Apache Kafka, популярна система обробки потокових даних, зробила значний крок у своєму розвитку, вирішивши перейти від використання Apache Zookeeper до власної реалізації протоколу консенсусу, відомого як KRaft (Kafka Raft). Це рішення має значні наслідки для архітектури та управління Kafka.
Консенсус
Консенсус в розподілених системах — це фундаментальний принцип, який дозволяє декільком взаємопов'язаним вузлам (або процесам) у системі досягти загальної домовленості щодо певних даних або стану системи, незважаючи на наявність помилок або відмов деяких вузлів. Цей принцип є ключовим для забезпечення надійності та послідовності в розподілених системах, таких як блокчейни, бази даних, системи управління версіями тощо. Протоколи консенсусу, такі як Paxos, Raft, або Zab, дозволяють системі продовжувати роботу коректно, навіть коли деякі компоненти відмовляють або існують мережеві розриви, забезпечуючи, що всі підняті вузли мають консистентний вигляд даних.
Основні аспекти консенсусу в розподілених системах включають:
Узгодженість (Agreement): Всі коректні вузли системи мають погодитися на одне й те саме значення або рішення.
Стійкість до відмов (Fault Tolerance): Система повинна забезпечувати консенсус навіть у присутності відмов частини вузлів. Це означає, що система може витримувати певну кількість відмов (зазвичай меншу половину вузлів) без втрати здатності досягати консенсусу.
