
Якщо ви стежили за розвитком ШІ у 2025 році, то напевно помітили: слово «агенти» з’являється всюди. І це не просто черговий хайп. Агентні системи вже вміють брати на себе як прості побутові задачі, так і складні робочі процеси з кількома агентами, де кожен виконує свою роль.
І це тільки старт. Найближчими роками ми побачимо ще більше інструментів, фреймворків і практичних кейсів — і «агенти» поступово стануть таким же звичним елементом роботи, як колись стали таблиці, CRM або автоматизації в месенджерах.
Цей матеріал — структурований гайд про те, як підходити до AI-агентів без магії й туману:
Спочатку — база. Що таке AI-агент, які в нього ключові «деталі», і де агенти реально корисні. Окремо — варіанти без коду, якщо хочеться спробувати одразу.
Далі — середній рівень. Як будувати та оцінювати мультиагентні системи, які вирішують прикладні задачі, а не “красиво виглядають у демо”. Також буде приклад (типовий сценарій), як агентна система може економити години щотижня.
Потім — просунутий рівень. Що потрібно, щоб агенти працювали надійно в продакшені: контроль якості, безпека, відмовостійкість, обмеження і правила.
Бонус для технічних читачів. Як влаштовані «агентні» дев-інструменти на кшталт Claude Code: що там відбувається під капотом і чому це важливо розуміти навіть тим, хто не пише код щодня.
Матеріал буде корисним і тим, хто не є технарем, але хоче автоматизувати власні процеси, і тим, хто будує системи для команди чи бізнесу.
Перш ніж ми продовжимо, переконайтеся, що ви підписані на мій телеграм канал — у мене є преміум-контент, який скоро з’явиться там, а також залишайтеся на зв’язку зі мною!
Переходимо до основ.
Beginner: що таке AI-агент
Почнемо з найпростішого питання: що взагалі називають AI-агентом?
Найзручніше пояснення — через порівняння з «звичайним» запитом до мовної моделі.
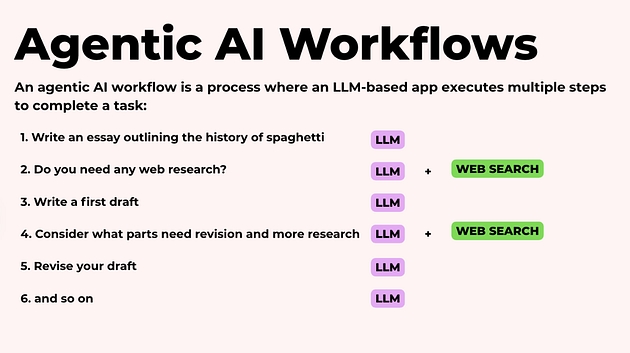
Уявіть, що вам потрібно написати есе. Класичний підхід до LLM виглядає так: ви пишете запит на кшталт “Напиши есе про те, як почати ходити в зал”, і модель видає текст одним проходом — від першого до останнього речення.
Але люди зазвичай так не працюють. Ми не створюємо ідеальний текст з першої спроби. Зазвичай процес інший:
зрозуміти задачу й ціль
накидати план
зібрати факти / приклади
написати чорновик
перечитати
виправити й доповнити
Агентний підхід робить так само. Замість одного «лінійного» запиту агент працює ітеративно: ставить проміжні підзадачі, перевіряє себе, уточнює дані, повертається і покращує результат — тобто імітує реальну людську роботу як процес, а не як “вивід тексту”.

Тож як це виглядає на практиці?
Повернемося до прикладу з есе. Ось як з цією задачею працює AI-агент.
Крок 1. Формування плану
Спочатку агент не пише текст. Він будує структуру: визначає основні блоки, логіку подачі та послідовність. Що має бути вступом? Які ключові думки потрібно розкрити? У якому порядку це читається найкраще?
Крок 2. Визначення потрібної інформації
Далі агент аналізує план і розуміє, яких даних йому бракує. Де потрібні факти, приклади, цифри, визначення або порівняння — і що саме потрібно з’ясувати перед написанням.
Крок 3. Збір даних
Після цього агент отримує необхідну інформацію з зовнішніх джерел. Це може бути:
пошук у вебі;
запити до API;
завантаження та аналіз документів або інших матеріалів.
Зібрані дані використовуються не «як є», а як основа для осмисленого результату.
Крок 4. Чорновий варіант
Лише після цього агент переходить до написання першої версії тексту — використовуючи структуру і перевірені дані, а не просто генерацію “з голови”.
Саме ця поетапність і відрізняє агентний підхід від звичайного запиту до мовної моделі: результат з’являється не миттєво, зате він контрольований, логічний і ближчий до реальної роботи людини.
Але найцікавіше — на цьому процес не закінчується.
Після першого результату агент оцінює власну роботу і повертається до неї з критичним поглядом. Він може:
посилити слабкі аргументи;
додати відсутні пояснення або факти;
покращити логіку переходів між абзацами;
зробити текст більш цілісним і читабельним.
Тобто агент не просто «згенерував і забув», а працює з результатом так само, як це робить людина під час редагування.
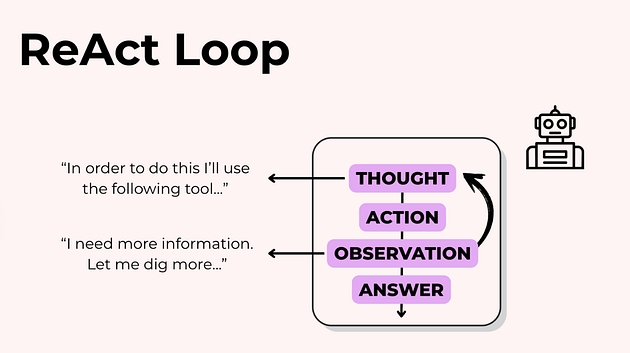
Саме цей цикл і називають ReAct-підходом (Reason → Act → Observe).
Як він працює на практиці:
Reason — модель аналізує, що робити далі
Act — виконує дію (часто це виклик інструменту: пошук, запит до API, обробка даних — про це буде далі)
Observe — оцінює результат дії
або видає фінальну відповідь, або знову повертається до етапу аналізу
Цей цикл може повторюватися кілька разів, поки агент не дійде до прийнятного результату або не досягне заданого обмеження.
Саме ReAct-логіка робить агентні системи гнучкими, керованими й придатними для реальних задач, а не лише для одноразової генерації тексту.
Цей підхід працює саме тому, що кожен прохід додає глибини.
У результаті ми отримуємо:
сильніше й послідовніше мислення;
менше «галюцинацій»;
кращу структуру та логіку.
Усе це зазвичай втрачається, коли ми намагаємося зробити всю роботу одним запитом.
Тому агентний підхід особливо добре підходить для задач, де важливі акуратність, перевірка й джерела. Типові приклади:
юридичні дослідження, де потрібно посилатися на конкретні справи або норми;
медична документація;
служби підтримки, яким перед відповіддю потрібно підтягнути дані облікового запису, замовлення чи історію звернень.
Втім, підвищена точність і спеціалізація мають зворотний бік — зростає складність системи. І тут логічно виникає питання:
які задачі взагалі варто вирішувати за допомогою агентів?
Для яких задач агенти підходять найкраще
Не всі задачі однаково добре лягають на агентний підхід. Розглянемо приклади — від найпростіших до складніших.
Простий рівень
Елементарна агентна система може, наприклад, витягувати ключові поля з рахунків-фактур і зберігати їх у базу даних.
Задачі з чітким, повторюваним процесом — ідеальні для агентів.
Середній рівень складності
Обробка клієнтських листів. Агент:
знаходить замовлення;
перевіряє дані клієнта;
готує відповідь для фінального перегляду людиною.
Тут агент не приймає остаточних рішень, але знімає значну частину рутинної роботи.
Вищий рівень
Повноцінний агент служби підтримки, який відповідає на запити типу:
«Чи є у вас сині джинси в наявності?»
«Як мені повернути покупку?»
У випадку повернення агенту потрібно:
перевірити факт покупки;
зіставити його з політикою повернень;
визначити, чи дозволене повернення;
провести клієнта через багатокроковий процес.
