Проблема у проектуванні бази даних з’являється тоді, коли нам треба працювати більше ніж з одним клієнтом. Цей другий клієнт абсолютно непередбачуваний, він може читати дані поки перший клієнт їх записує, модифікувати поки перший читає, або записувати різні дані разом із першим. Основна ідея багатопотоковості: Пекло це інші.

Транзакція
Транзація це логічна одиниця, яка містить набір команд для читання і записування даних. Концептуально, усі команди у транзакції повинні виконуватись атомарно, виходячи з цього є два наслідки виконання транзакції:
Успішне (commit)
Неуспішне (rollback/abort)
Транзакція дозволяє залишити дані в базі узгодженими, якщо транзакція змінила 10 полів, а мала змінити 20, то всі зміни просто відкотяться.
Для того, щоб дані не втратились продюсер повинен імплементувати необхідні дії при невдалій транзакції. @Transactional наприклад буферизує дані на стороні продюсера поки виконується транзакція, що дозволяє продюсеру отримати доступ до даних, коли транзакція виконує ролбек.
Race conditions
Race conditions виникають, коли дві або більше транзакції намагаються одночасно змінити, або отримати доступ до спільних ресурсів, і кінцевий результат залежить від порядку виконання цих операцій. Якщо race conditions трапляються у вашій БД, то це швидше за все через некоректну ізоляцію транзакцій, або її повну відсутність.
Dirty Read
Уявіть ситуацію, перша транзакція у процесі записування даних у БД, але ця транзакція ще не завершилась. Якщо друга транзакція бачить анкомітед дані першої транзакції, то це брудне читання.
Наслідком брудного читання є неузгодженість даних, коли перша транзакція виконує ролбек: Перша транзакція відкотить свої зміни, друга прочитає зміни, які не будуть відповідати стану БД, тобто дані не будуть узгодженими.
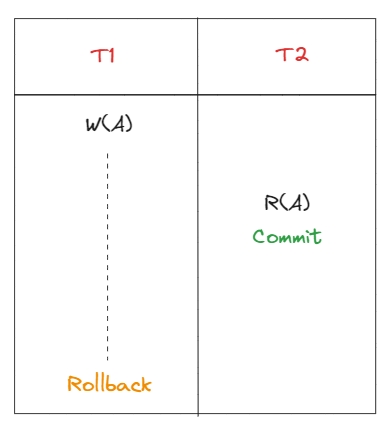
Також, якщо T1 захоче оновити декілька об’єктів, то T2 можливо побачить лише частину оновлень.
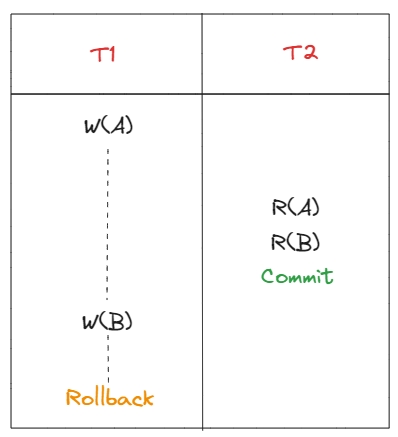
Також dirty read називають write–read conflict, або reading uncommitted data
Non-Repeatable Read
Не повторюване читання також називають read skew, виникає, коли між двома читаннями T1 існує запис T2, що у наслідку може повернути різні значення для кожного читання T1.
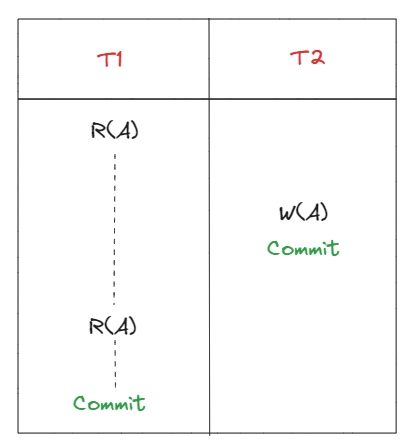
Non-Repeatable Read може призвести до серйозних проблем у базах даних, особливо в системах, де цілісність даних є критичною. Наприклад запит, який для обчислення на різних етапах читає дані з A:
C = R(A) - R(B)
R(A) / C
Виконання цього запиту важко буде передбачити, якщо рівень ізоляції не запобігає Non-Repeatable Read.
