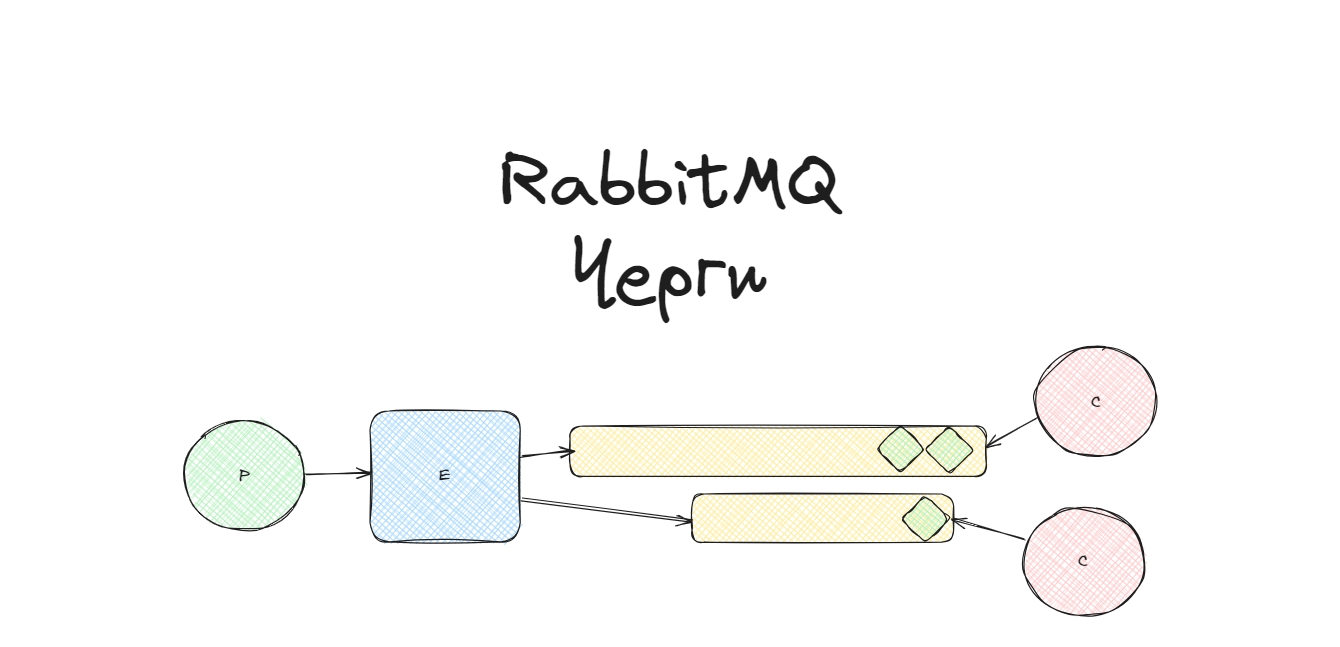
Другий пост про RabbitMQ. Тут я описую які існують черги, чим вони відрізняються і де їх краще використовувати, консенсус алгоритм Raft, типи ановледжментів та конфірмів.
Окрім черг, RabbitMQ може використовувати інші структури, наприклад log структуру, або взагалі не використовувати черги як в MQTT протоколі. Черги є основною структурою даних в RabbitMQ і структурою на якій базується AMQP протокол.
У цьому пості я покриваю лише основні концепціх пов’язані з чергами: струкутра, поведінка, фічі, які вони підтримують. На мою думку тут перелічені необхідні знання, якщо ви працюєте з RabbitMQ.
Типи підтверджень
Як і в Kafka в RabbitMQ використовується система підтверджень (ановледжментів) для забезпечення надійності доставки повідомлень в системі.
Підтвердження це ті повідомлення, які пересилаються між брокером і компонентами для підтвердження успішного зчитування, чи записування повідомлень.
По конвенції RabbitMQ, ановледжменти які використовуються для продюсера називають Confirm, а ановледжі, які використовуються для консюмера називають просто Acknowledment.
Acknowledments:
Automatic Acknowledgement (auto-ack)
Повідомлення вважається підтвердженим відразу після його отримання споживачем.
Використовується, коли не важливо, чи було успішно оброблене повідомлення.
Встановлюється за допомогою параметра
autoAckабоnoAckв методіbasicConsume.
Explicit Acknowledgement (manual ack)
Споживач повинен явно підтвердити отримання повідомлення.