Тут агент уже не просто виконує сценарій — він сам визначає послідовність кроків залежно від ситуації.
Як зрозуміти, чи потрібен тут агент
Зручний спосіб мислення — уявити матрицю з двома осями:
складність задачі;
необхідна точність.
Є задачі з високою складністю і високими вимогами до точності — наприклад, заповнення податкових форм.
Є задачі складні, але без потреби в ідеальній точності — наприклад, створення й перевірка конспектів лекцій.
Саме позиція задачі в цій матриці допомагає вирішити, чи виправдано будувати агентну систему, чи простішого підходу буде достатньо.
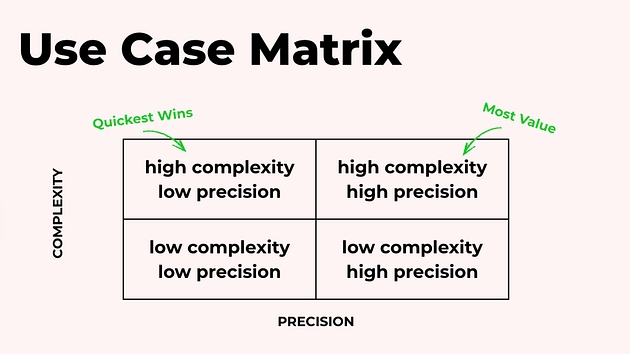
Найбільшу цінність агенти зазвичай дають саме у високоскладних задачах. А найшвидші перші результати найчастіше з’являються там, де не потрібна ідеальна точність у кожному кроці.
Саме тому сектор «висока складність + нижчі вимоги до точності» часто є найкращою стартовою точкою. Ви отримуєте відчутний ефект від автоматизації чогось нетривіального — і при цьому не блокуєтесь через необхідність безпомилкового результату щоразу.
Якщо підсумувати:
агентні системи найкраще проявляють себе там, де задача:
потребує ітерацій;
включає дослідження або пошук інформації;
складається з кількох послідовних кроків, а не одного запиту.
На практиці часто має сенс починати саме зі складних задач, які можуть «пробачити» невелику неточність, але забирають багато часу у людини.
Спектр автономності агентів
Тепер, коли зрозуміло, для яких задач агенти підходять, перейдемо до питання як їх будувати. І перше ключове рішення тут —
скільки автономності ви готові надати агенту?
Найзручніше думати про це як про спектр, а не як про бінарний вибір «автоматично / вручну».
На одному кінці — системи, де агент лише допомагає людині.
На іншому — майже повністю автономні системи, які самі планують, діють і завершують задачі.
Далі цей спектр ми розберемо по рівнях.
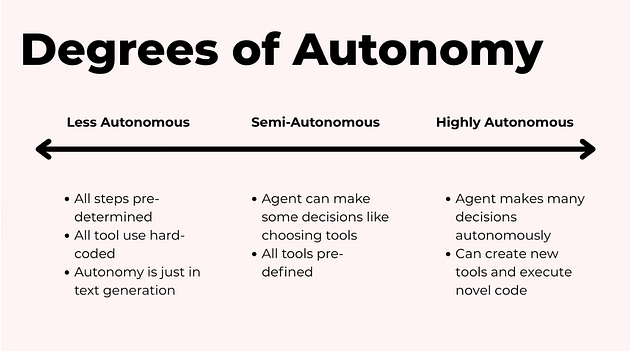
На одному кінці спектра — жорстко заскриптовані агенти, де кожен крок визначений наперед.
У прикладі з есе це виглядало б так:
спочатку згенерувати пошукові запити → виконати вебпошук → завантажити сторінки → написати текст. Крапка.
Такий підхід:
детермінований;
передбачуваний;
простий у контролі.
Роль мовної моделі тут зводиться до генерації тексту — всі рішення вже прийняті вами.
На іншому кінці — високоавтономні агенти.
У цьому випадку LLM сам вирішує:
чи шукати інформацію в Google, новинах або наукових публікаціях;
скільки сторінок завантажувати;
чи потрібно конвертувати PDF-файли;
чи варто повернутися до результату і переписати його;
а інколи навіть — створити нові функції та виконати їх.
Такий підхід значно потужніший, але має очевидні мінуси:
він менш передбачуваний і набагато складніший у контролі.
У реальному світі більшість агентів знаходяться десь посередині.
Це напів автономні системи, де агент:
обирає лише з тих інструментів, які ви йому дозволили;
приймає рішення в межах чітко заданих правил і обмежень.
Саме цей баланс між гнучкістю та контролем найчастіше і працює найкраще.
Context engineering: керування поведінкою агента
Але виникає логічне питання:
звідки агент взагалі знає, які інструменти існують і як приймати рішення?
Відповідь — context engineering.
Context engineering — це процес, під час якого ви визначаєте, який контекст доступний агенту. До нього входить:
опис задачі та її цілей;
роль агента (що він може і чого не повинен робити);
пам’ять про попередні дії або стани;
перелік доступних інструментів і способів їх використання.
Коли весь цей контекст зібраний разом, він починає виконувати роль «навігатора» для недетермінованої моделі.
Саме контекст спрямовує її до стабільних, якісних і повторюваних результатів — навіть тоді, коли сама модель не є строго передбачуваною.
Саме це і є практична основа “інтелекту” агентів.
Справа не лише в самій моделі. Ключову роль відіграє те, як ви вибудовуєте контекст навколо неї.
Протягом усього матеріалу ми ще не раз будемо повертатися до цих компонентів і показувати, як вони впливають на якість агентних систем.
Декомпозиція задач (Task Decomposition)
Коли контекст визначений, настає наступний критично важливий етап — формулювання задач, які агент має виконувати.
Насправді, вміння правильно розкласти задачу — це, ймовірно, найважливіша навичка у створенні агентів.
Практичний підхід виглядає так:
спочатку подумайте, як би ви виконували цю задачу самі;
для кожного кроку запитайте себе:
«Це може зробити LLM? Невеликий шматок коду? API?»якщо відповідь «ні» — розбийте крок на менші, доки він не стане виконуваним.
Повернемося до прикладу з агентом для написання есе.
Якщо відтворити реальний людський процес і адаптувати його під AI, він може виглядати так:
створення структури есе за допомогою LLM;
генерація пошукових запитів через LLM і виклик пошукового API;
завантаження сторінок або матеріалів через інструмент;
написання чорнового варіанту з використанням джерел;
самокритика тексту: аналіз, що слабке або чого бракує;
доопрацювання і переписування.
Кожен із цих кроків:
невеликий;
перевіряється окремо;
має чіткий результат.
Якщо фінальний текст виходить слабким, ви точно знаєте, який саме етап потрібно покращити, а не “все одразу”.
INTERMEDIATE: оцінювання результатів
Тепер, коли ми розібрали фундамент і переходимо до середнього рівня, почнемо з речі, яка здається нудною — але саме вона відрізняє аматорів від професіоналів.
Оцінювання продуктивності агентів.
У деяких випадках усе просто.
Наприклад, якщо чат-бот служби підтримки відповідає на питання “Чи є цей товар у наявності?”, можна напряму вимірювати, чи правильна відповідь.
Але далеко не всі задачі настільки однозначні.
Повернемося до агента, який пише есе.
Як зрозуміти, що есе справді якісне?
Один із поширених підходів — використати другу мовну модель як оцінювача.
Вона отримує текст і виставляє оцінку, наприклад, за шкалою від 1 до 5 — на основі заздалегідь визначених критеріїв: логіка, структура, повнота, ясність.
Саме з цього моменту агентні системи починають переходити з експериментів у керовані, масштабовані рішення.

Оцінювати агентну систему можна на двох рівнях:
на рівні окремих компонентів — щоб переконатися, що кожен крок працює коректно;
end-to-end — щоб оцінити загальну якість фінального результату.
Якщо система працює гірше, ніж очікувалося, перше, що варто зробити, — подивитися на проміжні кроки. Їх зазвичай називають trace.
Trace може включати:
пошукові запити, які сформував агент;
чорнові версії тексту;
проміжні «міркування» та рішення.