Dirty write
Брудний запис трапляється, коли транзакції одночасно змінюють одні й ті самі дані, внаслідок чого дані, записані однією з транзакцій, перезаписуються іншою.
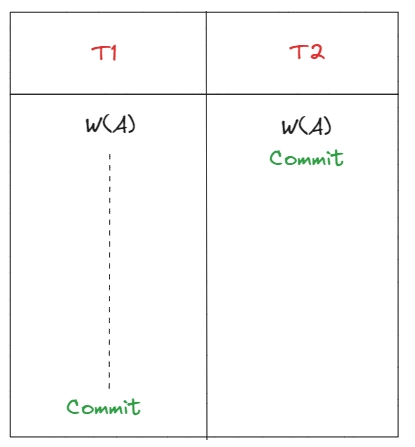
Write skew
Зсув запису трапляється, коли транзакції читають спільні дані, потім здійснюють зміни на основі прочитаних даних і записують свої результати, в наслідку таблиця містить мікс змін обох транзакцій. Це стає проблемою, коли існують логічні умови для модифікації даних.
Спрощений приклад з книги Клепмана: Два лікарі стоять на on-call, обом стало зле і вони хочуть піти з роботи, тому одночасно повідомляють про це через нашу програму.
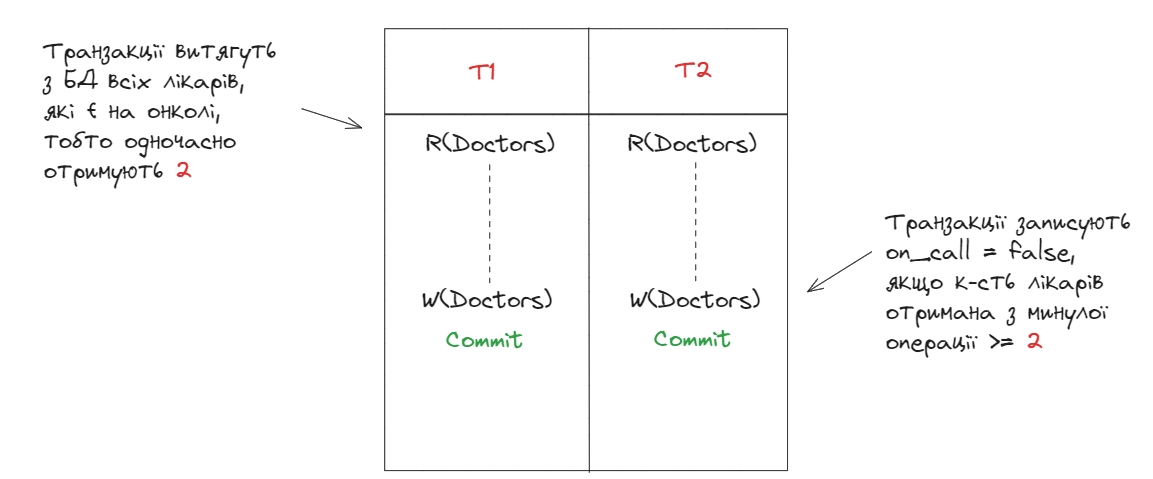
Так як при зчитуванні обидві транзакції отримали 2, то це задовільнило умову для запису даних, в результаті обидва лікарі зняли себе з on-call і всі у лікарні померли.
Особливість цього конфлікту полягає у тому, що змінюються різні рядки у базі даних, тобто не виникає прямого конфлікту між даними, що робить цей race condition менш очевидним.
Phantom read
Фантомне читання відбувається, коли транзакція двічі зчитує набір рядків, і нові рядки додаються або видаляються з цього набору іншою транзакцією.
