
У світі сучасної розробки програмного забезпечення версіонування API вже давно є нормою. Ця практика дозволяє розробникам забезпечувати зворотну сумісність і безперебійність роботи сервісів під час оновлень. Якщо ви цього ще не робите - почніть вже зараз.
Але як на рахунок версіонування повідомлень у системах обробки подій, таких як RabbitMQ? Це питання стає особливо актуальним, коли потрібні зміни, а повідомлення одного відправника (producer) читають багато споживачів (consumer).
План
Ми почали думати, як то зробити вірно. Перше, що зробили - звісно, гугл. Ось найпоширеніші підходи до версіонування повідомлень:
Дублювання повідомлень для різних версій: цей метод передбачає одночасну відправку в чергу повідомлень обох версій, які потім фільтруються на стороні обробника. Цей підхід не ефективний для високонавантажених систем через зайве використання ресурсів. При такому підході ми дублюємо повідомлення, що дуже не ефективно в високонавантаженій системі.
Відправка нових версій повідомлень у нову чергу: нові версії повідомлень відправляються в окрему чергу, до якої підключаються обробники, коли вони готові працювати з новою версією. Це ускладнює управління чергами і потребує додаткового моніторингу. І також із проблем - дивись пункт один.
На зараз ми прийшли до іншого способу. Використовується він в інших компаніях чи ні - я не знайшов. Та вважаю, це те, що нам підійде (як мінімум - ми спробуємо саме з ним).
Отже, наш підхід. Він базується на принципах семантичного версіонування (https://semver.org/lang/uk/) та має на меті оптимізувати використання ресурсів, зберігаючи при цьому гнучкість та зворотну сумісність:
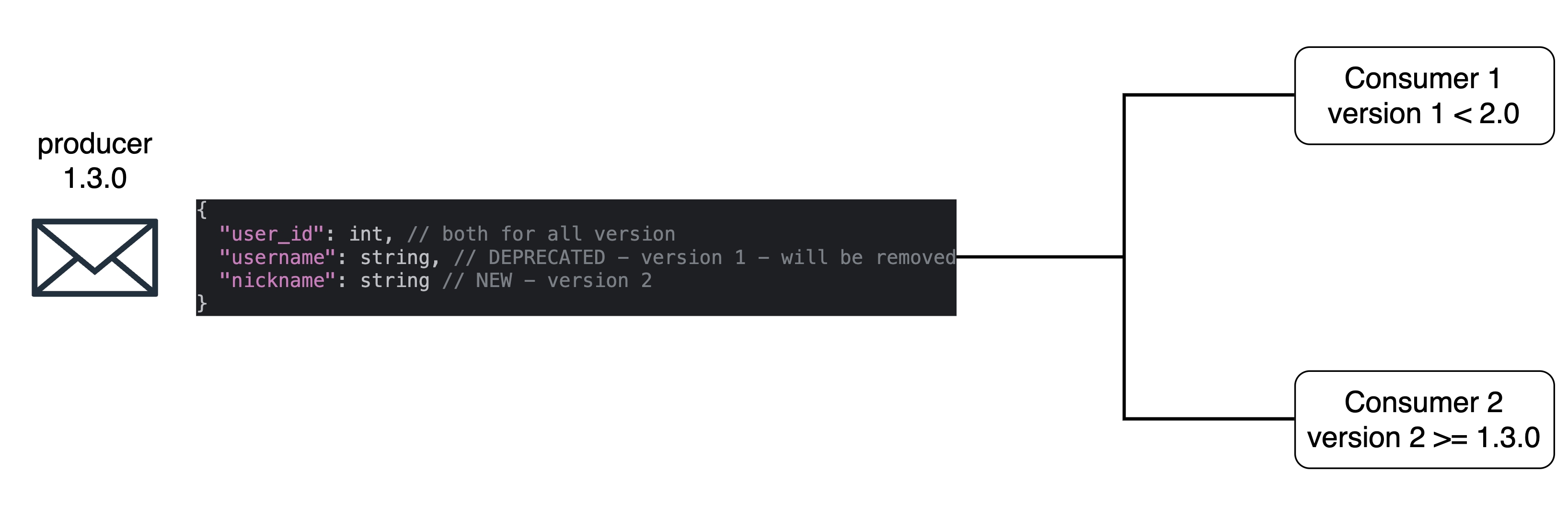
Використання мінорних оновлень для неламаючих змін: ми плануємо додавати до повідомлень нові поля, не видаляючи старі, щоб забезпечити зворотну сумісність з існуючими обробниками. Тобто, наша остання мінорна версія буде містити в собі першу і другу версію. Можна додавати ідентифікатор предрелізної версії - можливо використаємо і це.
Контрактне тестування для визначення сумісності обробників. Перед тим, як реалізувати зміни в продакшені, ми плануємо використовувати контрактне тестування (не буду тут описувати, це тема окремої статті) для перевірки здатності обробників працювати з новими версіями повідомлень.
Впровадження та моніторинг
Розробка і впровадження: спочатку ми додамо нові поля до повідомлень, зберігаючи старі для забезпечення зворотної сумісності.
Оповіщення обробників: після впровадження змін ми поінформуємо обробників про нову версію та надамо ченджлог.
Моніторинг: через контрактне тестування ми будемо знати, чи всі обробники перейшли на останню мінорну версію. Якщо так - ми можемо видаляти стару версію та створювати нову мажорну - в ній зі змін буде лише видалення старої версії.
Висновок
Версіонування повідомлень у високонавантажених івентових системах вимагає обережного планування та оптимізації. Наш підхід, заснований на семантичному версіонуванні та контрактному тестуванні, є нашою спробою вирішити це завдання, зберігаючи при цьому максимальну ефективність та сумісність.
Це є на зараз планом і не впроваджено повною мірою. Та думаю, ділитися планами є також дуже корисним. І для тих хто читає. І, можливо, ви дасте свій фідбек та запропонуєте покращення/іншу більш ефективну версію. Пишіть, буду радий почути вашу думку.