Переглядаючи цей ланцюжок, часто легко помітити повторювані проблеми:
наприклад, занадто загальні пошукові запити або ситуацію, коли етап редагування не отримує коректної критики.
Такі спостереження одразу перетворюються на:
нові критерії оцінювання;
або конкретні правки в системі.
Важливо починати з оцінювання якнайшвидше, але не намагатися побудувати ідеальну систему перевірок з першого разу. Набагато ефективніше — запустити щось просте й поступово вдосконалювати його через ітерації.
Памʼять (Memory)
Коли у вас уже є базова система та спосіб вимірювати її роботу, наступний крок — покращення результатів. Один із найпоширеніших механізмів для цього — памʼять.
Памʼять дозволяє агенту:
запам’ятовувати, що спрацювало;
фіксувати, що пішло не так;
коригувати поведінку в наступних запусках.
Зазвичай використовують кілька рівнів памʼяті.
Короткострокова памʼять
Агент записує свої дії та проміжні результати під час виконання задачі.
У мультиагентних системах ці нотатки можуть читати інші агенти.
Рефлексія після завершення
Після виконання задачі агент:
аналізує результат;
порівнює його з очікуваннями;
визначає, що спрацювало добре, а що — ні;
зберігає ці висновки.
Довгострокова памʼять
Наступного разу агент завантажує ці уроки і застосовує їх одразу — без повторення тих самих помилок.
Такий підхід дозволяє фактично «навчати» агентів — подібно до контрольованого навчання. Ви даєте зворотний зв’язок, і з кожним запуском якість результатів зростає.
Важливе розрізнення:
памʼять — динамічна, оновлюється після кожного виконання;
знання — статичні.
Знання — це довідкові матеріали, які ви завантажуєте наперед: PDF, CSV, документація, доступ до бази даних. Агент не змінює їх, а лише звертається до них, коли потрібно щось точно процитувати або перевірити.
Guardrails: обмеження і контроль
Коли агент має задачу, знання та памʼять, виникає спокуса «відпустити його у вільне плавання».
Але тут важливо зупинитися.
Мовні моделі — недетерміновані. Вони можуть:
помилятися у фактах;
порушувати формат;
видавати небажані або некоректні результати.
Щоб цього уникнути, потрібні guardrails — обмеження та перевірки.
Guardrails — це, по суті, контрольний барʼєр між тим, що агент вважає виконаним, і тим, що реально потрапляє у фінальний результат.
Існує три основні підходи до guardrails (у продакшені зазвичай використовують щонайменше два).
1. Детерміновані перевірки кодом
Для формату, довжини, структури або обовʼязкових полів достатньо звичайних перевірок у коді.
Це:
швидко;
дешево;
максимально надійно.
Там, де це можливо, такий підхід завжди варто використовувати першим.
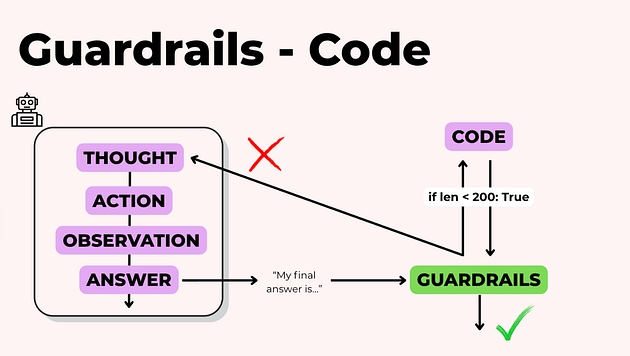
Але не всі перевірки можна звести до простих умов у коді.
Іноді потрібно контролювати більш тонкі речі, наприклад:
чи фактично узгоджується відповідь із джерелами;
чи відповідає текст потрібному тону — нейтральному, професійному, доброзичливому;
чи не з’являються припущення, яких немає у вихідних даних.
Такі критерії складніше формалізувати, але саме вони часто визначають, чи можна довіряти агенту в реальних сценаріях — особливо в юридичних, медичних або клієнтських системах.
Тут і з’являються більш складні типи guardrails, які виходять за межі звичайних if/else-перевірок і потребують окремого підходу.
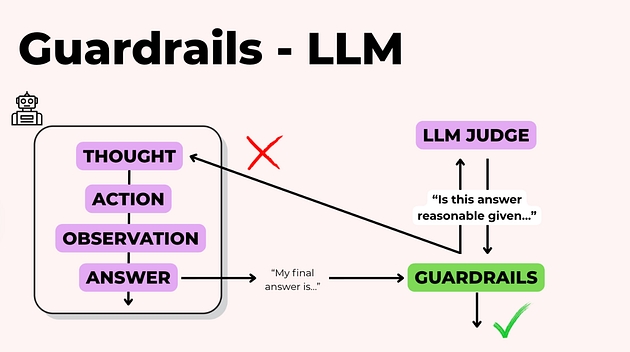
Guardrails: LLM-оцінювач і перевірка людиною
Коли потрібно перевіряти нюансні речі — узгодженість із джерелами, адекватність тону, відсутність непідтверджених тверджень — зручний підхід: використати іншу LLM як “суддю” (LLM judge).
Логіка проста:
оцінювач перевіряє результат і відповідає, чи проходить він перевірку;
якщо ні — пояснює, чому саме (що не так із фактами, стилем, структурою);
цей фідбек повертається в систему;
агент переписує результат і пробує ще раз.
Іноді жоден автоматичний контроль не дає потрібного рівня довіри — тоді потрібна людина в контурі (human-in-the-loop).
Замість того щоб автоматично «відвантажувати» результат, агент:
зупиняється на етапі “чернетка готова”;
просить підтвердження;
отримує правки/коментарі;
і робить повторну спробу.
Це не гальмо. Це спосіб зробити систему керованою там, де помилка коштує дорого — в сервісі, юридичних текстах, фінансах, документах.
Design patterns: як підвищувати якість агентів
Ми вже проговорили, як змусити систему працювати. Тепер — як зробити її стабільно якісною.
Є чотири патерни, які майже завжди підсилюють агентні системи:
reflection (рефлексія)
tool use (використання інструментів)
planning (планування)
multi-agent collaboration (взаємодія кількох агентів)
Почнемо з найпростішого і водночас одного з найефективніших — Reflection.
Reflection
У двох словах: reflection означає, що ми не зупиняємося на першій чернетці.
Процес виглядає так:
модель створює результат;
потім сама його критикує за заданими критеріями;
і переписує, якщо потрібно.
Другий прохід, підказаний промптом «знайди та виправ проблеми», майже завжди піднімає якість: робить текст точнішим, чистішим і зрозумілішим.
Мініприклад (лист/повідомлення)
Версія 1 (чернетка):
«Привіт, давай зустрінемось наступного місяця обговорити проєкт. Дякую.»
Проблеми очевидні:
«наступного місяця» — занадто розмито;
немає фінального прощання / підпису;
«Дякую» звучить трохи різко й обриває тон.
Крок reflection:
модель перечитує текст і фіксує: нечіткі строки, відсутній нормальний фінал, тон поспішний.
Версія 2 (після правок):
«Привіт, Алекс. Пропоную зустрітися 5–7 січня, щоб узгодити таймлайн проєкту. Напиши, який день тобі підходить. З повагою, Марина.»
Сенс той самий, але повідомлення стало:
конкретним;
професійним;
легшим для відповіді.
Чому reflection особливо сильний у коді
У коді рефлексія стає ще потужнішою, бо можна додати зовнішній фідбек:
написали код;
інший агент/критик перевірив логіку;
код реально запустили;
отримали помилки/тести/вивід.
І вже ці конкретні сигнали повертаються в модель — і друга версія виходить значно ближчою до робочої.