Підтвердження може бути позитивним (
basicAck) або негативним (basicNackабоbasicReject).Використовується для забезпечення надійності доставки, оскільки повідомлення залишається у черзі, поки не буде підтверджене.
Positive Acknowledgement (basicAck)
Підтип explicit acknowledgement
Споживач підтверджує, що повідомлення було успішно оброблене.
RabbitMQ видаляє підтверджене повідомлення з черги.
Negative Acknowledgement (basicNack)
Підтип explicit acknowledgement
Споживач повідомляє RabbitMQ, що повідомлення не було оброблене.
Повідомлення може бути повернене до черги або відкинуте залежно від параметрів.
Використовується з параметрами
requeue(щоб повернути повідомлення до черги) абоmultiple(щоб підтвердити кілька повідомлень одночасно).
Reject (basicReject)
Підтип explicit acknowledgement
Споживач відхиляє повідомлення, повідомляючи RabbitMQ, що його не слід повертати до черги.
Використовується для відхилення повідомлень без можливості повернення до черги.
Можна вказати параметр
requeueдля вирішення, чи слід повернути повідомлення до черги.
Confirms:
Synchronous Confirms:
Продюсер надсилає повідомлення і чекає підтвердження від RabbitMQ перед відправкою наступного повідомлення.
Простий в реалізації, але може знижувати продуктивність через очікування.
Asynchronous Confirms:
Продюсер надсилає повідомлення і продовжує роботу, не чекаючи підтвердження.
Підтвердження обробляються за допомогою колбеків (callback).
Більш продуктивний, але складніший в реалізації та обробці помилок.
Batch Confirms:
Працює як sync так і async для всього батчу.
Продюсер надсилає кілька повідомлень перед тим, як чекати підтвердження для всієї партії.
Баланс між продуктивністю та надійністю.
Класичні черги
Ці черги використовуються за замовчуванням у брокері, їх використовують, коли надійність даних не є в пріоритеті. Класичні черги не реплікуються і реалізовані як FIFO черга.
Класичні черги існують тільки в оперативній пам’яті, тобто при втраті брокера, ви також втратите ваші повідомлення. (Перевірити твердження, бо у V2 пише, що дані підгружаються з диска, можна поестити програмно)
Є дві версії імплементації класичних черг. Ці імплементації відрізняються способом зберігання черг і читання їх з диску. Фічі у обох версіях однакові.
V1
The version can be changed using the queue-version policy key. @RabbitMQ DocV1 наразі є дефолтною версією класичної черги в RabbitMQ.
V1 зберігає повідомлення тільки в оперативній пам’яті, якщо ваш брокер впаде, то ви втратите усі дані, які були в класичних V1 чергах.
Для створення індекса використовується комбінація журналу та файлів сегменту.
Під час читання повідомлень брокер завантажує сегмент у пам’ять. Завантаження всього сегменту може привести до проблем з пам’ятю, але зменшує необхідну кількість виконання I/O операцій.
Версія 1 вбудовує невеликі повідомлення в індекс, що ще більше погіршує проблеми з пам’яттю.
V2
V2 це прокачена версія класичної чеги і її рекомендують використовувати у ваших проеках.
Повідомлення у V2 зберігаються у постійній пам’яті, а підтягуються в оперативну, коли повідомлення потрібне консюмерам.
Індекс у V2 використовує лише файли сегментів і лише за потреби завантажує повідомлення з диска.
Брокер завантажуватиме більше повідомлень на основі поточного рівня споживання.
V2 не вбудовує повідомлення у свій індекс, натомість використовується сховище повідомлень для кожної черги.
The default version can be set through configuration by setting classic_queue.default_version in rabbitmq.conf. @RabbitMQ DocФічі
Queue exclusivity - робить чергу доступною тільки для одного консюмера.
Queue and message TTL (Time to live) - параметр, який вказує скільки повідомленю, або даним залишилось існувати (Схоже на retention policy в Kafka)
Queue length limits - обмежує кількість повідомлень в чергі.
Коли черга досягає свого лімітного розміру, нові повідомлення обробляються відповідно до налаштованої політики. Продюсер, який намагається відправити повідомлення в переповнену чергу, може отримати різні результати залежно від налаштувань черги.
