Вогонь і вода, певно найважливіша тема в розподілених системах. Як зазвичай поговоримо про надійність, масштабованість і швидкість.
Вступ
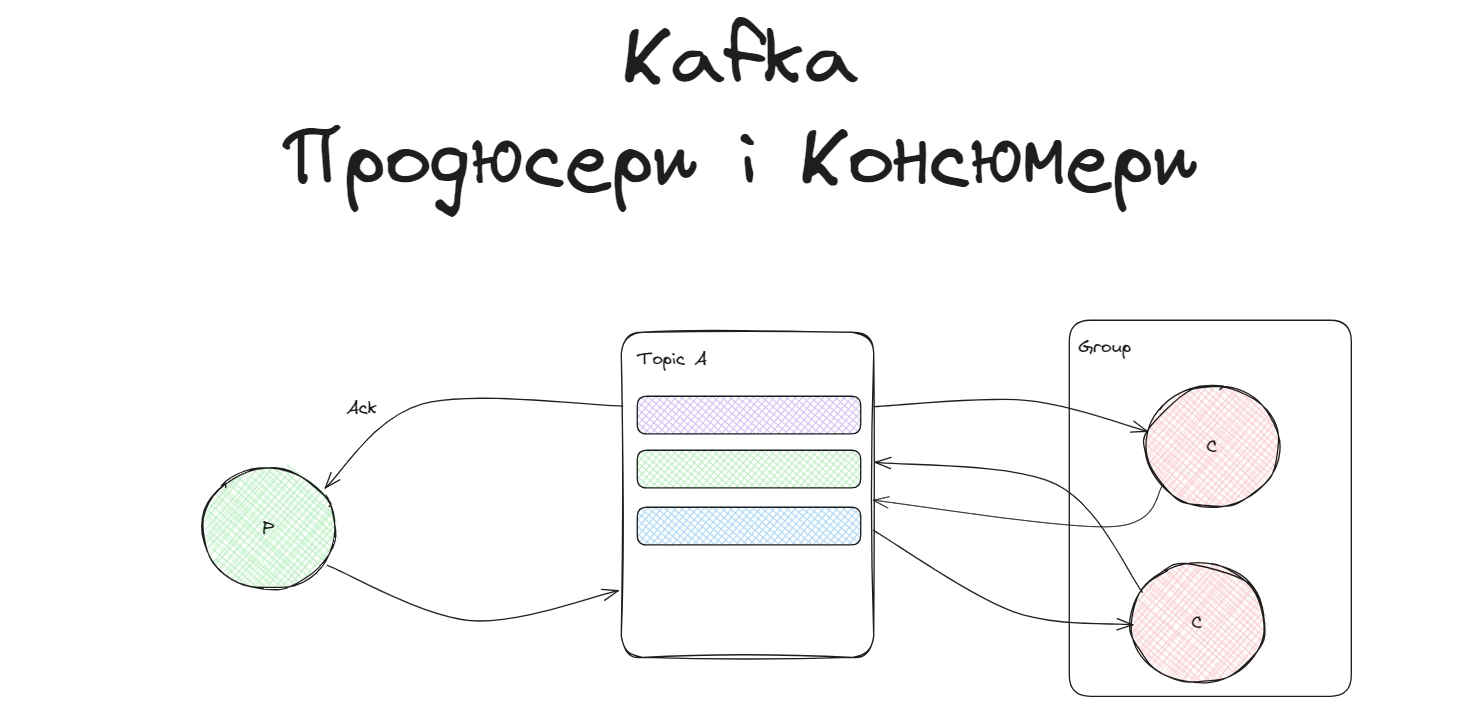
Producers are those client applications that publish (write) events to Kafka, and consumers are those that subscribe to (read and process) these events. In Kafka, producers and consumers are fully decoupled and agnostic of each other… @Kafka doc
Продюсери записують повідомлення в Kafka, а консюмери їх зчитують. Повідомлення записуються в топіки, а вони поділені на партиції. Партиції розподіляються по брокерам (сервери всередині кластера). Для більшої надійності, для партицій створюються копіїї, реплікації.
Консюмери і продюсери працюють окремо і задизайнені так, щоб максимально уникнути спільних залежностей. Такий дизайн необхідний для забезпечення широкої масштабованості, наприклад, продюсеру ніколи не треба чекати на консюмера.
Продюсери
Продюсери куди легші для розуміння, вони записують дані у Kafka, спілкуються acknowledgment-ами з Kafka і не використовують ніяких груп.
Продюсери можуть бути синхронними, можуть бути асинхронними, вони можуть по різному очікувати acknowledgement-и з Kafka (Повідомлення про успішний запис даних), вони бувають ідемпотентними, транзактивними і звичайними.