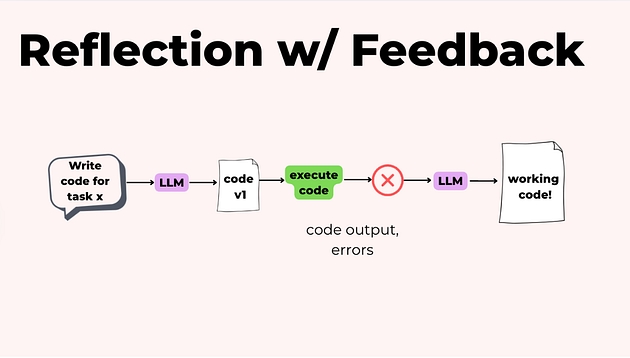
Reflection особливо корисний у кількох типових сценаріях:
структуровані результати — наприклад, JSON, де легко перевірити пропущені поля або помилки формату;
процедурні інструкції — на кшталт покрокового алгоритму (наприклад, інструкції заварювання чаю), де reflection може виявити відсутні або переплутані кроки;
креативні задачі;
довгі тексти, де важливі логіка, зв’язність і повнота.
Особливо добре reflection працює тоді, коли можна підключити зовнішній фідбек.
Наприклад:
прогнати JSON через валідатор схеми;
перевірити, чи є всі необхідні посилання в дослідницькому тексті;
автоматично виявити пропущені джерела або помилки структури.
Втім, у цього підходу є й мінус:
reflection збільшує затримку та вартість, бо система робить кілька проходів замість одного.
Тому важливо не включати його «за замовчуванням», а тестувати з reflection і без нього, щоб переконатися, що він справді підвищує якість, а не просто ускладнює систему.
Tool Use: використання інструментів
Переходимо до другого дизайн-патерну — tool use.
Базова ідея проста:
ви даєте LLM набір інструментів, якими вона може користуватися. Це може бути:
вебпошук;
запити до бази даних;
виконання коду;
доступ до календаря;
робота з CRM або іншими внутрішніми системами.
Далі модель сама вирішує, коли і який інструмент викликати.
Це критично важливо, бо сама по собі LLM — лише генератор тексту.
Вона:
не знає поточного часу;
не має доступу до ваших бізнес-даних;
не може виконувати код для точних обчислень.
Але з інструментами вона вже може:
шукати інформацію в інтернеті;
робити запити до бази;
оновлювати записи в CRM;
виконувати обчислення через код.
Простий приклад.
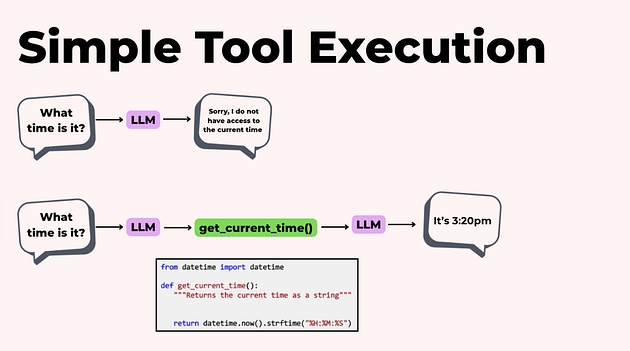
Якщо запитати агента: «Котра зараз година?»,
LLM:
викликає функцію
getCurrentTime();отримує відповідь, наприклад, «15:20»;
повертає вже точний результат користувачу.
Саме через інструменти агент перестає бути “розумним текстом” і починає взаємодіяти з реальним світом.
Аналогічно агент може:
шукати локальні ресторани;
робити запити до бази даних;
виконувати математичні обчислення.
У кожному з цих випадків модель розпізнає, що їй потрібна зовнішня інформація або точний розрахунок, обирає відповідний інструмент і використовує результат для фінальної відповіді.
Ланцюжки інструментів (tool chaining)
Коли ви надаєте моделі кілька інструментів, вона може поєднувати їх у ланцюжок — виконуючи складніші дії з кількох кроків.
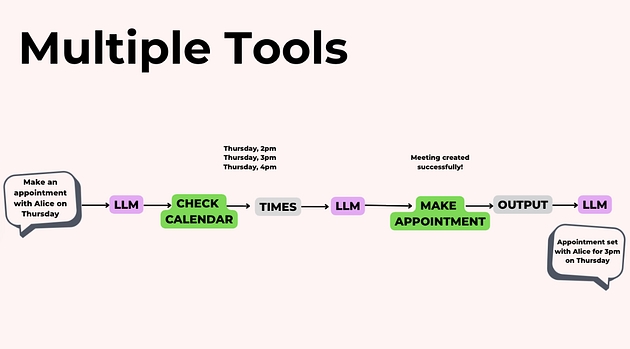
Приклад — асистент для роботи з календарем.
Припустимо, агент має доступ до трьох інструментів:
checkCalendar— перевірити зайнятість;makeAppointment— створити зустріч;deleteAppointment— скасувати подію.
Користувач пише:
«Заплануй зустріч з Алісою на цьому тижні».
Агент мислить так:
перевірити календар і знайти вільні слоти;
визначити відповідний час — наприклад, четвер о 15:00;
викликати
makeAppointmentз ім’ям Аліси та вибраним часом;підтвердити дію користувачу.
Ззовні це виглядає як проста команда, але всередині агент виконує послідовність осмислених дій, використовуючи інструменти так, ніби це зробила людина-асистент.
Саме завдяки таким ланцюжкам агенти стають здатними виконувати реальні робочі процеси, а не лише відповідати на питання.
Ключовий момент у використанні інструментів такий:
LLM щоразу сама вирішує, який інструмент викликати далі, спираючись на результат попереднього кроку. Це не фіксований конвеєр, а динамічний процес.
Як LLM “викликає” інструменти насправді
Тут важливо розуміти один нюанс:
LLM не виконує код. Вона лише генерує текст.
Тобто насправді модель не викликає функцію, а запитує виклик.
Ось як виглядає цей цикл «під капотом»:
користувач надсилає запит;
LLM аналізує, які інструменти їй доступні, і вирішує, чи потрібен якийсь із них;
якщо потрібен — модель генерує спеціальний запит, наприклад:
«Хочу викликатиgetCurrentTimeз часовим поясом Pacific/Auckland»;ваш код перехоплює цей запит, реально виконує функцію і отримує результат;
результат передається назад у LLM як новий контекст;
модель або формує фінальну відповідь, або просить ще один інструмент.
Тобто LLM просить, але не виконує.
Це принципове розділення, яке робить систему безпечнішою і контрольованою.
Проєктування хороших інструментів (Designing Good Tools)
Щоб агент міг знаходити й коректно використовувати інструменти, їх потрібно чітко і послідовно описувати.
Кожен інструмент складається з двох частин.
1. Інтерфейс для агента
Саме його «бачить» LLM. Він включає:
назву інструменту;
опис простою мовою — коли і навіщо його використовувати;
чітко типізовану схему входів.
Наприклад:
ReadWebsiteContent
Опис: «Завантажує та повертає текст вебсторінки»
Вхідні дані: url (рядок)
2. Реалізація
Це вже ваш код:
SQL-запити;
автентифікація;
повторні спроби;
обмеження частоти;
парсинг результатів тощо.
Агент ніколи не бачить ці деталі — лише чистий і зрозумілий інтерфейс.
Що відрізняє хороші інструменти
Добре спроєктовані інструменти враховують:
обробку помилок і самовідновлення;
rate limiting;
кешування результатів для однакових запитів (менше затримок, нижча вартість, менше навантаження на API);
асинхронну роботу — щоб агент або інші агенти могли продовжувати роботу, поки інструмент виконується.
У продакшені інструменти варто будувати як продукти:
з версіонуванням;
документацією;
тестами;
зрозумілою відповідальністю за підтримку.
Корисна практика — мати внутрішній реєстр інструментів із описами, версіями та власниками.
Усе це разом дає агенту можливість взаємодіяти з реальним світом, а не лише генерувати текст. Але цього все ще недостатньо.
Щоб агент розумів, що саме і в якій послідовності робити, нам потрібен третій дизайн-патерн — planning.
