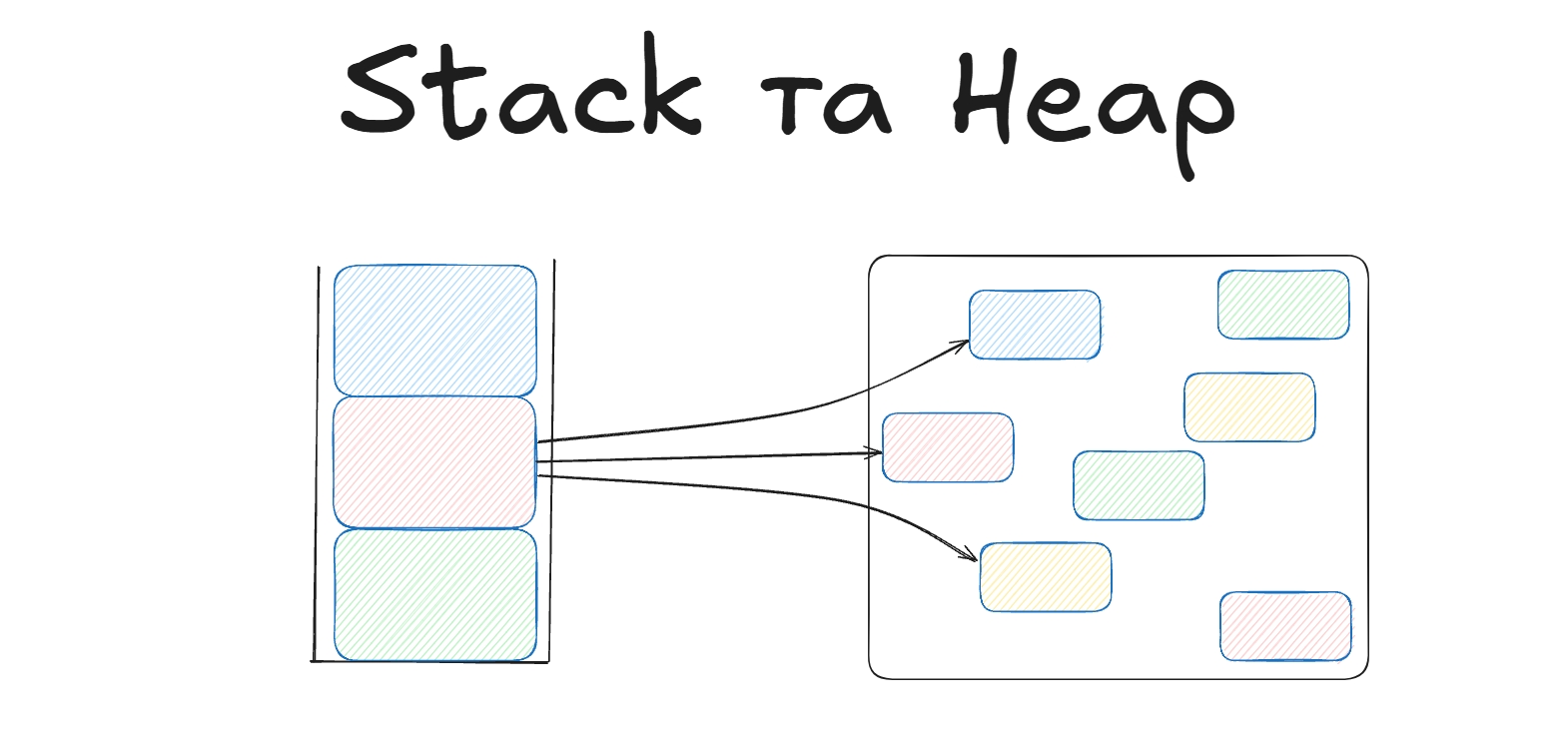
В JVM використовуються дві структури для зберігання інформації в пам’яті: Stack та Heap. Вони мають полярну філософію і ми не можемо обійтись без жодної із них. У цьому пості я намагатимусь обширно опрацювати причини використання обох структур та їхні особливості.
Історія
Пам’ятаєте, як виглядає викидання ексепшина в джаві? Назва ексепшина та довга кишка методів під ним.