Живучість (Liveness): Система повинна забезпечити, що кожен коректний запит на досягнення консенсусу буде врешті-решт завершений.
Відсутність блокувань (Non-blocking): Процес досягнення консенсусу не повинен назавжди застрягти в стані, де рішення не може бути прийняте.
А що таке розподілена система?
Розподілена система — це група комп'ютерів, що працюють разом, як єдине ціле, для досягнення спільної мети. Ці комп'ютери (вузли) можуть бути фізично розташовані в одному центрі обробки даних або розкидані по всьому світу. Розподілені системи дозволяють обробляти більші обсяги даних, забезпечувати високу доступність послуг шляхом реплікації даних та обчислювальних ресурсів, а також підвищити витривалість системи за рахунок толерантності до відмов окремих компонентів.
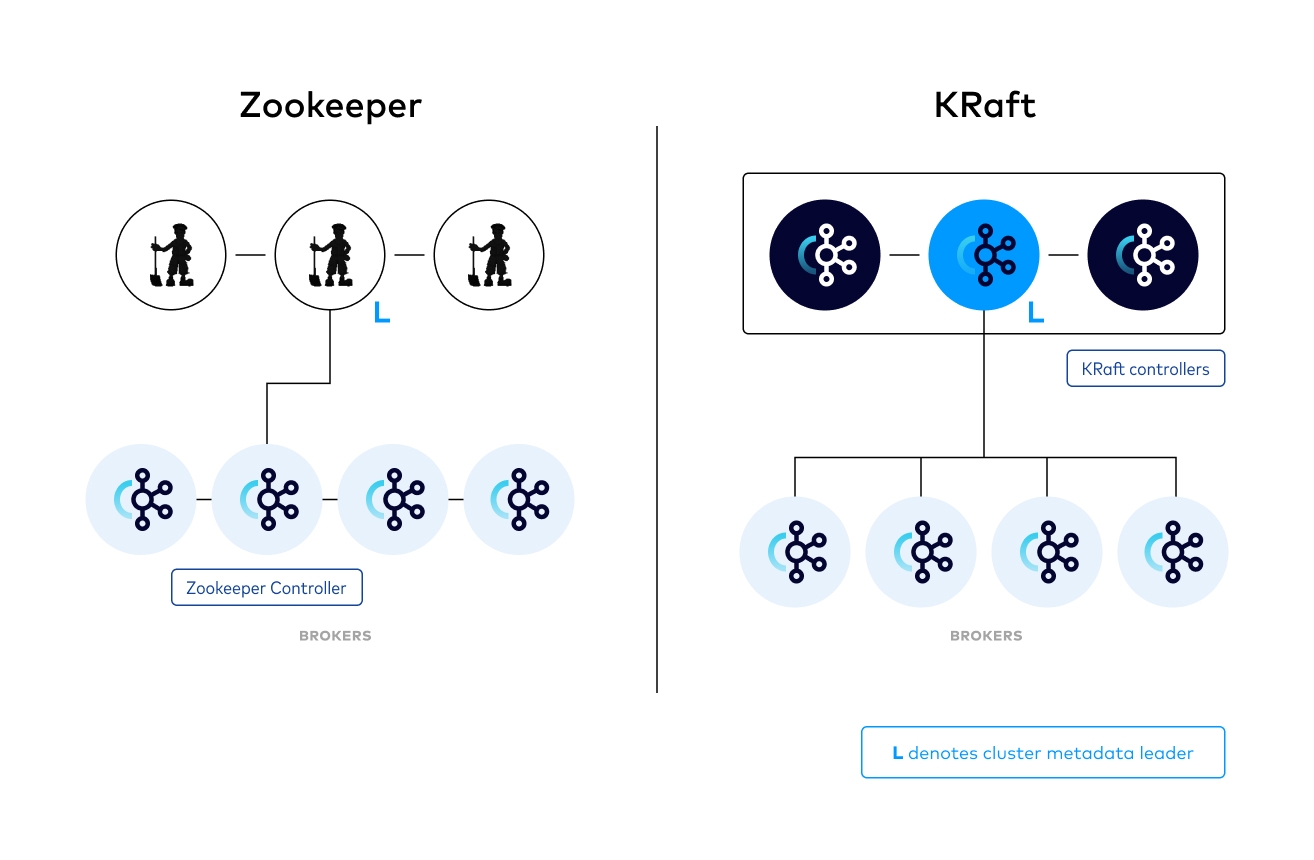
Zookeeper
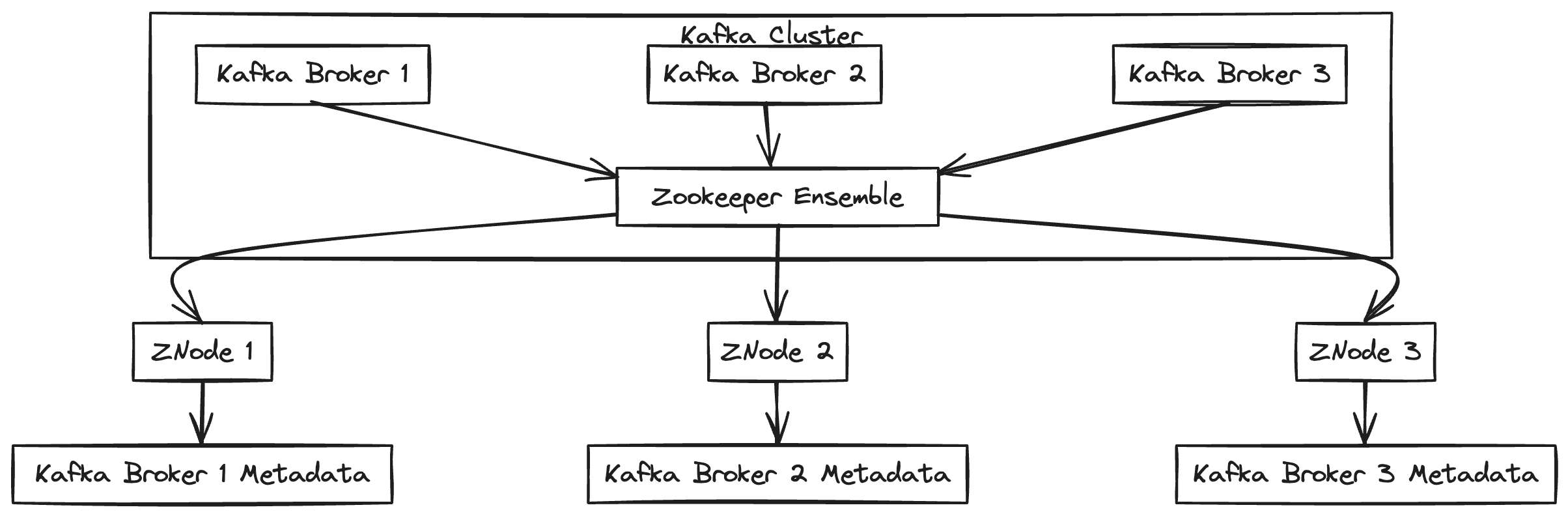
Apache Zookeeper — це централізована служба для зберігання конфігурацій, неймінгу, синхронізації та надання групових послуг. Вона використовується для координації між вузлами в розподіленій системі. У контексті Kafka, Zookeeper використовувався для управління метаданими кластера (такими як інформація про топіки, партиції, репліки та їх статуси) та вибору лідера серед реплік.