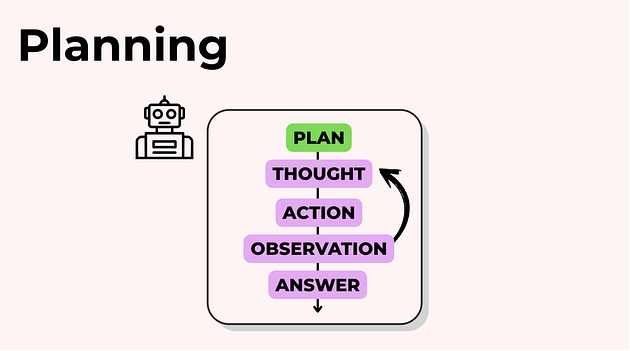
Planning: планування дій
Ідея планування проста:
замість того щоб жорстко прописувати фіксований набір кроків, ви дозволяєте LLM самій визначати, що робити і в якому порядку — залежно від задачі, контексту і проміжних результатів.
Далі цей патерн ми розберемо детальніше.
Уявімо, що ви будуєте агент служби підтримки для роздрібного магазину.
Можна піти простим шляхом і жорстко прописати сценарії:
якщо питання про ціну — робимо X;
якщо повернення — робимо Y;
якщо наявність товару — робимо Z.
Але що відбувається, коли:
користувач ставить питання, яке ви не передбачили?
одна й та сама тема потребує різних кроків залежно від контексту?
Саме тут і з’являється planning.
Замість фіксованих сценаріїв ви даєте агенту набір інструментів, наприклад:
get_item_descriptions;check_inventory;get_item_price;process_return.
А далі дозволяєте йому самому визначати, які інструменти використати і в якій послідовності.
Базовий цикл planning
Типовий цикл виглядає так:
ви надаєте агенту доступ до інструментів;
просите його побудувати план:
«Опиши покрокові дії, щоб відповісти на це питання»;ви виконуєте план крок за кроком:
модель обирає інструмент → ви його запускаєте → результат повертається в контекст;цикл повторюється, доки задача не буде завершена.
По суті, це той самий підхід «plan → act → observe → continue», але з вашими реальними інструментами.
Конкретний приклад: магазин сонцезахисних окулярів
Користувач питає:
«Є круглі сонцезахисні окуляри в наявності до $100?»
Агент може побудувати такий план:
використати
get_item_descriptions, щоб знайти моделі з круглою оправою;перевірити їх наявність через
check_inventory;отримати ціни через
get_item_priceі відфільтрувати варіанти до $100;сформувати відповідь.
Ви не прописували цей рецепт наперед — агент сам його склав із доступних інструментів.
Тепер надходить інше питання:
«Я хочу повернути золоті окуляри, які купував раніше, не металеві».
План буде зовсім інший:
знайти попередні покупки користувача;
ідентифікувати модель із золотою оправою;
викликати
process_item_return;підтвердити результат користувачу.
Ті самі інструменти — але інша логіка і послідовність дій.
Структуровані плани
Корисна практика — просити модель виводити план у структурованому вигляді, наприклад у JSON.
Це:
спрощує виконання кроків;
дозволяє перевіряти план до запуску;
робить систему прозорішою і безпечнішою.
Planning — це ключовий патерн, який дозволяє агентам адаптуватися до нових запитів без нескінченних if/else і переписування логіки.

Або ж можна піти ще на крок далі — дозволити агенту згенерувати сам план у вигляді коду.
Найчастіше це Python-код, який:
описує всю послідовність дій;
викликає потрібні інструменти;
обробляє проміжні результати;
формує фінальний вихід.
У такому підході код фактично стає матеріалізованим планом.
Ви можете:
переглянути його перед виконанням;
обмежити доступні бібліотеки;
виконувати його в ізольованому середовищі;
логувати кожен крок.
Це підвищує гнучкість і виразність planning-патерну, але водночас:
збільшує складність системи;
потребує суворих обмежень і guardrails.
Тому генерація коду як плану зазвичай використовується там, де потрібна максимальна автономність і контроль — і де ви готові інвестувати в безпеку та перевірки.

На що звертати увагу під час planning
Planning підвищує автономність агентів — а разом із цим зростає і непередбачуваність. Тому тут критично важливі:
чіткі дозволи (що агент може і не може робити);
валідація викликів інструментів;
контроль передачі результатів з одного кроку на наступний.
Сьогодні найсильніший практичний кейс для planning — це високoагентні системи для програмування. Модель сама розбиває задачу на підзадачі й поступово їх реалізує.
В інших доменах planning теж працює, але керувати ним складніше — ви не знаєте наперед, який саме план побудує модель. Втім, інструменти, guardrails і практики контролю швидко розвиваються, і впровадження таких систем зростає.
Але що робити, якщо система має виконувати багато різних задач, інколи паралельно?
Тут на сцену виходить multi-agent collaboration.
Multi-agent системи
Подумайте, як ви вирішуєте складні проєкти в реальному житті.
Ви не наймаєте одну людину «на все». Ви збираєте команду.
Є спеціалісти, кожен з яких добре робить свою частину роботи, і вони передають результат один одному.
Multi-agent системи працюють за тим самим принципом.
Кожен агент:
має чітку роль;
фокусується на своїй сильній стороні;
передає результат далі по ланцюжку.
Завдяки спеціалізації підсумковий результат стає кращим.
Додаткові переваги multi-agent підходу
Окрім спеціалізації, є й інші важливі плюси:
не потрібно тримати весь контекст в одному агенті;
можна використовувати різні моделі:
швидкі й дешеві — для масових простих задач,
потужніші — для точних, чутливих або стратегічних рішень;можливість паралельної роботи;
прозорість у довгих процесах — видно, який агент чим займається.
Коли multi-agent — погана ідея
Якщо задача проста — не використовуйте multi-agent.
Він:
уповільнює систему;
ускладнює дебаг;
додає зайву інфраструктурну складність.
Multi-agent системи створюють нові виклики:
конфлікти ресурсів (два агенти змінюють один файл);
накладні витрати на комунікацію;
складні залежності між задачами;
обмеження API;
питання відмов: якщо один агент впав — що робити іншим?
як обʼєднати результати кількох агентів в один цілісний вихід?
Усе це керовано, але лише за умови свідомого дизайну:
чіткої оркестрації;
продуманого оброблення помилок;
зрозумілих протоколів комунікації.
Проєктування multi-agent систем
Розглянемо, як підходити до дизайну таких систем на практиці.
Візьмемо приклад — створення маркетингового буклета.
Модель ролей (Roles Model)
Перший крок — визначити агентів за ролями.
Кожен агент:
має чіткий опис завдань;
отримує лише ті інструменти, які потрібні для його роботи.
Для маркетингового буклета це може виглядати так:
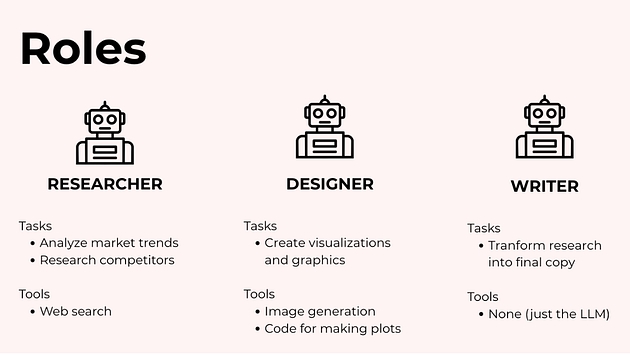
Дослідницький агент
Шукає ринкові тренди та дії конкурентів.
Інструменти: вебпошук, retrieval, нотатки.
Агент-дизайнер
Створює графіки й візуальні матеріали.
Інструменти: генерація зображень, обробка зображень, виконання коду для побудови графіків.
Агент-райтер
Перетворює дослідження та візуали на фінальний текст.
У простому варіанті йому може бути достатньо самої LLM без зовнішніх інструментів.
Це базовий, але дуже ефективний спосіб мислення: не “один розумний агент”, а команда з чіткими ролями.
Кожного агента ви реалізуєте через промпт, який задає роль і межі.
Наприклад: «Ти — дослідницький агент, спеціалізований на аналізі ринку» — і далі надаєте йому лише ті інструменти, які потрібні цій ролі.
Після того як ролі визначені, постає наступне ключове питання:
як агенти будуть обмінюватися результатами?
Існує чотири основні патерни комунікації — від найпростішого до найскладнішого. Розглянемо їх по черзі.
Патерн 1: Послідовний (Sequential)
Це найпростіший і найпередбачуваніший варіант.