Також може бути налаштована одна з двох політик на видалення вже збережених найстаріших, або наймолодіших повідомлень, що дозволить тримати чергу обмеженую по розміру, але продовжувати обробляти нові повідомлення.
Звісно RabbitMQ можна налаштувати так, щоб при забитій черзі просто відправляти продюсеру негативний ановледжмент (Nack) і не зберігати нового повідомлення.
Message priority - робить чергу пріоритетною. Корисно, якщо треба швидко реагувати на певні повідомлення.
Consumer priority - це параметр пріоритетності споживача, який визначає, який консюмер отримає повідомлення першим.
RabbitMQ віддасть перше повідомлення консюмеру у якого найвищий пріоритет, друге другому по пріоритету і так дальше, використовуючи раунд-робін з пріоритетами.
Controlled using policies - дозволяє змінювати політики/конфігурації брокера в реальному часі.
Dead letter exchange (Без at-least-once dead-lettering) - механізм, який дозволяє перенаправляти повідомлення, які не змогли обробитись у інший exchange. Дозволяє побудувати більш надійну систему з додатковою обробкою невдалих повідомлень.
Кворум черги
Основна відмінність між кворум-чергами та класичними чергами полягає в тому, що кворум-черги використовують розподілені алгоритми консенсусу, що дозволяю створити білш надійну систему, вони автоматично реплікуються, автоматично відновлюються після відмов, що робить їх більш найдіними, та можуть досягти кращої продуктивності при великих обсягах повідомлень та великих навантаженнях завдяки розподіленому збереженню та оптимізованим механізмам реплікації.
Кворум черги по механізму своєї реплікації схожі на Kafka, але Kafka використовує дещо модифікований протокол Raft. Для того, щоб зрозуміти, як працюють кворум черги необхідно зрозуміти, як працює Raft.
Використання кворум черг пов'язане з вищими вимогами до ресурсів, можливим збільшенням затримок, зниженням продуктивності, складністю налаштування і управління, а також залежністю від кількості вузлів. Вибір кворум черг має бути обґрунтованим, виходячи з вимог до надійності і доступності системи, а також з урахуванням можливих недоліків.
