Ми живемо у дуже нестабільному світі, і що ще страшніше, у цьому нестабільному світі нам треба писати стабільні системи. Цей пост про реплікації в Kafka, які забезпечують її відому надійність.
Коли проектували Kafka, то однією з основних цілей була надійність даних, що, якщо відвалиться брокер, що якщо будуть проблеми з мережею, як відновлювати дані, якщо ми їх втратимо? Ця ідея надійної системи яскраво виражається у концепції реплікацій.
Finally in cases where the stream is fed into other data systems for serving, we knew the system would have to be able to guarantee fault-tolerance in the presence of machine failures. (Kafka doc)
Реплікація
Реплікація в Kafka є механізмом, що дозволяє розподілено поширювати (копіювати) партішини між брокерами, забезпечуючи високу доступність та надійність системи.
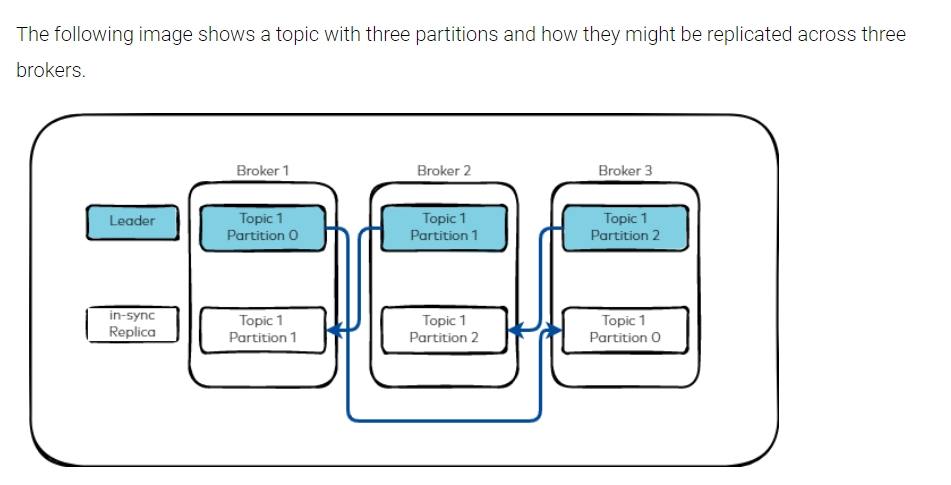
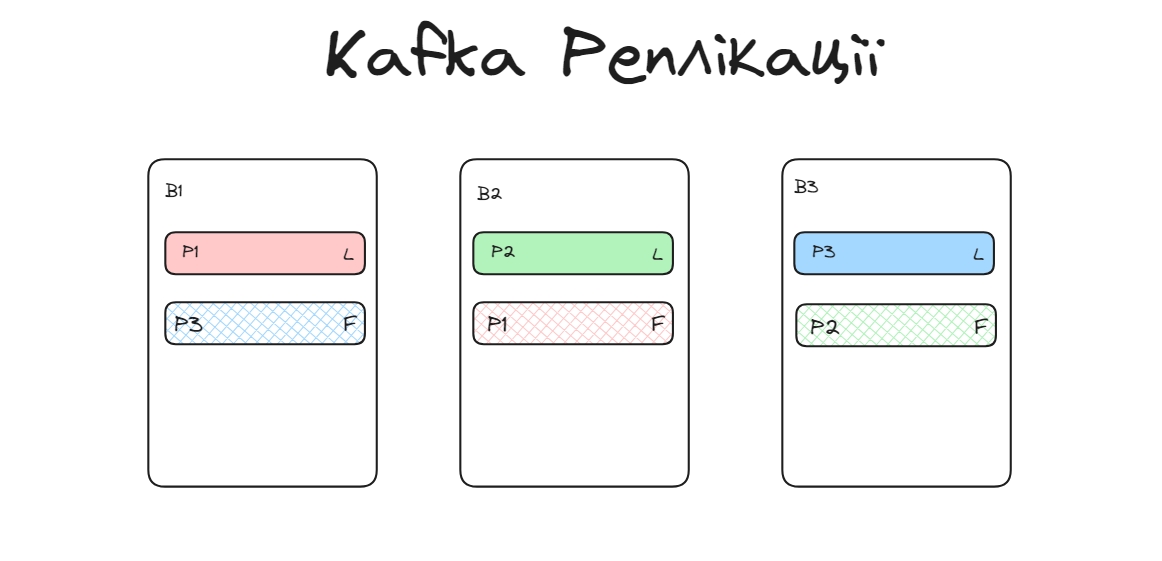
Коли створюється топік, його партішини розподіляються порівну між брокерами. Потім для кожного партішина створюється репліка в іншому брокері, теж рівномірно. Вже у брокері кожний партішин ділиться на сегменти (файли) для зберігання.