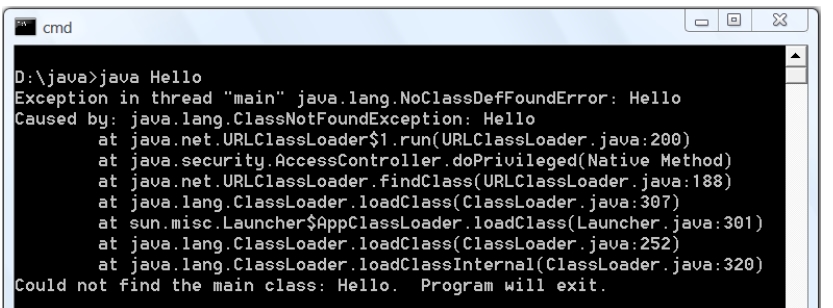
Так ось, довга кишка методів під ним називається stacktrace і вона описує історію виклику методів, які привели до виникнення цього ексепшину.
Якраз таки все і почалось з функцій, а саме з рекурсивних викликів, які вимагали механізму зберігання інформації про контекст кожної функції, включаючи її параметри, локальні змінні та адреси повернення. Основна ідея використання stack у пам’яті — це принцип "останнім прийшов — першим пішов" (LIFO, Last In, First Out), що дозволяє організувати виклики та повернення функцій за порядком.
З середини 1960-х років мови програмування, такі як ALGOL та пізніше C, активно застосовували stack для підтримки викликів функцій і управління локальними змінними. Саме в цей час розробники зіштовхнулися з проблемою ефективного управління пам’яттю, і stack став стандартним рішенням для автоматичного зберігання короткотривалих даних, які зникають після завершення функцій.
Stack зберігає порядок і працює швидко, що ідеально для зберігання інформації про функції.
Що робити, якщо нам необхідно зберегти дані з першого вилику функцій і передати їх наступному виклику функцій? Наприклад прочитати інформацію про користувача, а потім передати її в постпроцесор? Stack не підійде, адже якщо в ньому зберігати проміжні дані, то щоб отримати доступ до них, доведеться послідовно перебирати весь стек, доки ми не дійдемо до потрібних даних.
Саме через цю сувору послідовність читання stack недоцільно використовувати для управління пам’яттю, коли програми потребують виділення та звільнення пам’яті під час виконання. Так і був придуманий Heap. Кожен раз, коли програма виділяє пам'ять для об'єкта, вона робить це в heap, що дозволяє гнучко керувати пам'яттю для більш довготривалих даних.
Heap масивний, тому вимагає розумних алгоритмів, щоб з ним працювати. Управління купою спиралося на теорії і алгоритми, розроблені в середині 1960-х років. Одним з піонерів у цій області був Роберт Флойд, який разом з колегами розробляв ранні методи розподілу пам’яті та алгоритми для автоматичного керування купою (Heap Sort, "Флойдове" будування купи). Ці алгоритми базувалися на ідеї зберігання пам'яті, яка може бути розподілена і звільнена в будь-якому порядку, що робило купу ідеальною для структур, які можуть змінюватися динамічно
Мова програмування Lisp, розроблена в кінці 1950-х років, показала важливість динамічної пам'яті. Lisp активно використовувала структури списків, які вимагали виділення та звільнення пам'яті для нових елементів. Це призвело до створення механізмів збирання сміття (garbage collection), які автоматично звільняли невикористану пам'ять у купі. З часом це дало змогу розвиватися більш складним моделям керування пам’яттю в мовах високого рівня, таких як наша улюблена Java і наш особливий Python.
Для ефективної роботи з великою купою використовуються кілька методів: гарбедж-колектори (як-от "mark-and-sweep" та Generational GC) автоматично звільняють пам'ять, знижуючи ризик витоків пам’яті; спеціалізовані структури, як binomial heaps та fibonacci heaps, оптимізують доступ до мінімальних чи максимальних елементів; arena allocation та пули пам'яті мінімізують фрагментацію та пришвидшують виділення пам’яті; а методи coalescing і compacting дозволяють уникнути фрагментації, підтримуючи великі блоки пам'яті для нових об'єктів.