Raft консенсус алгоритм
Кворум черги базуються на консенсус алгоритмі Raft (Replicated and fault tolerant). У цьому блоці я детально розглядаю Raft консенсус алгоритм, бо без нього неможливо зрозуміти кворум черги.
Консенсус алгоритми створенні для того, щоб компоненти у розпоідленій системі могли узгоджуватись між собою: узгоджувати дані, які містять ноди, узгоджувати інформацію про самі ноди.
Ноди у кластері повинні перебувати у одному з трьох станів:
Лідер
Послідовник / Фоловер
Кандидат
Алгоритм:
Всі ноди у кластері створюються як фоловери.
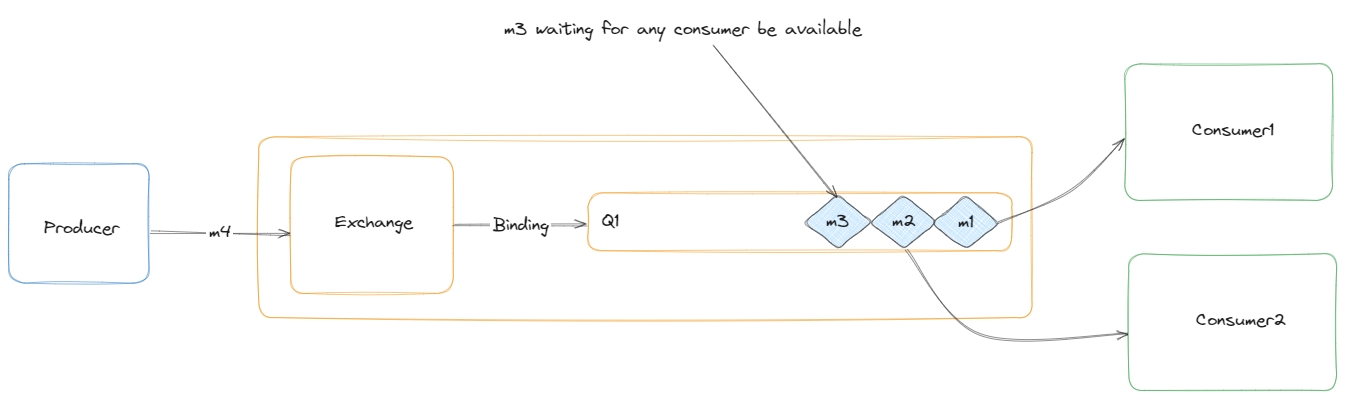
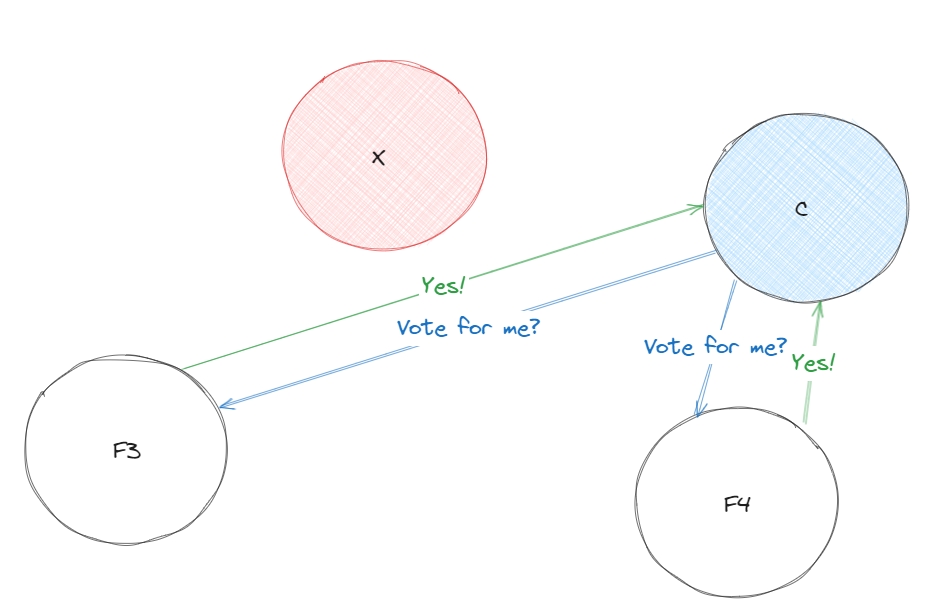
Один із фоловерів, випадковою вибіркою, стає кандидатом і починає голосування за його роль, як лідера. Кандидат голосує сам за себе. Так як ноди ще ні за кого не голосували, то вони проголосують за кандидата.
У кожного фоловера є таймаут по якому він отримує запит на голос від кандидата, якщо за умовних 150 - 300 мс F3 не отримав запит на голос за C, то вважається, що F3 не проголосувала за C.
Для того, щоб голосування вважалось дійсним, у кандидата має бути більшість голосів: Наприклад на діаграмі C достатньо отримати голос від F2 та F3, щоб разом з голосом за самого себе отримати 3 необхіднийх голосів з 4 можливих.
Також у кожної ноди є term (часовий термін) це те, що вказує певну епоху в житті ноди. Після кожного голосування всі ноди інкрементують свій термін. Завдяки цим термінам можна відслідкувати зміну лідерів у історії.
Ноди разом з повідомленням шлють свої term. Якщо нода бачить повідомлення з більшим терміном, ніж власний, вона оновлює свій терм і, якщо нода була лідером, переходить до стану послідовника. Це потрібно для випадків, коли стара мертва нода-лідер відновилась і хоче доєднатись до системи, коли вже був вибраний новий лідер.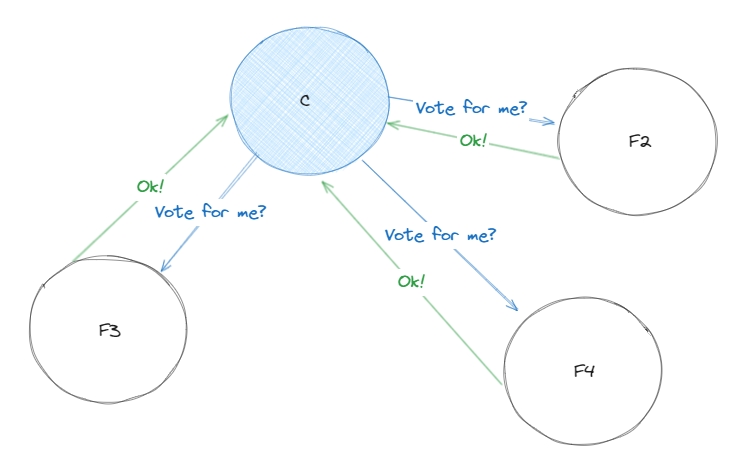
Кандидат отримує достатню кількість голосів та стає лідером. З моменту, як кандида став лідером, він починає відправляти повідомлення фоловером про дані.
