Чому нам потрібне логування?
В контексті інженерії ПЗ існує термін “black box app" який відноситься до системи, яку можна розглядати за допомогою її вхідних та вихідних даних без будь-якого знання про її внутрішній механізм. Одним із викликів у роботі з такими системами є складність визначення того, що саме відбувається всередині такого, в нашому випадку, додатку.
Тут на допомогу приходить логування. Логування надає можливість перегляду роботи програми під час її виконання та може бути вирішальним для пошуку й усунення проблем, моніторингу та діагностики неполадок. Воно надає інформацію про внутрішню роботу програми під час її роботи. Шляхом запису різних подій та активностей у вигляді логів ми можемо отримати чітку уяву про послідовність виконання та стан системи у різні моменти часу.
Системи логування
Логи можуть зберігатися в різних місцях залежно від вимог. Часто можна побачити логи, які зберігаються в базах даних, файлах та виводяться на консоль. Деякі системи логування також підтримують передачу логів через TCP/IP.
Наприклад, стек ELK (Elasticsearch, Logstash та Kibana) використовує TCP/IP для отримання логів і їх обробки.
Logstash отримує логи по мережі з різних джерел. Він може прослуховувати TCP/IP-порти для отримання вхідних логів. Дані можуть надходити з Filebeat або Logstash Forwarder, встановлених на серверах.
Elasticsearch - це система пошуку та аналітики, де зберігаються оброблені логи з Logstash.
Kibana - це візуалізаційний шар, який надає інтерфейс для пошуку та перегляду логів, збережених в Elasticsearch.
Метрики
Логи є записами подій, які сталися в межах програми, тоді як метрики є числовими значеннями, що представляють певні аспекти системи в конкретний момент часу. Метрики, як правило, використовуються для спостереження за тенденціями та патернами, тоді як логи використовуються для детального аналізу та відлагодження окремих подій.
Наприклад, метрикою може бути кількість викликів до бази даних або кількість отриманих запитів за секунду (rps — requests per second). Ці метрики, коли вони збираються протягом часу, можуть допомогти зрозуміти поведінку та продуктивність додатку.
SLF4J API, Bindings, Implementations
Simple Logging Facade for Java (SLF4J) діє як проміжний шар абстракції. Він сам по собі не реалізує рішення для логування, а надає стандартний інтерфейс, який можуть реалізувати інші системи логування. Іншими словами, SLF4J є фасадом або інтерфейсом для API логування (як Hibernate і JPA).
В контексті SLF4J термін "binding" означає зв'язок між API SLF4J і конкретною системою логування. Термін "binding" відноситься до процесу зв'язування фасаду SLF4J з реалізацією логування, яку ви вибрали для використання в своєму додатку. Кожна система логування (наприклад, Log4j, JDK14L, Logback та інші), яку підтримує SLF4J, вимагає певної прив'язки (binding).
Кілька відомих систем логування, які використовуються як прив'язки SLF4J:
Log4j: Хороша і гнучка система логування. Модуль slf4j-log4j12 з'єднує SLF4J з фреймворком Log4j.
JDK 1.4 logging (JDK14L): Це стандартний інструмент логування в Java. Модуль slf4j-jdk14 зв'язує SLF4J з системою логування JDK.
Logback: Розроблений тим же автором, що й Log4j, Logback вважається його наступником і пропонує значні покращення. Модуль logback-classic служить як прив'язка і реалізація API SLF4J.
Simple: Враховуючи назву, це спрощений логер, який логує всі події додатка до консолі. Модуль slf4j-simple з'єднує Simple логер з SLF4J
Рівні логування
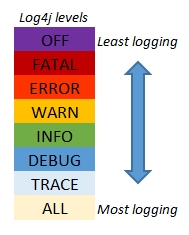
Також, для пошуку і зручності пошуку відповідних повідомлень, придумали рівні логування. Це може дозволяти розробнику контролювати деталізацію логування в його системі.
Коли ми логуємо щось, ми присвоюємо цьому повідомленню відповідний рівень.
Вони не дарма називаються рівнями, тому що чим вище рівень, починаючи від TRACE до FATAL, тим помилка вважається жорсткішою.
Більше того, коли ми будемо підключати систему логування, ми маємо встановити відповідний рівень, який ми хочемо відображати нашому програмісту.
Оскільки, якщо ми вкажемо INFO, то ми будемо бачити ті помилки які є вище — WARN, ERROR, FATAl, а DEBUG і TRACE бачити не будемо.
Налаштування Log4j
Конфігурація Log4j зазвичай(може бути і .properties) здійснюється за допомогою XML-файлу (наприклад, log4j.xml). Основні компоненти, що задіяні в цій конфігурації, - це Appenders, Layouts та Root logger.
Appender — бере повідомлення і відправляє його туди, куди вкажемо. Може бути декілька апендерів. Наприклад, ConsoleAppender, відправляє його в консоль, ніби ми просто використали System.out/err. Формат апендера, ми вказуємо за допомогою об’єкта типу Layout.
Root — сам логер. Root це єдиний логер, хоча їх може бути декілька, так само як і апендерів. Там вказується рівень логування з якого ми починаємо логувати наші повідомлення. І вказуються раніше визначені апендери. Це свого роду фасад, який вирішує куди відправляти повідомлення/за допомогою апендерів.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<appender name="consoleAppender" class="org.apache.log4j.ConsoleAppender">
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d [%t] %-5p %c{1} - %m%n" />
</layout>
</appender>
<root>
<level value="DEBUG" />
<appender-ref ref="consoleAppender" />
</root>
</log4j:configuration>