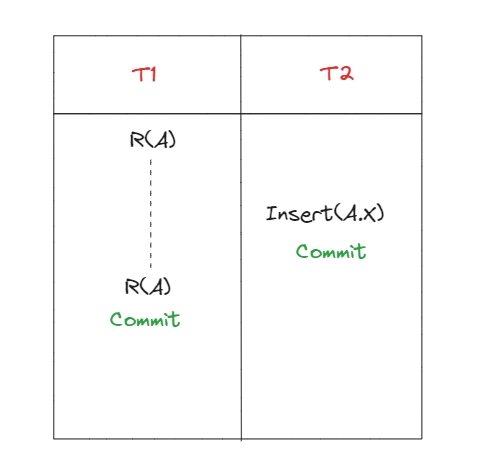
Чим phantom read відрізняється від non-repeatable read? Non-repeatable read стосується змін даних у існуючих рядках, а у phantom read додаються, або забираються рядки.
Існує підхід, materializing conflict, який перетворює фантом на конфлікт блокувань для конкретного набору рядків, які існують у базі даних. Для цього треба створити окрему табличку, яка використовуватиметься виключно для локів на потрібні дані.
Lost update
Lost Update схожий на Write Skew, тобто теж дві транзакції одночасно читають і змінюють дані, але у Lost Update транзакціїї змінюють один і той самий рядок, в наслідку чого втрачаються дані.
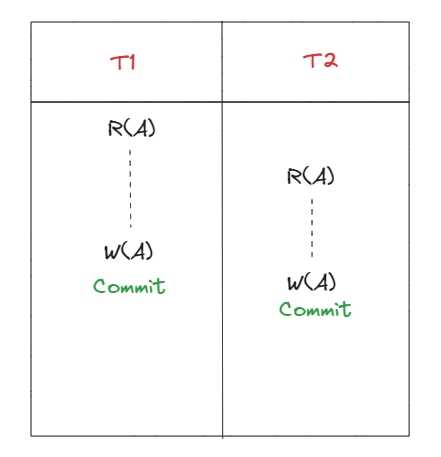
Від Dirty Write відрізняється тим, які дані будуть перезаписані: комітед(Lost Update) чи некомітед (Dirty write).
Halloween
Це дуже специфічна аномалія, трапляється, коли операція оновлення викликає зміну розташування рядка у результуючому сеті, потенційно дозволяючи рядку бути знову обробленим пізніше в тій самій операції оновлення.
Називається так, бо була відкрита у Геловін 1976-го під час роботи над запитом, який мав підвищити зарплату на десять відсотків кожному співробітнику, що заробляв менше $25,000. Цей запит виконувався успішно, без помилок, але після його завершення всі співробітники в БД заробляли принаймні $25,000.
Оскільки їм постійно підвищували зарплату, доки вони не досягли рівня встановленого запитом (25000). Очікувалося, що запит пройде по кожному запису про співробітників із зарплатою менше $25,000 лише один раз. Насправді ж, через те, що навіть оновлені записи були видимі для механізму виконання запитів і продовжували відповідати критеріям запиту, записи про зарплати відповідали кілька разів і кожного разу підвищувалися на 10%, доки всі вони не перевищили $25,000.
Тобто певному користувачу підняли ЗП з $14000 до $15400, але транзакція продовжувала бачити рядок з даними цього користувача при наступних командах і піднімала зарплату допоки на задовільнила свою умову (<25000).
Рівні ізоляції
Рівні ізоляції це групи гарантій, що описують, які race conditions, запобігаються у БД. Зазвичай категоризують за ступенем захисту від аномалій під час виконання транзакцій. Таким чином існують слабші та сильніші рівні ізоляції.
Read Uncommitted
Найнижчий рівень ізоляції, dirty reads дозволені. Використовується дуже рідко через ризик великої кількості аномалій.
Read Committed
Дві гарантії:
При читанні з БД транзакція бачитиме тільки дані, які були закомічені. (запобігає dirty read)
При записувані в БД транзакція тільки перезаписуватиме дані, які були закомічені. (запобігає dirty write)
Цей рівень ізоляції є доволі популярним, він є дефолтним в: Oracle 11g, PostgreSQL, SQL Server 2012, MemSQL
Запобігання dirty write зазвичай імплементують через блокування рядків. Перед модифікуванням об’єкта транзакція спочатку повинна взяти блокування над цим об’єктом і тримати його, доки не закінчить своє виконання. Якщо інша транзакція захоче переписати об’єкт у той самий момент часу, то їй доведеться чекати, поки перша транзакція не завершиться.
