
На початку роботи із клієнтом досвідчені райтери ставлять багато питань. Ці питання стосуються організації процесу, специфіки бізнесу замовника і вимог до текстів. Чи не найскладніше реалізувати саме вимоги до стилю.
Будь-який автор, що працює у сфері копірайтингу, SEO-копірайтингу, написання блогових статей та PR-текстів, напевно чув фрази на зразок “мені подобається стиль на сайті компанії A та компанії B, напишіть, як у них”. Багато хто робив спроби впровадити бріф чи просто у вільній формі опитати клієнта, виявивши, що саме йому подобається. Погана новина в тому, що це не спрацює. Хороша новина в тому, що альтернатива є. Але спочатку треба розібратись, в чому проблема роботи зі стилем текстів та налаштуванням tone of voice бренду.
Чому описати та виміряти стиль складно
Одразу скажемо, ця стаття написана не для того, щоб у чомусь звинуватити підприємців. Описати стиль тексту та відтворити його надалі дійсно непросто, навіть для професіонала, який довго працює в цій сфері. Чому?
По-перше, стиль досить важко визначити. Плутанина може бути вже в тому, чи йдеться про стиль тексту (як науковий, художній чи інший), чи про манеру письма автора.
По-друге, різниця між tone of voice та стилем автора не очевидна навіть для професіоналів.
По-третє, досить непросто розкласти стиль на стандартний набір параметрів, таких як вживання тих чи інших слів, довжина речень, емоційне забарвлення, сленгові фрази, наукова лексика і т. д.
Як з усім цим бути? Як зрозуміти основні параметри стилю, що подобається клієнту і відтворити їх далі.
Як описати стиль з допомогою інструментів ШІ
ШІ змінив дуже багато в сфері контент-маркетингу. Одразу після появи в широкому доступі генеративних ШІ, таких як Chat GPT чи Claude, багатьом здавалось, що ці інструменти така собі чарівна паличка. Але не достатньо ввести короткий запит, щоб отримати якісну статтю, що регулярно приноситиме трафік.
Насправді ж штучний інтелект у більшості випадків буде корисний у стратегічних та допоміжних задачах. Використання LLM (large language models) для аналізу великих обсягів текстів просто за визначенням має давати круті результати.
Отже, як це зробити копірайтеру?
Для цього потрібно кілька речей:
Акаунт в Claude (достатньо безкоштовного) або Chat GPT (потрібен тариф PRO);
Один або декілька текстів, які замовник визначив як приклад і референс;
Правильно складений промт (запит).
Ми розберемо ідею на прикладі кількох текстів і їх аналізу в Chat GPT.
Крок 1. Завантажуємо тексти
Завантажте всі тексти, стиль яких має слугувати прикладом. Це може бути один файл чи кілька.
Крок 2. Пишемо запит
Далі детально описуємо, що ми хочемо отримати від Chat GPT в результаті аналізу завантажених текстів.
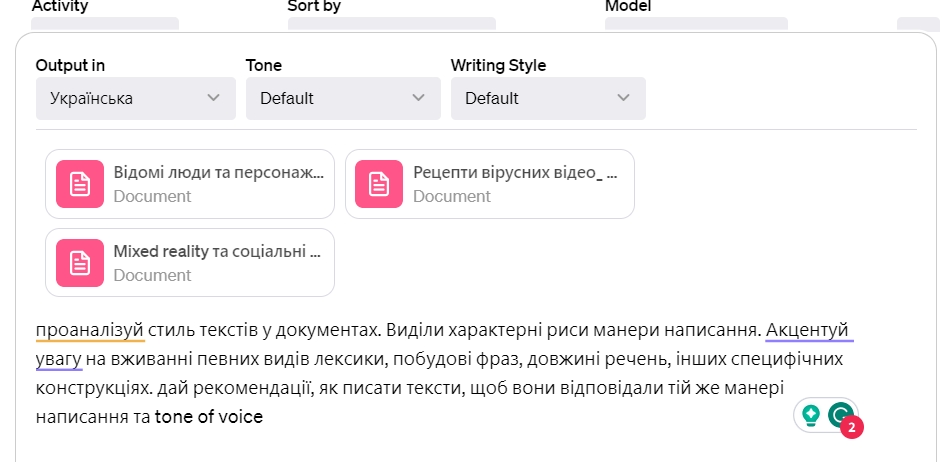
І просто відправляємо запит до ШІ на обробку.
Крок 3. Отримуємо опис стилю та рекомендації з написання схожих текстів

Тут ми бачимо змістовні, але все ще досить загальні відповіді та поради. Тому є сенс поставити кілька уточнюючих питань.
Крок 4. Аналізуємо поглиблено
Залишаючись в тому ж чаті, ми можемо поставити ще скільки завгодно питань для стилістичного та статистичного аналізу текстів.
Наприклад, попросимо порахувати, які слова найчастіше зустрічаються в текстах. При цьому можна уточнити, що потрібні лише значущі слова або треба враховувати всі.