Перехід до KRaft
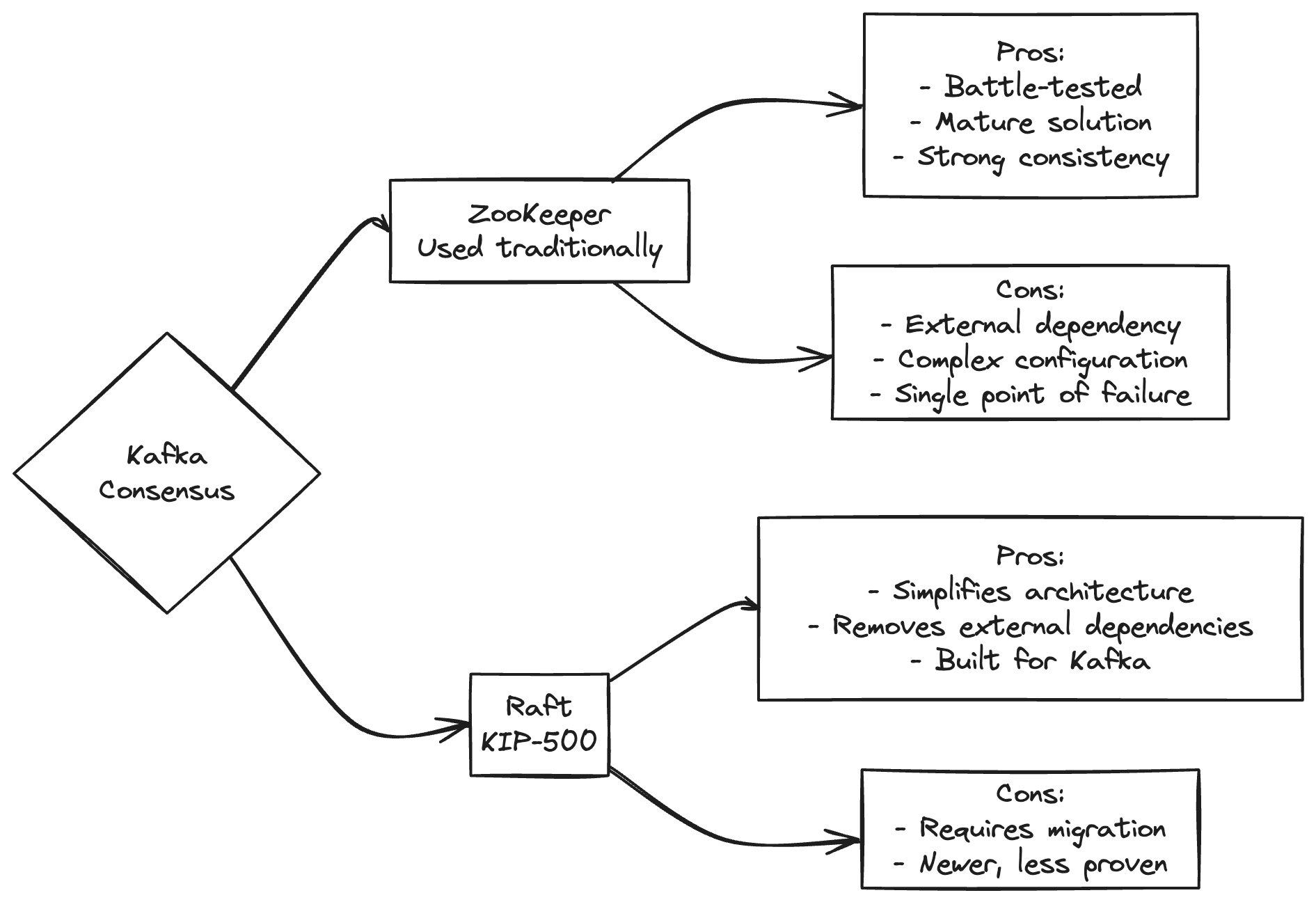
Рішення Kafka перейти на використання KRaft замість Zookeeper було мотивовано декількома факторами:
Спрощення архітектури: Видалення залежності від Zookeeper дозволяє спростити розгортання та управління Kafka, усуваючи потребу у додатковому компоненті та можливих точок збою.