Логіка така:
перший агент виконує свою частину роботи;
передає результат наступному агенту;
той робить свою частину і передає далі — і так по ланцюжку.
Плюси послідовного підходу:
легше контролювати процес;
зрозуміло, хто за що відповідає;
простіше дебажити, бо помилки видно на конкретному етапі.
Це хороший стартовий шаблон для більшості мультиагентних систем, особливо коли задача має природну послідовність (дослідження → структура → текст → перевірка/редагування).
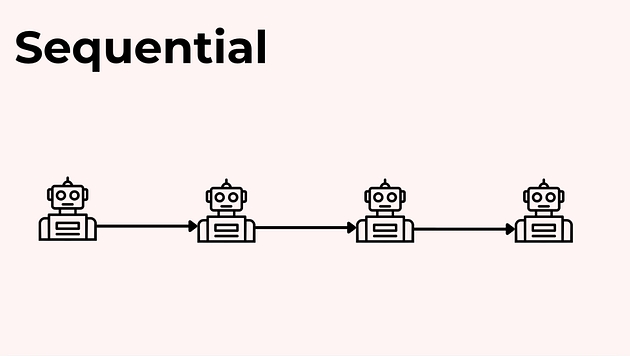
Для нашого прикладу з маркетинговим буклетом послідовний сценарій може виглядати так:
Дослідник завершив → передав дизайнеру → дизайнер завершив → передав райтеру → готово.
Фактично це конвеєр, як на виробництві.
Його сильні сторони:
легко дебажити (видно, на якому етапі зіпсувалася якість);
передбачувані час і вартість;
зрозумілий контроль — кожен етап має свій результат.
Саме з цього варіанту найкраще починати. Для багатьох задач цього патерну достатньо — і не потрібно ускладнювати систему.
Патерн 2: Паралельний (Parallel)
Але послідовність — не єдиний варіант.
Коли кроки не залежать один від одного, агентів можна запускати паралельно.
Головний бонус — менша затримка: замість чекати, поки все пройде по ланцюжку, частина роботи робиться одночасно.
Цей підхід особливо корисний там, де багато підзадач можна виконати незалежно: наприклад, одночасно зібрати тренди, проаналізувати конкурентів і підготувати чернетку структури.
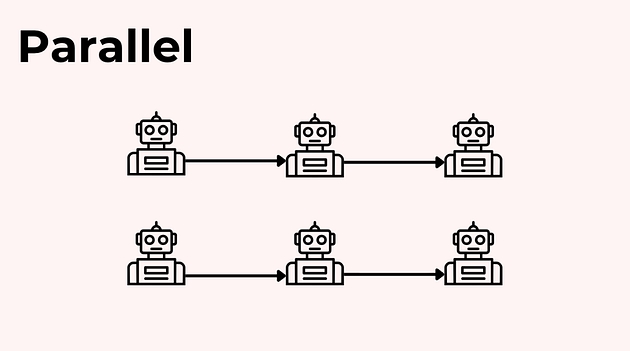
Наприклад, дослідницький агент і дизайнер можуть працювати одночасно над незалежними частинами буклета, а райтер уже потім обʼєднує їхні результати в цілісний текст.
Це помітно прискорює процес, але має зворотний бік —
зростає складність координації. Потрібно чітко визначити:
у якому форматі агенти віддають результат;
коли робота вважається завершеною;
як обʼєднувати вихідні дані без втрат.
Патерн 3: Ієрархія з одним менеджером (Single Manager Hierarchy)
Коли робочі процеси стають складнішими, зʼявляється сенс додати менеджер-агента.
У цій моделі:
менеджер планує та координує роботу;
спеціалізовані агенти виконують свої задачі;
усі результати повертаються менеджеру, а не передаються між агентами напряму.
Менеджер:
вирішує, кому і що робити;
перевіряє проміжні результати;
інтегрує все в єдиний фінальний вихід.
Такий підхід зменшує хаос у комунікації й робить систему більш керованою — особливо коли кількість агентів і підзадач зростає.
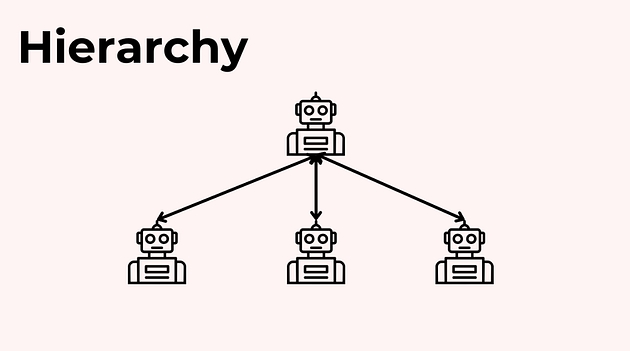
Такий підхід дозволяє тримати процес під контролем, не жертвуючи гнучкістю.
Менеджер-агент може:
змінювати порядок кроків;
пропускати етапи, які виявилися непотрібними;
просити окремих агентів переробити роботу.
У результаті система стає адаптивнішою, ніж жорсткий лінійний сценарій, але при цьому не перетворюється на хаос.
Саме тому ієрархія з одним менеджером сьогодні є, ймовірно, найпоширенішим патерном у продакшен-multi-agent системах.
Для ще складніших процесів можливі глибші ієрархії, де деякі агенти не лише виконують задачі, а й керують власними під-агентами.
Це вже схоже на організаційну структуру з кількома рівнями управління — і потребує ще більш продуманої оркестрації.
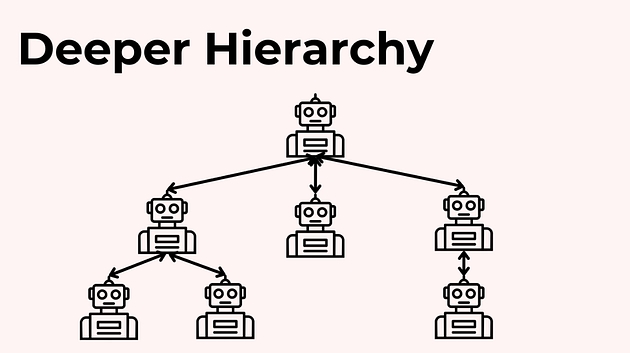
Наприклад, дослідницький агент може сам координувати:
під-агента для вебдосліджень;
під-агента для фактчекінгу.
А райтер — мати під собою:
агента, який відповідає за стиль;
агента, що перевіряє коректність цитувань і посилань.
Такий підхід корисний для дуже складних задач, де потрібна глибока спеціалізація. Але ціна за це — зростання складності й “ентропії” системи. Чим більше рівнів і взаємозв’язків, тим важче все тримати під контролем.
Патерн 4: All-to-All (вільний чат між агентами)
І нарешті — найбільш хаотичний варіант.
У all-to-all моделі будь-який агент може писати будь-якому іншому агенту в будь-який момент. Немає чіткої ієрархії, немає одного координатора, немає фіксованого маршруту даних.
Цей підхід:
максимально гнучкий;
але майже непередбачуваний.
Результати можуть сильно відрізнятися від запуску до запуску, а контроль і відтворюваність стають проблемою.
Саме тому all-to-all практично не використовується в продакшені.
Його іноді застосовують для експериментів, досліджень або креативних задач, де варіативність важливіша за стабільність.
Водночас all-to-all може працювати для:
брейнштормінгу;
креативних задач;
low-stakes сценаріїв.
Наприклад, генерація десятків варіантів рекламних текстів. Якщо один запуск видав сміття — нічого страшного, можна просто перезапустити.
Типові проблеми координації
Ми вже кілька разів торкалися теми координації. Ось дві найпоширеніші пастки.
1. Дублювання роботи
Кілька агентів можуть:
виконувати ті самі пошуки;
викликати одні й ті самі інструменти;
повторювати однакові обчислення.
Рішення:
чітко звузити зони відповідальності;
задати явний поділ ролей і задач;
уникати «розмитих» формулювань типу “досліди тему”.
2. Зайва послідовність
Іноді кроки, які можна виконувати паралельно, штучно з’єднують у ланцюжок — і система сповільнюється.