Для уникнення dirty read теж можна використовувати лок над рядками і змушувати кожну транзакцію брати лок над об’єктом в момент читання і відразу після прочитання відпускати лок.
Підхід із локування рядків для читання погано працює на практиці, бо одна довготривала транзакція запису може змусити багато транзакцій читання чекати доки довготривала транзакція виконається.
Це відбувається через те, що транзакції запису створюють лок на весь час виконання транзакції, коли транзакції читання тільки на момент читання даних.
По цій причині більшість БД використовують наступний підхід: Для кожного об’єкта, який записується, БД пам’ятає закомічене значення об’єкту (старе) і те, яке транзакція намагається закомітити (нове). Поки транзакція виконується - іншим транзакціям просто дається старе значення.
Repeatable Read
Repeatable Read часто імплементовується через Snapshot Isolation. Основна ідея Snapshot Isolation полягає в тому, що кожна транзакція отримує снапшот бази даних на час свого початку і працює з цим снапшотом протягом всієї своєї діяльності. Це означає, що вона бачить узгоджений стан даних, який не змінюється впродовж її життєвого циклу.
Для реалізації Snapshot Isolation система зберігає кілька версій кожного рядка даних, кожна версія має часову мітку, яка вказує час її створення або зміни, цей метод називається MVCC (Multi-Version Concurrency Control) Транзакції отримують доступ до версій даних, які існували на момент старту транзакції.
Є проблема з назвами, деякі БД цей рівень ізоляції називають Serializable (Oracle), деякі Repeatable Read (MySQL, PostgreSQL). Назва відрізняється через те, що SQL стандарт немає концепту ізоляції снапшотів, бо стандарт базується на System R визначені рівнів ізоляції (1975) і ізоляцію снапшотів тоді ще не придумали. Замість ізоляції напшотів стандарт визначає Repeatable Read, який поверхово схожий на ізоляцію снапшотів.
Декілька БД імплементують Repeatable Read, проте гарантії, які вони забезпечують сильно відрізняються від БД до БД. Існує формальне визначення Repeatable Read, але більшість імплементацій його не задовільняють.
Щоб все зробити ще заплутанішим IBM DB2 використовує Repeatable Read як назву Serializability
Serializable
Зазвичай цей рівень ізоляції вважається найсильнішим, гарантує, що два потоки будуть виконуватсь одночасно так само, як би і виконувались за порядком, звідси і слово serial.
Є три техніки імплементації Serializable:
Виконання транзакцій послідовно
2PL (Two-phase locking)
Оптимістичні підходи керування конкурентністю, як Serializable snapshot isolation (SSI)
Виконання транзакцій послідовно дозволить запобігти багатьом проблемам, такий підхід імплементований в Redis, також деякі системи з буквально серіальним виконанням можуть мати кращий перфоманс, бо уникають локінг та інші проблеми з координацією транзакцій.
Важливо розуміти, що послідовне виконання транзакцій використовує тільки одне ядро процесора.
Цей підхід добре підійде для швидких і малих транзакцій, також імплементація обмежена кейсами з оперативною пам’яттю, якщо дані не помістяться в RAM, то однопотоковий доступ до диску сильно вдарить по виконанню.
2PL є дуже старим підходом, його використовували 30 років (перестали в 70-х). 2PL можна описати, як більший суворий лок, який я описував у Read Committed.
Декілька транзакцій можуть брати лок для читання одного об’єкту допоки в об’єк ніхто не пише. Тільки як об’єкт хтось хоче модифікувати, то до об’єкту очікується ексклюзивний доступ.
В 2PL записувач не просто блокує інших записувачів, він також блокує інших читачів і навпаки.
У Snapshot Isolation читачі не можуть блокувати записувачів і навпаки.