По дефолту реплікейшн фактор рівний 1, тобто створюється одна репліка для одного партішина. Рекомендується ставити реплікейшн фактор 3.
Kafka не гарантує, що партиції, як і репліки розіб’ються ідеально між брокерами, реплікація збільшує ймовірність збереження/відновлення даних, але не робить її 100%
Кожен топік має сконфігурований реплік фактор для своїх партішинів, який дуже важливий. Чим більший реплік фактор тим більше буде створено реплік для кожного партішина, що збільшить надійність даних, але вимагатиме від брокера менеджити кожну репліку, що може вплинути на перформнас.
Коли ми говоримо про топік у Kafka, ми насправді маємо на увазі збірку партішинів, які утворюють логічний контейнер для повідомлень або подій. Кожен партішин зберігається на диску та може мати свої репліки на інших брокерах, що забезпечує надійність та доступність даних.
Лідер
Лідер це брокер на якому знаходиться оригінальний партішин.
Кожен партішин має одного лідера (leader) та одну або кілька реплік. Лідер - це брокер, який відповідає за прийом, зберігання та обробку повідомлень в парітшині і на якому знаходиться оригінальний партішин. Репліки - це копії даних, які зберігаються на інших брокерах.
Після того, як лідер отримує повідомлення від продюсера та записує його до свого партішину, він надсилає це повідомлення усім своїм реплікам.
Одна із стратегій повідомлення продюсера, що репліки синхронізувались: Після успішного запису повідомлення на лідері та усіх репліках, лідер відправляє підтвердження продюсеру про те, що повідомлення було успішно збережено.
Синхронна/Асинхронна реплікація
У Kafka є можливість налаштувати синхронну або асинхронну реплікацію. У синхронній реплікації лідер чекає, доки всі репліки підтвердять успішне збереження повідомлення перед відправленням підтвердження продюсеру. У асинхронній реплікації лідер відправляє повідомлення реплікам і надсилає підтвердження продюсеру, навіть якщо не всі репліки успішно зберегли повідомлення.
Зрозуміло, що синхронна комунікація надійніша, але вимагає більше часу, бо чекає на комунікацію лідера і його послідовників.
Якщо під час асинронної реплікації брокер репліканта вийде з ладу, то лідер однаково поверне продюсеру підтвердження в реплікації, що призведе до тимчасової втрати даних. Втрата тимчасова, бо коли підніметься новий реплікант, то він увійде в консенсус з лідером.
ISR/OSR
У Kafka одні репліки можуть мати новіші дані ніж інші репліки зазвичай у випадках відмінної комунікації лідера і його реплік, наприклад: У випадку асинхронної реплікації лідер продовжує приймати нові повідомлення від продюсера та надсилати їх реплікам без очікування підтвердження від них. Це означає, що деякі репліки можуть отримати та зберегти повідомлення раніше, ніж інші репліки, що може призвести до ситуації, коли деякі репліки мають новіші дані.