Про режими читання acknowledgement я писав у пості про реплікації. Зазвичай консюмери не бачать повідомлень, які записані продюсером, допоки той не отримає повідомлення, що всі ISR записали в себе повідомлення. Якраз конфігурація acknowledgement впливає на це.
Консюмери
Kafka консюмери зчитую повідомлення з партицій топіку і використовують офсети для позиційного читання.
Групи консюмерів
Група консюмерів це набір консюмерів, які кооперуються, щоб зчитувати дані з одного топіку. Kafka сприймає консюмер групу, як окрему сутність, тобто дві окремі консюмер групи в один момент часу отримують однакові повідомлення. Всередині консюмер групи, консюмери читають партиції розподілено.
Один із брокерів призначається координатором групи. Координатор займається менеджментом членів групи і розподіленям партицій всередині групи.
Координатор для кожної групи визначається з лідерів внутрішнього топіку офсетів (__consumer_offsets), який використовується для зберігання офсетів. Простими словами: лідер однієї з партицій вибирається координатором. Більше про лідерів в моєму пості про реплікації.
Коли консюмер стартує, то він шукає координатора в групі, щоб до нього підключитись. Потім координатор починає ребалансування групи, щоб новий консюмер отримав розподілену частину даних, перерозподілити партиції. Результатом кожного ребалансування є нова генерація/generation групи.
Кожен члени групи повинен надсилати heartbeats до координатора, щоб залишатись членом групи. Якщо консюмер не надсилатиме heartbeats до координатора довше за конфігурований session timeout, то координатор проведе ребалансування і перерозподілить партиції.
Офсети
Офсети вказують на позицію зчитування партиції. Зберігаються в окремому топіку, зміннюються консюмером.
Коли консюмер отримує партицію, яка визначене для нього координатором, то він повинен визначити ініціюючий офсет для читання. Звісно конфігурується auto.offset.reset. Зазвичай консюмер читатиме з наймолодшого офсету, або з найстарішого офсету.
Консюмер записує офсети для партиції з якої він читає, щоб коли він впаде, новий консюмер зміг продовжити читання з правильного офсету.
Конфігурація способу записування офсетів важлива для різного виду гарантій доставки повідомлень.
Консюмери також підтримують Commit API, який можна використовувати для ручного менеджементу запису офсетів.
Кожен виклик Commit API призводить до того, що брокеру надсилається запит на коміт/запис офсету. Використовуючи синхронний API, консюмер блокується до тих пір, поки цей запит не повернеться. Це може знизити загальну пропускну здатність, оскільки консюмер не зможе обробляти інші запити в цей час.
Щоб вирішити цю проблему можна використовувати асинхронний підхід в записі комітів.
Instead of waiting for the request to complete, the consumer can send the request and return immediately by using asynchronous commits. @Confluent doc
Проблема у цьому кейсі, щоб консюмер не буде повторно відправляти запис офсету, якщо минулий запис не вдався, тобто втратяться дані.
Порядок зчитування з партицій
Консюмер стягує повідомлення з призначених партиції використовуючи жадний раунд-робін алгоритм. Якщо max.poll.records=100 і брокер приписав консюмеру партиції A та Б, то спочатку консюмер спробує зчитати 100 повідомлень з партиції А. Якщо в партиції А немає достатньої кількості повідомлень, то він зчитає залишок з партиції А, а потім необхідну кількість з партиції Б, щоб в результаті зчитати 100 повідомлень.
Тобто, якщо в А залишилось 10 повідомлень, то він зчитає 10 повідомлень з А і 90 повідомлень з Б.
Дефолтне значення max.poll.records - 500Ребалансування
Ребалансування консюмер груп підтримує динамічне розподілення ресурсів в системі.
Кожне рабалансування складається з двох фаз: відклик партицій і призначення партицій.
Відкликання партицій завжди викликається перед ребалансуванням і є останнім шансом записати офсети перед тим, як партиції будуть призначенні консюмерам.
Призначення партицій завжди викликається після ребалансування і може бути використане для встановлення ініціюючої позиції у призначеній партиції. Під час призначення використовується хук відкликання для синхронного запису поточних офсетів.
Message Delivery Semantics
Які є гарантії?
Гарантії це твердження, які повинні вас у чомусь запевнити. Сприймати їх треба як аксіоми, покладаючись на авторитет розробників.
Message Delivery Semantic Guarantee - це гарантія про поширення повідомлень між брокером, продюсером і консюмером.
Деяк семантичні гарантії доставлення повідомлень між продюсером та консюмером:
At most once—(Щонайбільше раз) Повідомлення може бути втрачене, але ніколи не перевідправлене, тобто відправлене тільки раз.
