найбільше відповідає запиту.
Головне меню буде складатися з трьох пунктів: пошуку, вибору мови пошуку та видалення результатів пошуку. Створимо функцію "main", яка надаватиме доступ до всього функціоналу:
#!/usr/bin/env bash
# мова пошуку за замовчуванням - англійська
LANGUAGE="en"
main() {
options=( "Search" "Language" "Clean" )
echo "Select one option or press Ctrl+C to exit"
while true;
do
# gum створить меню з вибором опцій
# case дозволить обробляти вибір і
# завершувати роботу скрипту скрипту після
# виклику SIGINT сигналу
option=$(gum choose ${options[*]})
case $option in
"Search")
$(search)
;;
"Language")
change_language
;;
"Clean")
clean
;;
*)
exit 0
;;
esac
done
}
# викличемо функцію
main[pc@pc:~/Code/bash]$ chmod +x wikiread.sh
[pc@pc:~/Code/bash]$ ./wikiread.sh
Select one option or press Ctrl+C to exit
> Search
Language
CleanПереходимо до створення функцій. Почнемо з кінця, бо це найлегше. Ми будемо зберігати статті в папці ~/Documents/wikiread/. При запуску скрипту перевіримо, чи існує така папка. Якщо ні, то створимо її. Функція "clean" буде призначена для видалення всіх PDF-файлів з цієї папки.
...
# запишемо шлях до змінної
DOCPATH="$HOME/Documents/wikiread/"
main() {
# перевіримо чи існує папка, якщо ні, то створимо її
[ -d $DOCPATH ] && echo "Directory $DOCPATH exists" || mkdir $DOCPATH
...
clean() {
rm $DOCPATH/*.pdf 2>/dev/null
}Проткстуємо скрипт:
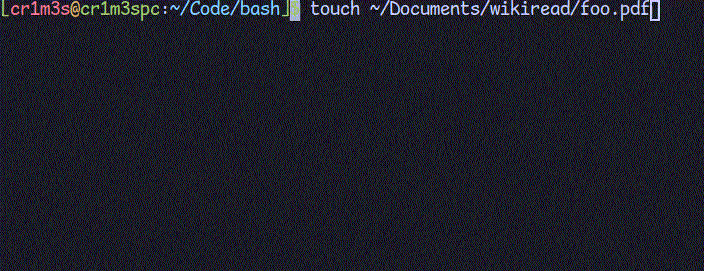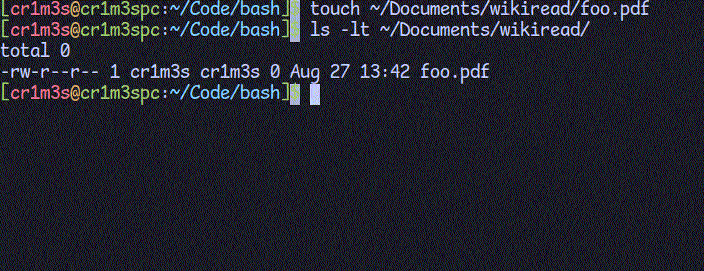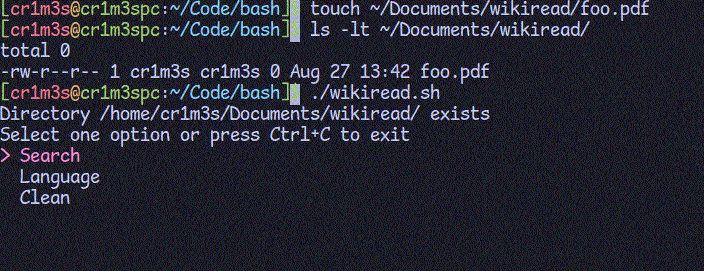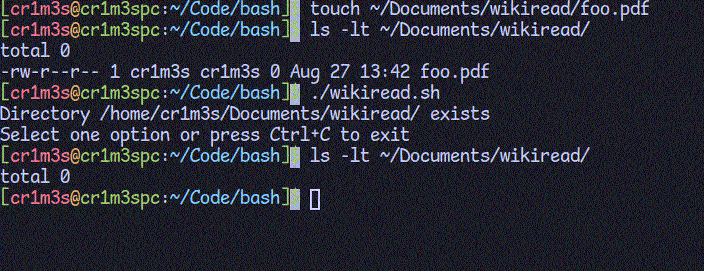
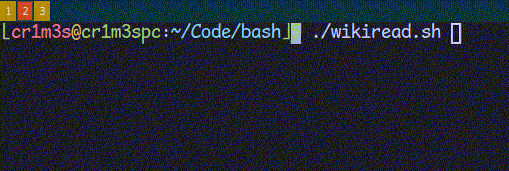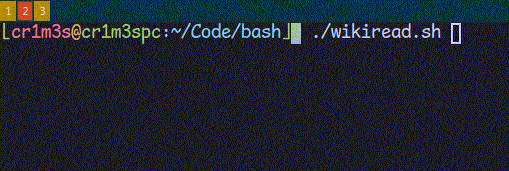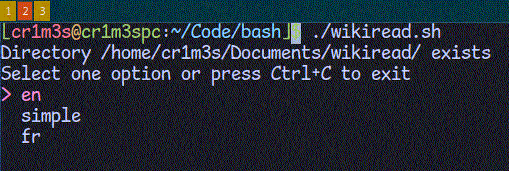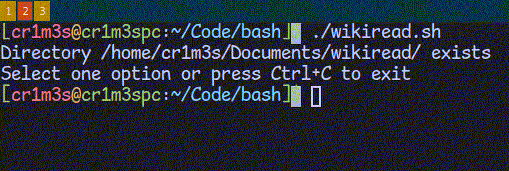
Додамо можливість вибору мови пошуку. Поки що підтримаємо лише мови, що використовують латинський алфавіт, оскільки Вікіпедія в своєму API підтримує стандарт rfc3986, який використовує додаткове кодування для літер кириличного алфавіту.