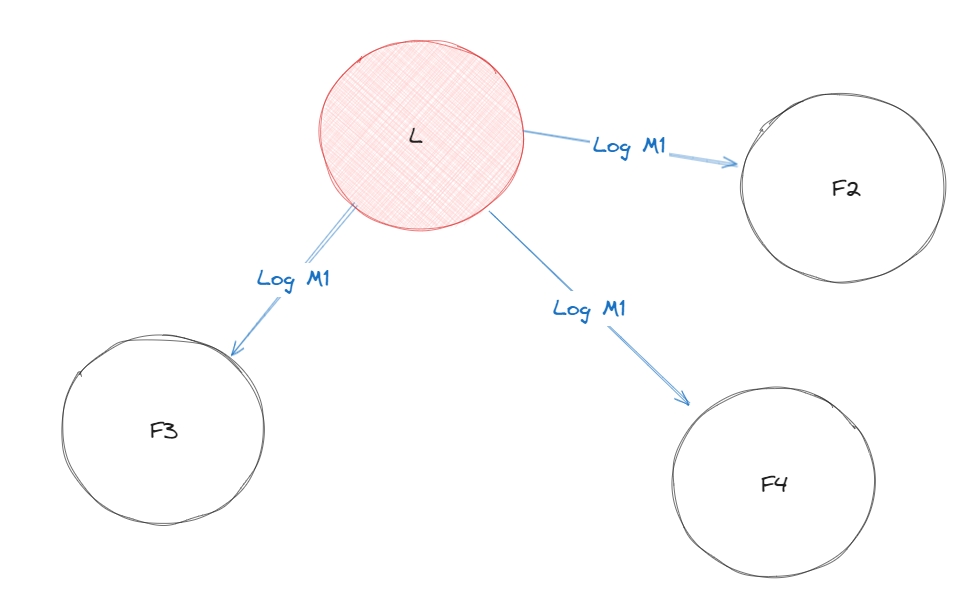
Коли у лідера немає даних, які треба відправити фоловерам, то він відправляє heartbeat, щоб консюмери знали, що лідер досі існує та не почали вибори нового лідера.
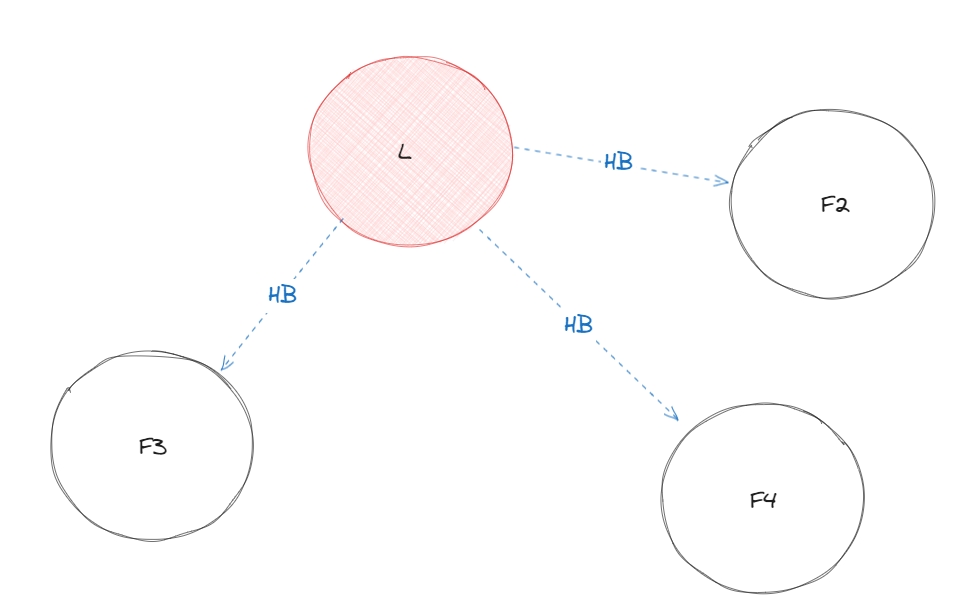
Якщо лідер помре, тобто фоловери деякий час не будуть отримувати heartbeat, то система знову вибере випадкового кандидата за якого почнеться голосування.