Існує дві фази блокування:
Growing Phase: Транзакція може лише отримувати блокування (lock), але не може звільняти їх. Протягом цієї фази транзакція отримує необхідні блокування на об'єкти, з якими вона хоче взаємодіяти (читати чи писати).
Shrinking Phase: Транзакція може лише звільняти блокування, але не може отримувати нові. Коли транзакція починає звільняти блокування, вона переходить до цієї фази і не може більше отримувати нові блокування.
Таким чином записувачі і читачі змінюють один одному фазу блокування.
Використовуються два основні типи блокувань: спільні блокування (shared locks) для операцій читання і ексклюзивні блокування (exclusive locks) для операцій запису.
У 2PL поганий перфоманс пов’язаний із зміною локів і звісно через можливе виникнення дед локів, як наслідок взаємного блокування.
Існують інші види 2PL з більшою суворістю і з більшим обмеженням паралелізму: S2PL, і SS2PL.
Serializable Snapshot Isolation трішки програє Snapshot Isolation по перфомансу, використовується в PostgreSQL, як оптимістична імплементація Serializable. Імпементується як розширення Snapshot Isolation, де окрім базового алгоритму створення різних версій даних з прив’язкою до часу ще додається алгоритм перевірки серіальних конфліктів між записами транзакцій і визначення чи ці транзакції треба абортити чи комітити (Це і робить алгоритм оптимістичним).
Для великих транзакцій потрібні великі логи, як відслідковуватимуть конфлікти, БД потрібно буде не тільки тримати ці логи, а ще й проходитись по ним. Це варто враховувати.
Оптимістичний / Песимістичний підхід
У СУБД існують два основних підходи до контролю багатопотоковості: песимістичний і оптимістичний. Кожен з них має свої переваги та недоліки, і застосовується залежно від специфіки завдань.
2PL є песимістичним, якщо щось може піти погано, то краще перечекати доки ситація не стане хорошою знову, щоб продовжити роботу. SSI є оптимістичним підходом, замість блокування, якщо щось небезпечне трапиться, транзакція просто продовжить своє виконання з надією, що все виправиться.
Оптимістичний підхід для підтримки узгодженості даних перевіряє конфлікти перед комітом і на основі наявності конфліктів транзакція абортиться, або комітиться.
Чіт шит
Тут перелік зручних табличок про покриття аномалій, опис рівнів та опис імплементацій.
Рівень | Dirty Reads/Writes | Non-repeatable | Write Skew | Phantom | Lost updates | Halloween |
|---|---|---|---|---|---|---|
Read Uncommitted | + | + | + | + | + | - |
Read committed | - | + | + | + | + | - |
Repeatable Read | - | - | - | + | - | - |
Serializable | - | - | - | - | - | - |
Рівень | Опис |
|---|---|
Read Uncommitted | Найнижчий. Дозволяє бачити дані, які ще не були закомічені |
Read committed | Дозволяє бачити тільки дані, які були закомічені |
Repeatable Read | Гарантує, якщо транзакція читає рядок, вона може знову прочитати цей рядок пізніше в транзакції та знайти ті самі значення |
Serializable | Найвищий. Гарантує, що транзакцій виконуються паралельно гарантуєчи такий рівень ізоляції, якби вони виконували послідовно (serial) |
Ріень | Імплементація |
|---|---|
Read Uncommitted | - |
Read committed | 1. Блокування рядків з взаємним очікуванням 2. Зберігати старе і нове значення і при очікуванні давати старе |
Repeatable Read | Snapshot Isolation: Зберігати багато версій даних з прив’язкою до часу (снапшот). Кожна транзакція працює з своїм снапшотом |
Serializable | 1. Послідовне виконання 2. 2PL: Спільні локи для читання і лок для запису, які постійно змінюють лок над об’єктом один одному 2. Serializable Snapshot Isolation: Це Snapshot Isolation з перевіркою на конфлікти в кінці транзакції, щоб перевіряти, чи потрібен ролбек |
Джерела
Martin Kleppmann. Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
https://blog.coeo.com/a-cheat-sheet-for-isolation-levels-in-sql-server