Сучасні мови програмування, такі як C, C++, Java, та Python, розділяють пам'ять на stack і heap, щоб ефективно обробляти різні види даних. Стек використовується для зберігання короткотривалих змінних, а heap — для динамічних даних. Операційні системи також підтримують ці розділи, що дозволяє оптимізувати роботу програм.
З розвитком сучасних комп’ютерів, архітектура пам’яті також стала більш складною, але stack і heap залишаються основними концепціями. Stack залишається структурою для короткотривалих даних, зберігаючи фрейми функцій, тоді як heap використовується для динамічних, довгоіснуючих об’єктів, що створюються під час виконання програми.
Stack
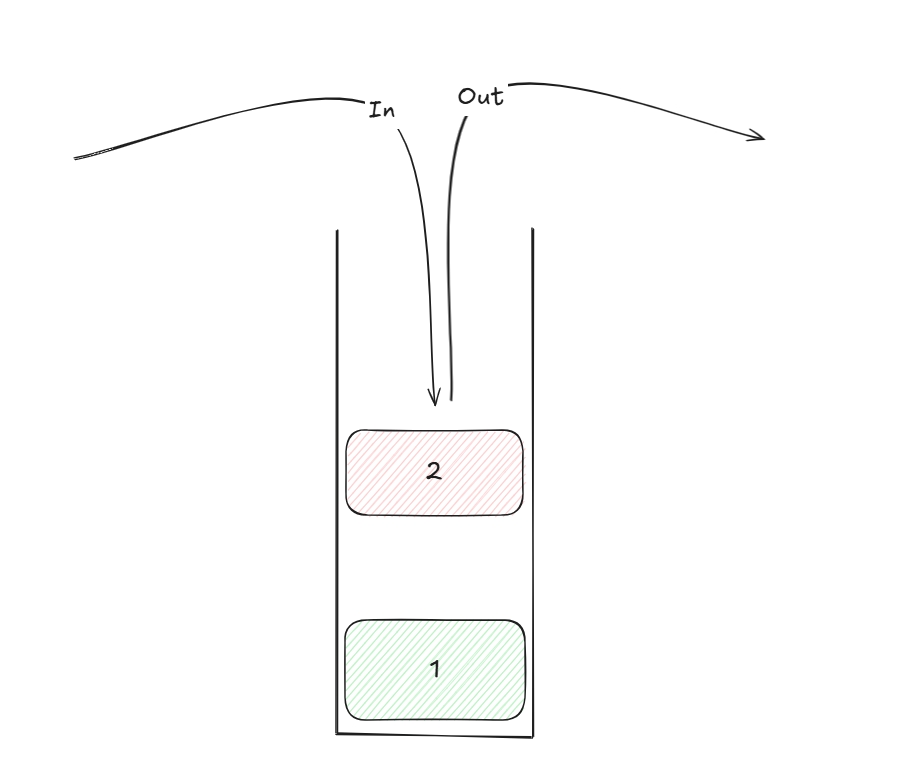
Найпопулярніше пояснення FIFO та структури stack це колода карт, карти кладуться одна на одну, а тягнуться спочатку ті карти, які зверху.
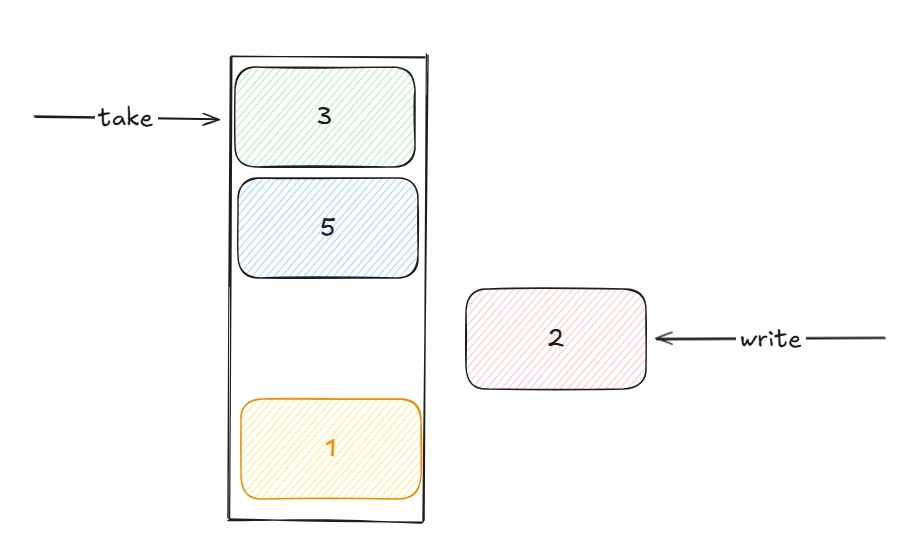
Stack простий, не має доступу до елементів за адресою, але компенсує це швидкістю доступу. Ідеальний для зберігання інформації про функції за чергою їхнього виклику. Складається з stackframes, кожен фрейм існує поки виконується відповідна йому функція. Коли фреймів стає надто багато, то вилітає java.lang.StackOverFlowError .