change_language() {
# додамо спрощену англійську і французьку
languages=( "en" "simple" "fr")
# перевизначимо глобальну змінну
LANGUAGE=$(gum choose ${languages[*]})
}
Переходимо до найскладнішої частини - пошуку і завантаження статтей. Для пошуку будемо використовувати opeansearch API. Приклад запиту:
https://en.wikipedia.org/w/api.php?action=opensearch&format=json&search=pageВ запиті ми можемо визначити мову, і заголовок того, що ми шукаємо. Використаємо curl для створення запиту і jq для форматування json результату запиту.
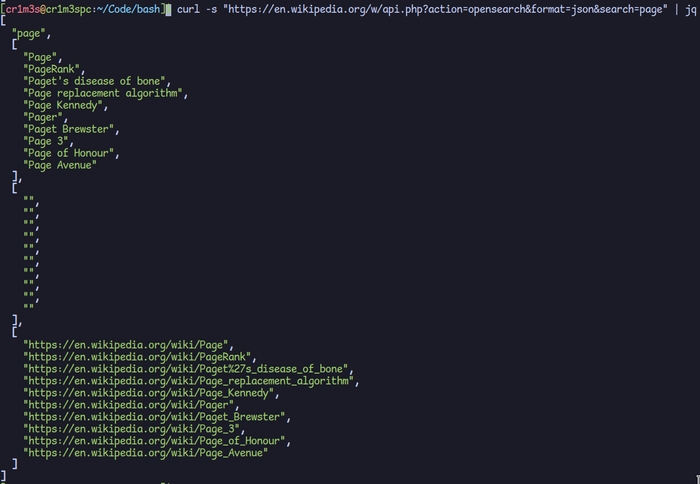
Після виконання запиту ми отримали JSON з переліком заголовків та посиланнями на статті. Однак, нас цікавлять тільки посилання, оскільки ми будемо використовувати їх для створення запитів на завантаження статті. Для цього ми можемо використовувати Wikimedia REST API.
Ми будемо завантажувати статті в форматі PDF та зберігати їх локально у раніше створеній папці ~/Documents/wikiread. Після цього ми будемо здійснювати читання статей за допомогою PDF-читалки zathura, яка є досить легкою та швидкою.
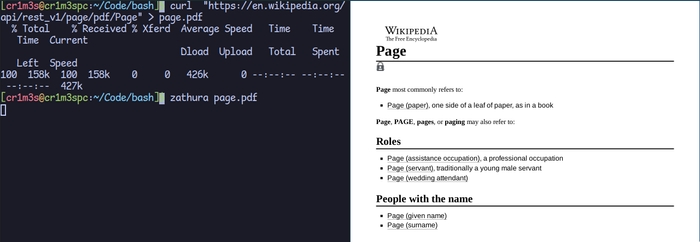
Отже ми готові до створення функції search:
search() {
while true;
# безкінечний цикл дозволить користувачу перебувати в меню пошуку
do
# використаємо gum input для форматованого вводу
title=$(gum input --placeholder "Enter wiki page name or Ctrl+C to exit")
# якщо користувач посилає сигнал натискаючи комбінацію клавіш CTRl+C
# покидаємо функцію і повертаємось до меню
if [ $? -ne 0 ]; then
exit 0
fi
# безпосередньо пошук, в результаті отримаємо JSON об'єкт
# використаємо gum spin для інтерактивності
search=$(gum spin --title "looking for ${title}" --show-output -- curl -s "https://${LANGUAGE}.wikipedia.org/w/api.php?action=opensearch&format=json&search=${title}" | jq -r )
# створимо пустий список в якому будемо зберігати заголовки статей
# котрі будемо використовувати в подальшому
declare -a links=()
for item in ${search[*]}; do
# оберемо рядки котрі є посиланнями
# всі посилання мають стандартний формат:
# https://en.wikipedia.org/wiki/link
# тому ми можемо досить просто за допомогою cut
# виокремити заголовок
tmp=$(echo ${item} | grep "https" | cut -d "/" -f 5 | tr -d "," | tr -d "\"")
links+=(${tmp})
done
# якщо пошуковий запит не мав в собі посиланнь
# це означає, що нічого не було знайдено
if [ ${#links[@]} -gt 0 ]; then
page=$(gum choose ${links[*]})
# завантажимо статтю і збережемо локально
gum spin --title "loading $page page" --show-output -- curl -s "https://${LANGUAGE}.wikipedia.org/api/rest_v1/page/pdf/${page}" > ~/Documents/wiki/${page}.pdf
# відкриємо завантажений файл у фоновому режимі
zathura ~/Documents/wiki/${page}.pdf &
else
echo "Nothing was found"
fi
done
}
Протестуємо скрипт:

Тепер, завдяки інструменту gum, ми можемо читати статті з Вікіпедії, не відкриваючи браузер, використовуючи досить зручний інтерфейс. В подальшому можна додати обробку кириличного тексту. Весь код можна знайти за посиланням.