Рішення:
визначити справді незалежні підзадачі;
запускати їх асинхронно;
передавати далі лише той контекст, який реально потрібен наступному кроку.
Загальне правило просте:
починайте з найпростішого способу координації і додавайте складність лише тоді, коли без неї справді не обійтися.
Best practices для multi-agent систем
Незалежно від того, який патерн ви обрали, є чотири практики, які варто дотримуватися завжди.
1. Визначайте інтерфейси, а не “вайб”
Кожен агент має чітко знати:
які поля він отримує;
які типи даних;
які ідентифікатори або посилання передаються далі.
Найчастіше ламаються не моделі, а передачі між агентами.
Якщо дослідник віддає неструктурований текст, а дизайнер не знає, як його парсити — система розвалюється.
2. Обмежуйте інструменти для кожного агента
Давайте агенту лише ті інструменти, які йому реально потрібні — принцип мінімальних прав.
Це:
підвищує безпеку;
спрощує логіку;
полегшує аудит і дебаг.
3. Логуйте trace
Зберігайте артефакти кожного кроку:
який план створив агент;
які промпти використовував;
які інструменти викликав;
які результати отримав.
Коли щось ламається, trace дозволяє швидко побачити точку збою, а не гадати навмання.
4. Оцінюйте компоненти і систему загалом
Потрібні два типи оцінювання:
На рівні компонентів:
релевантність дослідження;
якість візуалів;
тон і стиль тексту.
End-to-end:
чи хороший фінальний результат;
чи відповідає вимогам;
чи вирішує задачу.
Якщо end-to-end оцінка погана, але всі компоненти виглядають норм — проблема в інтеграції.
Якщо падає конкретний компонент — зрозуміло, якого агента покращувати.
ADVANCED
Ласкаво просимо до просунутого рівня.
Якщо ви дійшли сюди, ви вже не експериментуєте — ви будуєте системи, які мають працювати в реальному середовищі.
Те, що допомагає перейти від нуля до прототипу, не підходить для переходу від прототипу до продакшену.
Потрібні:
інші інструменти;
інше мислення;
значно більше дисципліни.
Переходимо до цього.
Просунута декомпозиція задач у multi-agent системах
Ми вже говорили про декомпозицію задач. Але в multi-agent системах вона стає набагато складнішою.
Є чотири базові патерни, які допомагають робити це правильно
(цей блок адаптований з одного сильного технічного блогу).
Патерн 1: Функціональна декомпозиція (Functional Decomposition)
У цьому підході задачі розбиваються за типом експертизи або технічним доменом.
Саме це ми використовували в попередніх прикладах:
дослідження;
дизайн;
написання тексту;
перевірка.
Тобто кожен агент відповідає за тип роботи, а не за етап процесу.
Це найбільш інтуїтивний і зрозумілий спосіб старту — і саме з нього зазвичай починають.
Приклад: функціональна декомпозиція на практиці
Уявіть full-stack розробку фічі.
Тут є різні типи роботи, які потребують різних знань і інструментів:
фронтенд;
бекенд-логіка;
зміни в базі даних;
оновлення API.
У такому випадку логічно створити агентів, спеціалізованих за доменами — кожен робить свою частину, де він найсильніший.
Патерн 2: Просторова декомпозиція (Spatial Decomposition)
Ще один підхід — розбивка за файлами або директоріями.
Він особливо корисний у великих кодових базах, де багато незалежних частин.
Приклад: масовий рефакторинг — наприклад, оновлення всіх API-ендпоінтів на нову систему автентифікації.
Можлива декомпозиція:
Агент 1 →
/services/users/*Агент 2 →
/services/orders/*Агент 3 →
/services/payments/*Агент 4 →
/services/notifications/*
Переваги:
мінімум конфліктів;
паралельна робота;
зрозуміла зона відповідальності.
Обмеження:
якщо файли сильно залежать один від одного, просторовий підхід починає ламатися.
Патерн 3: Часова декомпозиція (Temporal Decomposition)
Тут задачі розбиваються на послідовні фази, де кожна наступна залежить від попередньої.
Приклад — запуск продукту:
Фаза 1: Дослідження ринку
Аналіз конкурентів, опитування ЦА, пошук позиціонування.
Фаза 2: Планування запуску
Меседжинг, ціни, таймлайн, канали.
Фаза 3: Створення матеріалів
Тексти, дизайн, лендинги, email-ланцюжки.
Фаза 4: Запуск і моніторинг
Кампанія, метрики, реакція на фідбек, корекції.
Кожна фаза має свого агента або групу агентів.
Наступна не стартує, доки попередня не завершена й не перевірена.
Патерн 4: Декомпозиція за даними (Data-Driven Decomposition)
Менш поширений, але дуже потужний підхід для задач із великими обсягами даних.
Приклад — аналіз логів за місяць.
Розбиття:
Агент 1 → логи тижня 1
Агент 2 → логи тижня 2
Агент 3 → логи тижня 3
Агент 4 → логи тижня 4
Кожен агент аналізує свою частину незалежно, після чого результати агрегуються.
Патерни можна комбінувати.
Наприклад: загальна структура — функціональна, а всередині бекенду — часова декомпозиція (дизайн → реалізація → тести).
Як підвищувати якість, якщо система вже працює
Припустимо, система працює, оцінювання проведене, але якість усе ще не влаштовує.
Важливо зрозуміти: у вас є два принципово різні типи компонентів, і покращуються вони по-різному.
1. Non-LLM компоненти
Це:
вебпошук;
RAG-retrieval;
виконання коду;
розпізнавання мови;
vision-моделі;
PDF-парсери.
Два основні шляхи покращення:
налаштування параметрів: top-k, chunk size, similarity threshold, діапазони дат;
заміна провайдера: інший пошук, інша OCR або vision-модель.
2. LLM-компоненти
Там, де модель:
генерує;
витягує дані;
міркує;
синтезує.
Тут можливостей більше:
покращити промпти (інструкції, обмеження, схеми, few-shot);
спробувати іншу модель (одна краще пише код, інша — факти);
додатково декомпозувати складні задачі;
fine-tuning — лише в кінці, для зрілих систем, коли інше вже вичерпано.
Зменшення затримки (Latency)
Спочатку — якість. Потім — швидкість.
1. Отримайте базову метрику
Заміряйте час кожного кроку:
генерація запитів → пошук → драфт → reflection тощо.
2. Паралелізуйте
Веб-запити, завантаження сторінок, парсинг документів — часто це найпростіший виграш.
3. Підігнайте модель
Малі, швидкі моделі — для простих задач.
Великі — лише для синтезу та складного reasoning.
4. Спробуйте швидших провайдерів
Різниця у стримінгу та throughput може зекономити секунди без змін у промптах.
5. Скорочуйте контекст
Менше токенів → швидше декодування.
Зменшення вартості (Cost)
Коли якість і затримки під контролем — час рахувати гроші.
Основні джерела витрат:
LLM-виклики (input дешевші, output дорожчі);
API-виклики (пошук, PDF, зображення, STT);
інфраструктура (вектори, виконання коду, зберігання).
Для прикладу — один прогін дослідницького агента, який пише есе, може виглядати так:
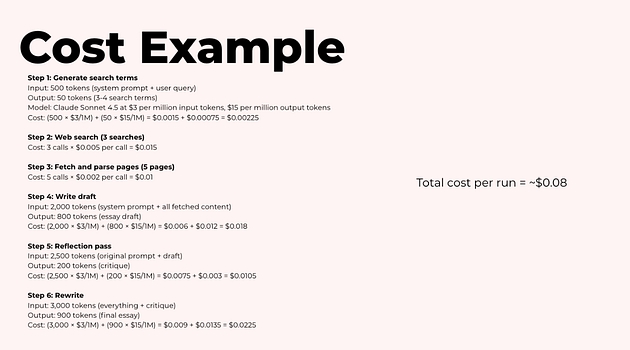
З такого розкладу легко побачити:
де найбільше витрат;
що оптимізувати в першу чергу (модель, reflection, пошук, кількість сторінок).