Коли створюється новий потік, JVM виділяє окрему область пам'яті для його стеку, таким чином ця пам’ять є потокобезпечною, оскільки кожен потік працює у власному стеку.
В джаві stack зберігає примітиви і посилання на об’єкти, а самі об’єкти зберігаються в heap
Stack напряму асоціюється з однопотоковим виконанням функцій та локальними змінними, але варто зазначити, що примітиви типу int. char і тд, якщо вони об’явлені як поля класу - будуть зберігатись в heap. а якщо як звичайні змінні в контексті методу, то в Stack. Також масиви зберігаються у Heap.
class A {
int someNum;
A(int someNum) {...}
}
public void example() {
int a = 4; // Stack пам'ять
A refer = new (5) // Посилання refer збережеться в Stack, а сам об'єкт, як і
// someNum 5 збережеться в Heap
int[] arr = new int[]{1, 2, 3} // Посилання arr в Stack, а масив у Heap
}Stack обмежений розміром, який задається JVM. Наприклад, якщо в програмі виникає дуже глибока рекурсія або якщо stack використовує великі об'єкти (наприклад, великі масиви), це може призвести до stack overflow error. На відміну від цього, heap має більший розмір і здатен зберігати більші об'єкти, але його управління здійснюється через механізми збору сміття.
У деяких мовах (хоча Java не підтримує автоматичну оптимізацію хвостової рекурсії) існує оптимізація хвостової рекурсії (Tail Recursion Optimization), коли рекурсивні виклики замінюються на ітерації, щоб уникнути зайвих записів в стек. Ця оптимізація дозволяє запобігти переповненню стеку при глибокій рекурсії.
Heap
У heap зберігається багато об'єктів, для яких пам’ять виділяється динамічно. Heap є спільною областю пам'яті для всіх потоків програми, що означає, що об'єкти, створені одним потоком, можуть бути доступні іншим потокам. Heap як структура даних і heap як модель пам’яті це зовсім різні речі. Також в heap, окрім об’єктів, зберігаються масиви.
Сегменти
Об’єкти мають різний життєвий цикл, деякі живуть більше, деякі довше. Короткоживучих об’єктів є зазвичай більше, вони створюються і перестають бути потрібними в контекстах методів, стрімів і тд. Через їх кількість їх GC повинен перевіряти частіше. Виходячи з необхідності ефективної роботи Garbage Collector (GC) Heap розбили на сегменти.