Дуже ймовірно, що ми не зможемо інтерпретувати цю статистику. Тому поставимо наступне питання: який відсоток значущих слів та слів-зв’язок у текстах (чи тексті).

З відповіді ми також дізнаємось, що це означає в плані сприйняття тексту.

Щоб краще оцінити, наскільки тексти зрозумілі, попросимо ШІ підрахувати Fog index (індекс туманності)
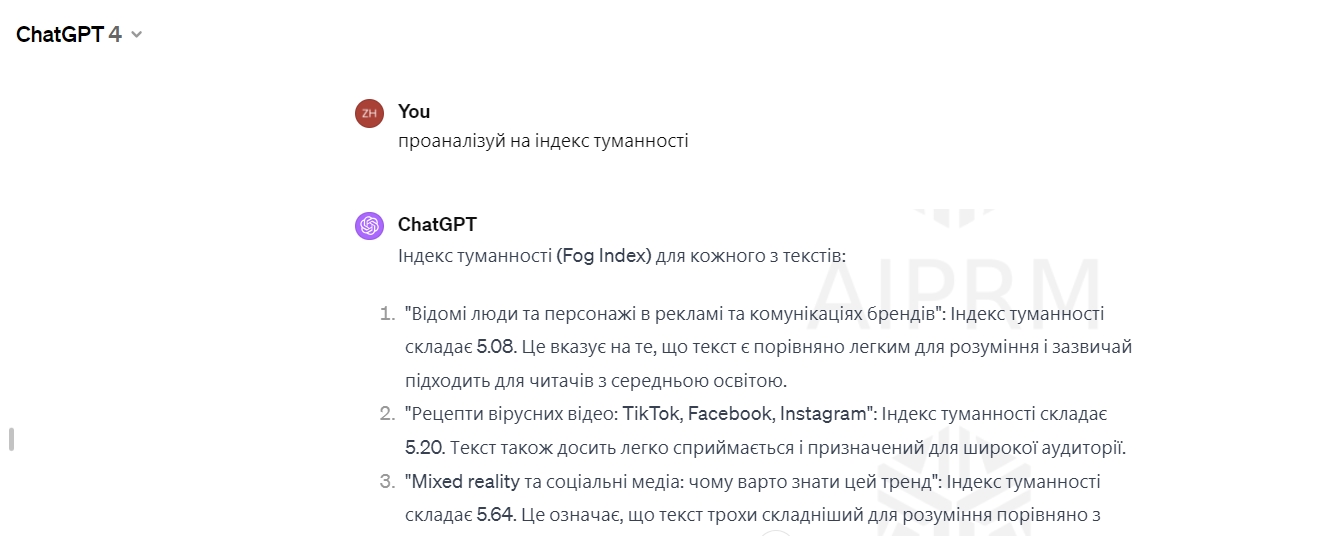
Індекс туманності тексту — це показник для аналізу контенту, що дозволяє об’єктивно виміряти складність тексту та його відповідність рівневі цільової аудиторії. Цей параметр показує, які категорії людей можуть зрозуміти написане.
Індекс туманності обчислюється за наступною формулою:
0.4×(Середня довжина речення + Відсоток складних слів), де:
Середня довжина речення — це загальна кількість слів у тексті, поділена на кількість речень.
Відсоток складних слів — це частка слів у тексті, що містять три склади чи більше, від загальної кількості слів.
Чим вищий індекс туманності, тим складніший текст для розуміння. Індекс туманності часто використовується у видавництвах, журналістиці та освіті для адаптації текстів під різні рівні читачів.
Як інтерпретувати показники індексу туманності?
Індекс туманності | Інтерпретація | Цільова аудиторія |
|---|---|---|
1-5 | Дуже легкий для розуміння | Молодші школярі |
6-8 | Легкий для розуміння | Старші школярі / Підлітки |
9-12 | Трохи складний для розуміння | Дорослі з середньою освітою |
13-15 | Складний для розуміння | Фахівці / Вища освіта |
16+ | Дуже складний для розуміння | Дослідники / Академіки |
Підрахувати індекс туманності власних текстів ви можете в безкоштовних сервісах або тому ж Chat GPT чи Claude.
На завершення
Ми розібрали лише приклади того, яку статистичну та аналітичну інформацію про тексти може дати ChatGPT. Ви можете використати ці питання або обрати інші, формуючи власний підхід. Чи потрібно так робити щоразу із кожним проєктом? Вирішувати лише вам.
Ми ж вважаємо, що такий глибокий аналіз виправданий лише якщо йдеться про великий проєкт з серйозним бюджетом. І, звісно ж, чим більший обсяг текстів референсів, тим більше інформації ви отримаєте.
А якщо вам потрібна контент-стратегія чи загалом матеріали на складні теми зрозумілою мовою, звертайтесь. Пишіть за контактами, що вказані в профілі.