Покращення продуктивності: Власний протокол консенсусу може бути тісно інтегрований з логікою Kafka, забезпечуючи кращу продуктивність та масштабованість.
Контроль та оптимізація: Розробка протоколу KRaft надає команді Kafka більше можливостей для контролю та оптимізації протоколу консенсусу. Вони можуть адаптувати протокол до специфічних потреб та сценаріїв використання Kafka, що може сприяти покращенню загальної ефективності та надійності системи.
Що таке Raft?
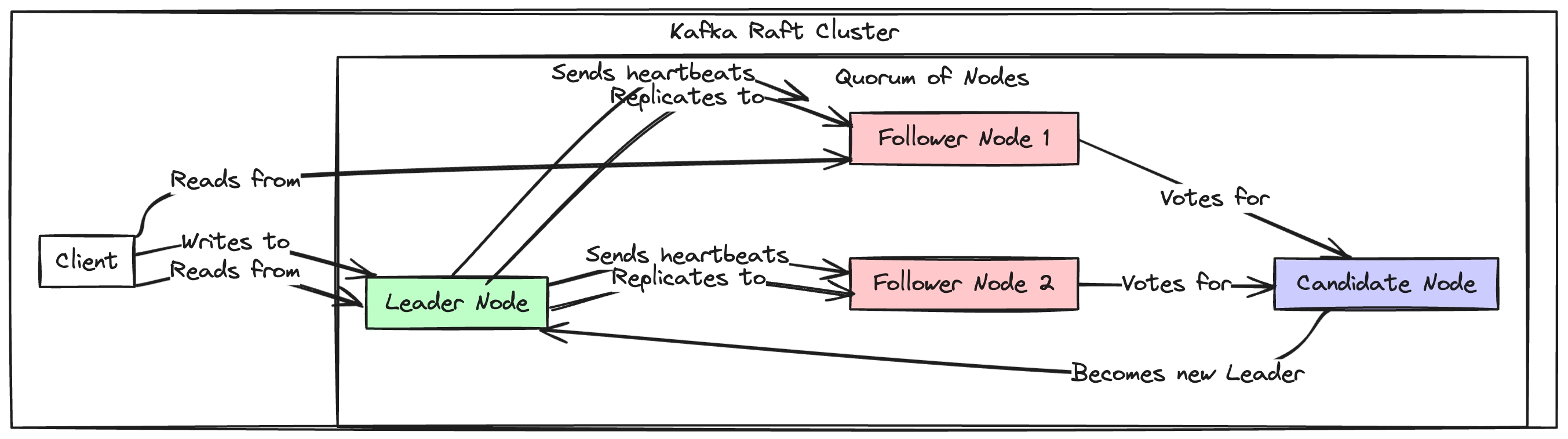
Raft — це протокол консенсусу, який був розроблений як більш проста альтернатива іншим протоколам, наприклад Paxos. Його основне завдання полягає в забезпеченні узгодженого стану між вузлами у розподіленій системі, що дозволяє системі залишатися стійкою до збоїв окремих вузлів. Основою Raft є механізм 'вибору лідера', який гарантує, що в кожний момент часу існує один вузол-лідер, відповідальний за управління процесом реплікації даних між вузлами, з метою досягнення консистентності інформації в усьому кластері.
Концепція 'вибору лідера' полягає в автоматичному виборі одного вузла кластера, який тимчасово виконує роль координатора між усіма вузлами. Цей лідер відповідає за прийняття оновлень і координування процесу їх реплікації до інших вузлів, забезпечуючи, щоб усі вузли мали однаковий, актуальний стан даних.
Відмінності між Zookeeper і Raft
Концепція та архітектура: Zookeeper був розроблений як загальний інструмент для координації розподілених систем, тоді як Raft спеціально призначений для забезпечення консенсусу в таких системах.
Спрощення vs універсальність: Raft надає більш простий підхід до досягнення консенсусу, зосереджуючись на легкості розуміння та реалізації. Zookeeper, навпаки, пропонує більш універсальні можливості координації, що може призвести до більшої складності в конфігурації та управлінні.
Інтеграція з Kafka: Перехід до KRaft дозволяє Kafka тісніше інтегрувати логіку консенсусу з внутрішніми процесами системи, забезпечуючи кращу продуктивність та масштабованість.