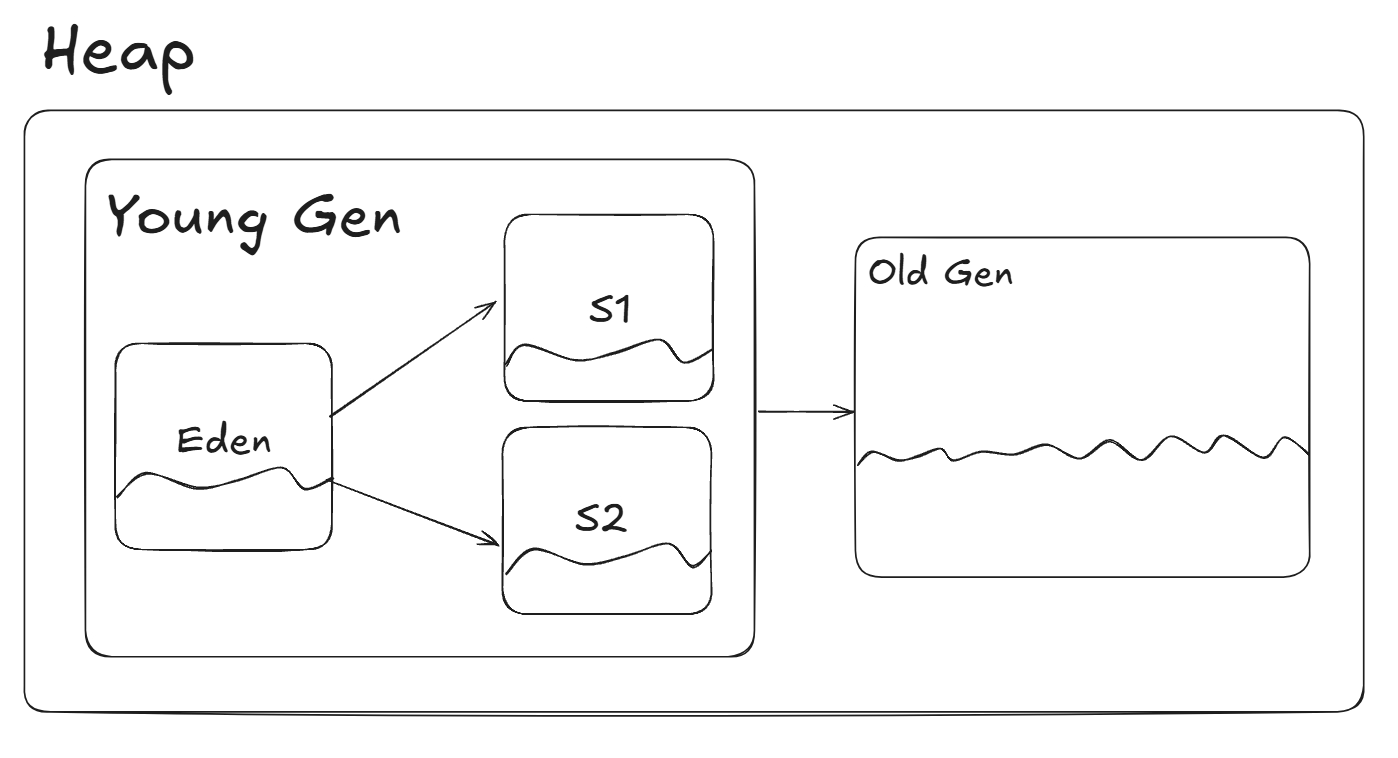
Heap розділений на дві основні зони: Young Generation та Old Generation.
В свою чергу Young Generation розділений на Eden, Survivor 1 та Survivor 2.
Новостворені об’єкти приходять у Eden, після того, як вони переживають GC вони усі потрапляють або в S1 або в S2. Після кожного GC циклу Eden space залишається пустим і в ньому знову виділяється пам’ять під нові об’єкти.
S1 та S2 виконують роль "фільтра", який визначає, які об’єкти мають шанс на довгострокове зберігання. Кожен цикл об'єкти переміщуються між S1 та S2. Усі живі об'єкти копіюються з одного простору в інший, залишаючи вихідний простір повністю вільним. Це дозволяє Garbage Collector виділяти компактний блок пам'яті лише для живих об'єктів, щоб зайвий раз не проходитись по одному з S просторів і швидко визначати, які об’єкти довгоживучі.
Вже після Survivor spaces, об’єкти доходять до Old Genertion (Tenured)
Eden Space і Survivor Spaces в HotSpot JVM завжди використовують масиви як основну структуру для організації пам’яті, забезпечуючи ефективне послідовне розташування об’єктів. У GraalVM, починаючи з Java 11, у Survivor Spaces завжди використовуються списки, коли обсяг живих об'єктів у Young Generation варіюється значно між циклами GC — це зменшує накладні витрати при високій фрагментації. У OpenJ9 завжди застосовуються масиви для Eden Space і Survivor Spaces, подібно до HotSpot, для стабільності та швидкості доступу.