At least once—(Принаймні раз) Повідомлення ніколи на втрачаються, але можуть бути перевідправленими, тобто відправлене принаймні раз.
Exactly once—(Точно раз) Повідомлення надсилається точно один раз.
Багато систем стверджують, що забезпечують семантику доставки «Exactly once», але більшість із цих тверджень насправді оманливі, бо невраховують нестабільність системи, мертвих консюмерів, втрачених даних і паралельного зчитування консюмерів.
MDS Гарантія в Kafka
Семантика Кафки проста. Коли повідомлення публікується, то воно записується у лог. Після того, як повідомлення було записане у лог, воно не буде втрачено, доки живий хоча б один брокер, який реплікує партицію, до якої було записано це повідомлення. Це власне і є основна MDS гарантія в Kafka і вона доволі надійна.
MDS з сторони продюсера
Якщо продюсер намагається опублікувати повідомлення і стикається з мережевою помилкою, він не може бути впевненим, чи сталася ця помилка до або після того, як повідомлення було записане.
До версії 0.11.0.1, коли продюсер стикався з помилкою в надсиланні повідомлення і не отримував відповіді щодо успішного надсилання повідомлення, то йому залишалось лише надіслати повідомлення повторно. Це була At-least once MDS
З версії 0.11.0.1, Kafka підтримує ідемпотенті продюсери, про яких я коротко писав про уникнення дублікатів у цьому пості. З цієї ж версії продюсери підтримують можливість відправляти повідомлення відразу до декількох партицій одного топіка, використовуючи transaction-like semantic (або всі повідомлення записані, або жодне з них, як @Transactional в Spring). В основному це використовується для Exactly-once обробки між Kafka топіками.
Не у всіх випадках потрібні такі суворі гарантії. Якщо нам потрібний чутливий до затримок продюсер, то можна вказати продюсеру почекати відповідь(acknowledgement) X секунд, або взагалі працювати асинхронно і не витрачати час на очікування відповіді.
MDS з сторони консюмера
Всі репліки мають однакавий лог з однаковими офсетами. Консюмер контролює свою позицію в лозі. Якщо консюмер ніколи не ламається, то він міг би просто зберігати позицю в пам’яті. Але проблема, коли консюмер ламається і ми в цей конкретний момент хочемо, щоб нашу партицію обровляв новий процес, то новому процесу потрібно буде взяти правильну позицію в партиції, щоб продовжити послідовно обробляти дані.
У консюмера є декілька опцій для зчитування даних і оновлення позиції:
Консюмер зчитає повідомлення, запише його позицію в лог і потім обробить повідомлення. В такому випадку, якщо консюмер відпаде, то новий консюмер почне з позиції, яка була зафіксована минулим консюмером. Проблема, що деякі повідомлення, які були до цієї позиції не опрацювались, тобто втратились, бо консюмер встиг зберегти позицію, але не встиг обробити повідомлення перед своєю смертю. Тобто у цьому кейсі працює семантика At-most once.
Консюмер зчитає повідомлення, обробить його, а тільки потім збереже позицію. У цьому випадку новий процес братиме повідомлення, які вже могли бути обробленими минулим консюмером, тобто працює семантика At-least once. У багатьох випадках меседжі мають праймері ключ, тому оновлення є ідемпотентними (отримання того самого повідомлення двічі просто перезаписує рекорд іншою його копією).
Exactly-once semantic
Коли ми читаємо дані з одного топіку і хочемо записати їх в інший топік, то можна скористатись транзакційним продюсером.
Позиція консюмера зберігається, як повідомлення в окремому топіку, тобто ми можемо записувати офсети в кафку в тій же транзакції, що і дані. Якщо транзакція провалиться, (навіть, якщо з сторони консюмера вилетить ексепшн), то офсети повернуться до старих значень і дані на вихідних топіках не будуть видимі для інших консюмерів в залежності від їнього ізоляційного рівня.
In the default "read_uncommitted" isolation level, all messages are visible to consumers even if they were part of an aborted transaction, but in "read_committed," the consumer will only return messages from transactions which were committed (and any messages which were not part of a transaction). @Kafka doc
Транзакційний продюсер/консюмер може бути використаний для забезпечення Exaclty-once при передачі та обробці даних між Kafka топіками (Kafka Streams).
Kafka за замовчуванням гарантує At-least-once і дозволяє користувачеві реалізувати доставку At-most-once, уникнувши повторні записи з сторони продюсера і змусивши консюмер записувати офсет перед обробкою даних.
В моделі передавання даних топік - топік, можна використати Transactional, для Exactly-once.