Якщо запускати такий агент 1 000 разів на день, отримаємо приблизно:
$80 на день
або близько $2 400 на місяць
І саме в цей момент більшість команд починають мислити інакше.
Коли витрати переходять із «експериментальних» у операційні, стає критично важливо:
зменшувати кількість зайвих проходів (reflection, rewrite);
скорочувати контекст;
замінювати великі моделі там, де вони не потрібні;
кешувати результати;
зменшувати кількість зовнішніх API-викликів.
Агентна система може бути дуже потужною — але без контролю вартості вона швидко стає економічно невигідною.
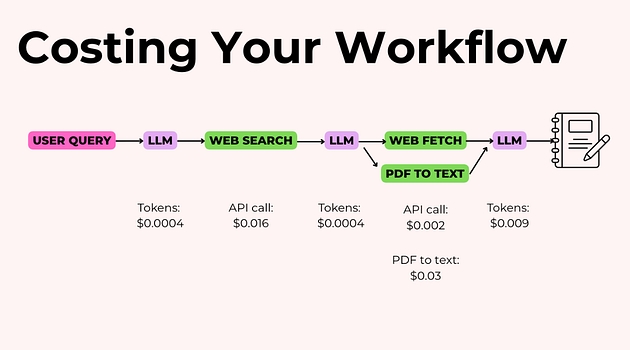
Коли ви вже знаєте, скільки коштує кожен крок, ось що можна зробити для оптимізації.
Як зменшувати витрати
Починайте з найбільших статей витрат.
Якщо вебпошук коштує $0,02 за виклик, а ви робите його 10 разів за один запуск — це вже $0,20.
Що можна зробити:
зменшити кількість викликів;
кешувати результати;
обʼєднувати запити.
Розділяйте моделі за рівнями.
Дешеві моделі — для простих задач.
Потужні — лише там, де справді потрібні складне мислення або синтез.
Агресивно використовуйте кешування.
Детерміновані результати не повинні рахуватися щоразу:
відповіді пошуку;
embeddings;
retrieval-чанки;
проміжні саммарі.
Обмежуйте формат і обсяг виходу.
Чіткі інструкції типу:
«Поверни JSON з цими полями»;
«Не більше 5 пунктів»
→ менше токенів → менший рахунок.
Пакетна обробка (batching).
Якщо обробляєте багато схожих елементів — обʼєднуйте операції.
Наприклад, у хмарній інфраструктурі пакетна обробка може бути значно дешевшою за on-demand.
Observability та моніторинг
Припустимо, ви задоволені:
якістю;
затримками;
вартістю.
Тепер головне — переконатися, що система поводиться так само добре після масштабування.
Саме тут потрібні observability та monitoring.
Observability охоплює:
дебаг;
контроль якості;
відстеження галюцинацій;
загальну поведінку агентів.
І тут є важливий момент:
observability для AI-систем принципово відрізняється від класичного софту.
Чому AI-системи складніші для спостереження
У традиційному ПЗ все більш-менш лінійно:
функція A → функція B → база → результат.
AI-системи інші:
вони недетерміновані — той самий запит може дати різні результати;
виконання розподілене — інструменти, паралельні виклики, під-агенти;
багато зовнішніх залежностей, які ви не контролюєте;
і ще багато дрібних факторів.
Тому потрібні два рівні видимості.
“Zoom-in” метрики — для дебагу
Вони допомагають розібрати окремий запуск:
повний trace;
промпти;
виклики інструментів;
використання токенів;
ретраї;
точки прийняття рішень.
Це все, що потрібно, щоб відтворити помилку і зрозуміти, де саме система пішла не так.
“Zoom-out” метрики — для системного контролю
Вони показують, як система поводиться в цілому:
автоматичні оцінки якості (часто через LLM-judge);
рівень галюцинацій;
показники успіху / ROI;
тренди: чи покращують зміни систему, чи ламають.
Важливо логувати не лише що агент зробив, а й чому.
Наприклад:
«Агент обрав вебпошук замість RAG, бо в запиті було слово “recent”»;
«Reflection знайшов 3 проблеми: відсутнє джерело, розмита дата, неправильний тон».
Quality sampling
Коли у вас тисячі запусків, перевіряти кожен вручну неможливо.
Тут використовується sampling:
ви визначаєте відсоток запусків для глибокої перевірки;
система аналізує лише цю вибірку;
на її основі рахується загальний рівень якості та галюцинацій.
Це дозволяє:
пріоритезувати правки;
швидко знаходити слабкі місця.
Поведінка користувачів — не менш важлива
Окрім технічних метрик, потрібно дивитися на реальне використання:
що саме просять користувачі?
чи використовують агента так, як ви планували?
де вони застрягають?
чи переформульовують запити (сигнал, що перша відповідь не спрацювала);
що роблять з результатом — одразу просять правки?
яка довжина сесій?
Короткі сесії можуть означати:
швидкий успіх;
або миттєвий провал.
Довгі — що агент корисний, але неефективний.
Ці якісні сигнали так само важливі для roadmap’у продукту, як і будь-які технічні метрики.
Security: безпека агентних систем
Наостанок — одна з найменш захопливих, але найважливіших тем у побудові надійних агентних систем — безпека.
Безпека для AI-агентів не схожа на класичну безпеку застосунків.
Ви захищаєтесь не лише від зовнішніх атак — вам потрібно захищатися від власної системи, яка може:
прийняти небезпечне рішення;
бути маніпульованою;
виконати шкідливу дію без злого наміру.
Основні ризики, за якими потрібно стежити
Prompt injection
Зловмисний контент у введенні користувача або зовнішніх даних, який «перехоплює» інструкції агента.
Небезпечна генерація коду
Агент може згенерувати код, який:
читає чутливі дані;
виконує небезпечні операції;
виходить за межі дозволеного середовища.
Витік даних
PII або внутрішня інформація, що потрапляє у відповіді агента або передається через інструменти.
Виснаження ресурсів
Нескінченні цикли, дорогі операції, надмірні API-виклики.
Безпечне виконання коду
Виконання коду — найпотужніший інструмент агента.
Він дозволяє:
будувати графіки;
обробляти дані;
генерувати файли;
автоматизувати складні процеси.
Але це двосічна зброя.
Багато задач можна покрити чітко визначеними інструментами, і вільна генерація коду не завжди потрібна.
Якщо ж ви її дозволяєте — guardrails обовʼязкові.
Як виконувати код безпечно
1. Ізольоване середовище (sandbox)
Використовуйте контейнер або обмежений runner.
Код виконується в ізольованому середовищі, яке знищується після кожного запуску.
2. Обмеження ресурсів
тайм-аути;
ліміти памʼяті та CPU;
заборона небезпечних імпортів;
блок мережі, якщо вона не потрібна;
заборона запису у файлову систему поза тимчасовою директорією.
3. Whitelist бібліотек
Дозволяйте лише перевірені бібліотеки (наприклад, pandas, numpy, datetime).
Жодних довільних інсталяцій. Потрібна бібліотека — додається вручну.
4. Validation + reflection loop
Якщо код упав:
збережіть traceback;
передайте його моделі;
дайте 1–2 спроби виправлення;
обовʼязково — circuit breaker.
5. Детермінований ввід/вивід
Код повертає:
число;
список;
JSON.
Форматування для користувача робить система, а не сам код.
Код не пише файли і не виводить дані напряму користувачу.
6. Санітизація вводу й виводу
валідація всіх вхідних даних;
сканування результатів на PII, токени, ключі.
Цим ми завершуємо advanced-частину.
З усіма цими інструментами ви готові будувати реальні агентні системи, які:
масштабуються;
працюють у продакшені;
не ламаються від першого нестандартного сценарію.
BONUS: для дуже просунутих
Увесь матеріал вище передбачає використання фреймворків для агентів.
Але якщо вас цікавить, як агентні системи працюють “під капотом”, варто розібратися з їх внутрішньою архітектурою.
Йдеться про:
поділ на шари (інтерфейс → LLM-логіка → інструменти);
реактивні цикли виконання;
стримінг + tool calling;
паралельне виконання та пріоритизацію інструментів.
Це той самий клас архітектур, який лежить в основі сучасних agentic-IDE та code-assistant систем.