Для Old Generation HotSpot JVM (Java 6+) завжди використовує сегментовані регіони, які зберігають великі об’єкти. ZGC (Java 11+) завжди організовує регіони з метаданими, що дозволяє підтримувати низькі паузи збору сміття, а Shenandoah (Java 12+) завжди базується на регіональному підході з додатковим фокусом на скорочення часу фрагментації через фонову компактизацію.
У G1 GC для прискорення збору сміття в Old Generation застосовується дерево пошуку, яке індексує об'єкти, що знаходяться в різних регіонах пам'яті. Коли відбувається збір сміття, дерево дозволяє швидко визначити, які об'єкти є живими, а які можна звільнити, значно зменшуючи час на пошук і перевірку. Але дерева не використовується як частина хіпа.
Сегмент | Призначення | GC Операції | Частота GC |
|---|---|---|---|
Eden Space | Зберігає новостворені об'єкти. | Minor GC переміщує живі об'єкти в Survivor Space (S1 або S2), а решта очищується. | Дуже часто |
Survivor Space 1 (S1) | Проміжна зона для об'єктів, які пережили перший цикл GC. | Живі об'єкти копіюються в S2 або, якщо вони "старі", у Old Generation. | Часто |
Survivor Space 2 (S2) | Альтернативна проміжна зона для чергування з S1. | Живі об'єкти копіюються назад у S1 або в Old Generation, залежно від їхнього віку. | Часто |
Old Generation | Зберігає "довгоживучі" об'єкти, які пережили кілька циклів Minor GC. | Major GC очищує об'єкти, що більше не використовуються. | Рідше |
У Java був сегмент Permanent Generation (або PermGen) у старих версіях JVM (до Java 8). У ньому зберігалась метаінформація про класи, методи і тд. PermGen не чистився GC та мав статичний розмір, тому на його зміну прийшов Metaspace, він більше не знаходився в heap, мав динамічний розмір який можна було налаштовувати і почав очищуватись GC.
Об'єкти у Java часто мають складні зв'язки (асоціації, композиції, агрегації), щоб пошук мертвих об’єктів був ще швидшим, можна скористатись зв’язками. Граф об'єктів відображає ці зв'язки в пам'яті, вузли це об’єкти, а ребра це посилання, що полегшує пошук мертвих (недосяжних) об’єктів для GC.
Процес виявлення мертвих об'єктів у Java починається з кореневих точок доступу (GC Roots), від яких JVM перевіряє досяжність об'єктів. Якщо об'єкт не має шляху до кореневих точок, він вважається недосяжним (мертвим). Коли об'єкт A виявляється мертвим, усі об'єкти, доступні тільки через нього (як його дочірні об'єкти), також вважаються мертвими, і збирач сміття позначає їх для видалення. Це дозволяє автоматично звільняти пам'ять, позбавляючи програму об'єктів, які більше не використовуються, зберігаючи ефективність процесу збору сміття.
Можливо ви колись зустрічались з термінами off-heap та on-heap memory. On-heap пам'ять — це пам'ять, яка знаходиться під управлінням GC. Вона використовується для об'єктів, які створюються під час виконання програми. Off-heap пам'ять, на відміну від цього, не управляється збирачем сміття, і доступ до неї зазвичай здійснюється через спеціальні API, ця пам’ять це те, що ззовні JVM.
Типи посилань
Хоч об’єкти і зберігаються в heap, посилання на них зберігаються в stack. У Java є чотири типи посилань:
Сильні посилання (Strong References): Це звичайні посилання, які ми використовуємо для об'єктів. Поки існує сильне посилання на об'єкт, збирач сміття не може його видалити. Об'єкт залишатиметься в пам'яті, поки посилання на нього не буде знищене.
Object obj = new Object(); М'які посилання (Soft References): М'які посилання дозволяють збирачу сміття видаляти об'єкти тільки тоді, коли пам'яті не вистачає. Це корисно для кешування, оскільки об'єкти можуть зберігатися в пам'яті, поки її достатньо, а видалятися тільки за потреби.
SoftReference<Object> softRef = new SoftReference<>(new Object());Слабкі посилання (Weak References): Слабкі посилання дозволяють збирачу сміття видаляти об'єкти, як тільки на них не залишиться сильних або м'яких посилань, навіть якщо пам'яті достатньо. Це часто використовується для автоматичного видалення елементів із колекцій, коли об'єкти більше не використовуються.