Таким чином створеться новий лідер і система продовжить працювати.
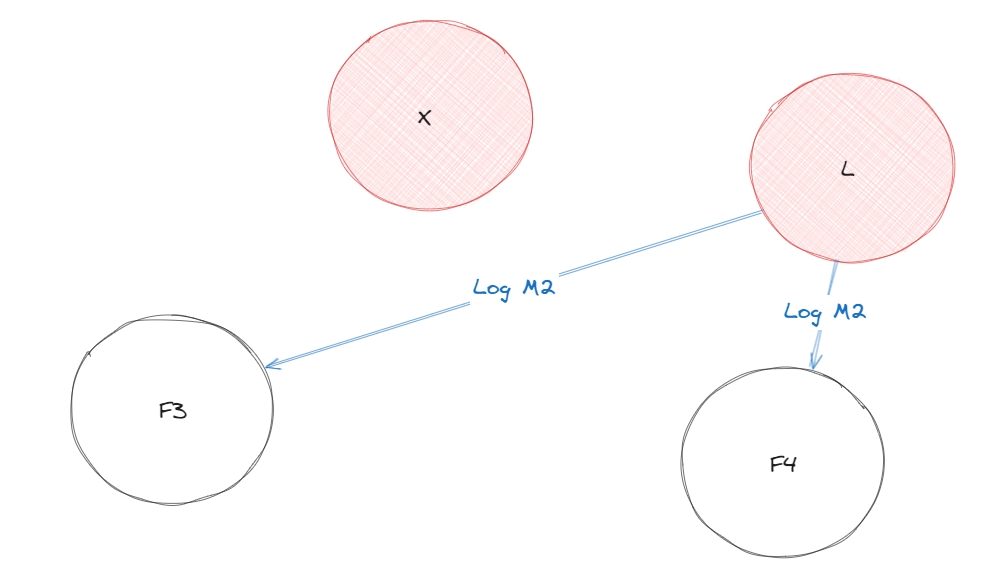
Завдяки цьому алгоритму кворум черги є дуже надійною структурою в RabbitMQ, що дозволить і легше відновлюватись чергам і збільшить надійність самих даних.
Lazy черги
Lazy черги це класичні черги, які виконуються в lazy режимі, тобто це більш модифікація черги, ніж окрема структура.
Коротко цей тип черг був описаний у фічах класичних черг.
Lazy mode є дефолтним модом для класичної черги V2.
Цей тип черг оптимізований для зберігання даних на диску замість оперативної пам’яті.
Повідомлення в Lazy чергах зберігаються на диску одразу після надходження, що знижує навантаження на оперативну пам'ять і підгружають в оперативну пам’ять тільки тоді, коли консюмер почне споживати їх. Це дозволяє обробляти величезні обсяги даних без ризику впертись в розмір оперативної пам’яті.
Такий підхід може знизити швикдість обробки даних через постійну загрузку і вигрузку з постійної пам’яті, але дозволить не втрачати повідомлення через забиту ОП.
Пріоритетні черги
Пріоритетні черги, як і Lazy черги, це класичні черги з модифікацією.
Коротко цей тип черг був описаний у фічах класичних черг.
Повідомлення з вищим пріоритетом будуть доставлені споживачам раніше, ніж повідомлення з нижчим пріоритетом, незалежно від порядку їх надходження в чергу. Такий підхід дозволяє швидко реагувати на специфічні повідомлення.
Доступно 1-255 рівнів для пріоритетів, але рекомендується використовувати 1-5.
Недолік такої системи у планувані ресурсів, повідомлення з низьким пріоритетом можуть довго оброблятись, або не оброблятись взагалі, бо повідомлень з вищим пріоритетом буде забагато.
Нотатка
Окрім черг, RabbitMQ може використовувати log append-only структуру, як в Kafka, завдяки плагіну RabbitMQ Streams. Я дещо поверхам оглянув RabbitMQ Streams як окремий протокол обміну даними у своєму пості про протоколи.
Важливо розуміти, що RabbitMQ дозволяє побудувати комплексну систему обміну повідомлень, використовуючи декілька, або всі види черг одночасно, щоб вирішувати різні проблеми всередині однієї системи. Вибір кожної черги повинен бути виправданим та аргументованим, щоб ваші черги не були надлишковими у системі.