WeakReference<Object> weakRef = new WeakReference<>(new Object());Загалом використання будь-який окрім сильних посилань це велика рідкість. Слабкі та м’які посилання можуть бути корисними у написанні систем де стабільність системи більш важлива за контроль над даними.
Фантомні посилання (Phantom References): Фантомні посилання з'являються, коли об'єкт уже був видалений з пам'яті. Вони використовуються для визначення часу очищення об'єкта та виконання додаткових дій після того, як об'єкт було видалено.
PhantomReference<Object> phantomRef = new PhantomReference<>(new Object(), referenceQueue);
Пули об’єктів
Пули об'єктів в Java створюються в основному heap, оскільки це область пам'яті, де зберігаються об'єкти. Пул об'єктів — це спеціалізована структура даних, яка дозволяє повторно використовувати об'єкти замість їхнього постійного створення та знищення, тим самим зменшуючи навантаження на збирач сміття та покращуючи продуктивність програми.
Назва пулу | Що зберігається |
|---|---|
String Pool | Рядки-літерали ( |
Integer Pool | Кешовані об'єкти-обгортки чисел ( |
Thread Local Pool | Локальні об'єкти для кожного потоку (через |
SoftReference Pool | Об'єкти, які можуть залишатися в пам'яті до нестачі ресурсів |
WeakReference Pool | Об'єкти, доступні для збору сміття після чергового GC |
Custom Object Pools | Об'єкти в реалізованих вручну пулах (наприклад, |
Налаштування Heap
Параметр | Опис | Рекомендації щодо використання |
|---|---|---|
-Xms | Встановлює початковий розмір heap-пам’яті | Використовуйте, щоб уникнути частих збільшень heap на старті, особливо для великих додатків |
-Xmx | Встановлює максимальний розмір heap-пам’яті | Задавайте, щоб уникнути OutOfMemoryError; зазвичай дорівнює або менше доступної фізичної пам’яті |
-Xmn | Визначає розмір Young Generation (молодого покоління) | Збільшуйте, якщо ваш додаток часто створює короткоживучі об'єкти |
-XX:NewRatio | Задає співвідношення розмірів Old і Young Generation | Корисно для балансування між молодим і старим поколіннями залежно від типу навантаження |
-XX:SurvivorRatio | Визначає співвідношення розмірів Eden і Survivor областей в Young Generation | Налаштовуйте для оптимізації роботи з короткоживучими об'єктами |
-XX:HeapDumpOnOutOfMemoryError | Включає створення heap dump у разі OutOfMemoryError. | Дуже корисно для налагодження проблем з пам’яттю |
Порівняння
Параметр | Стек | Хіп |
|---|---|---|
Застосування | Стек використовується частинами, одна за одною під час виконання потоку | Уся програма використовує пам'ять хіпа під час виконання |
Розмір | Стек має обмеження розміру залежно від ОС і зазвичай менший за хіп | Хіп не має обмежень розміру |
Зберігання | Зберігає тільки примітивні змінні та посилання на об'єкти, які створюються в хіпі | Усі створені об'єкти, масиви, зберігаються тут |
Порядок доступ | Доступ до пам'яті здійснюється за принципом Last-in First-out (LIFO) | Складний механізм, який використовує сегменти та граф об’єктів |
Тривалість | Пам'ять стека існує лише під час виконання поточної методи | Існує поки програма працює |
Ефективність | Швидше розподіляється в порівнянні з хіпом | Повліьніше розподіляється в порівнянні з стеком |
Алокація/Деалокація | Ця пам'ять автоматично алокуються та деалокуються при виклику та поверненні методу відповідно | Алокуються, коли створюються нові об'єкти, і деалокуються збирачем сміття, коли на них більше не є посилань |
Джерела
https://dou.ua/forums/topic/49062/ “Як влаштована робота з памʼяттю в Java“ Valentyn Vivcharyk
https://www.baeldung.com/java-stack-heap Stack Memory and Heap Space in Java. Baeldung
https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-2.html Chapter 2. The Structure of the Java Virtual Machine. Oracle