In-Sync Replicas (ISR): Це набір реплік для кожного партішина, які наздоганяють (catch up) інших лідерів у кластері, тобто вони мають ту ж саму копію даних, які має лідер. ISR використовується для забезпечення надійності та доступності даних.
Out-of-Sync Replicas (OSR): Це репліки, які не наздогнали (are not caught up) з лідером, тобто вони відстають від лідера в обробці повідомлень. OSR можуть виникати у випадках, коли репліка відстає у читанні повідомлень або через перевантаження.
Сама Kafka визначає яка репліка буде ISR, а яка OSR. ISR репліки забезпечують більшу надійність даних, бо змушують брокера оновляти їх при апдейті від продюсера. А OSR буде реквестати в лідера апдейти з свого брокера, тобто оновлятись пасивно.
В Kafka можна законфігурувати мінімальну кількість ISR. Якщо тільки одна ISR репліка, то дані будуть писатись тільки в лідера працює так само як з репліка фактором.
Вбитий лідер (Leader failover)
Що відбувається, коли втрачається брокер з оригінальним партішином?
Звісно необхідно знайти нового лідера. Kafka вибирає одну з реплік з ISR, як нового лідера для цього партішину. Як правило, вибирається та репліка, яка має найбільшу кількість актуальних повідомлень (на яку найменше відстає лідер).
Якщо під час цього процесу існують несинхронізовані повідомлення на інших репліках, які ще не досягли cтарого лідера, новий лідер може мати більш свіжу копію даних, ніж попередній лідер.
Відновлення реплік
Коли репліка виявляє втрату даних або стає недоступною, Kafka автоматично запускає процес відновлення репліки. Це включає синхронізацію даних з іншою реплікою або відновлення даних з журналу збереження (replication log)
replication log - це журнал змін, який використовується в Apache Kafka для забезпечення реплікації даних між брокерами. Він грає ключову роль у забезпеченні надійності та стійкості системи, дозволяючи відновлювати дані в разі втрати чи недоступності репліки.
At its heart a Kafka partition is a replicated log. The replicated log is one of the most basic primitives in distributed data systems, and there are many approaches for implementing one. A replicated log can be used by other systems as a primitive for implementing other distributed systems in the state-machine style. (Kafka doc)
Іноді трапляютья ситуації, в наслідок проблем з мережею, коли після смерті первинного лідера одночасно дві репліки вважають себе лідером. Ця ситуація називається split brain. Є різні підходи для того, щоб уникнути split brain, або мінімізувати його наслідки.
Всі померли
А, якщо вони всі помруть?
Кафка гарантує, що дані будуть відновлення якщо є принаймні одна ISR, тобто:
Є дві моделі поведінки, які можна реалізувати:
Можна зачекати, доки репліка в ISR повернеться до життя (Використовуючи replication log), і вибрати цю репліку як лідера, звісно якщо в неї ще є свої дані.
Вибрати будь-яку репліку, яка повернеться до життя (з того самого replication log), як нового лідера.
This is a simple tradeoff between availability and consistency. If we wait for replicas in the ISR, then we will remain unavailable as long as those replicas are down. If such replicas were destroyed or their data was lost, then we are permanently down. If, on the other hand, a non-in-sync replica comes back to life and we allow it to become leader, then its log becomes the source of truth even though it is not guaranteed to have every committed message. (Kafka doc)
За замовчуванням, починаючи з версії 0.11.0.0, Kafka обирає першу стратегію та віддає перевагу очікуванню ISR.
Якщо вам важливо, щоб система піднялась швидше, то це можна наконфігурувати: unclean.leader.election.enable
Можливо ця система не ідеально надійна, але кращої в нас нема.
Конфігурація продюсера для очікування реплікації / Producer Acknowledge
Ще невеличке, але важливе уточнення.
З сторони продюсера можна законфігурувати, який він респонс очікує від брокера.
Режим 0 - Продюсер не очікує підтвердження від брокера, він буферизує значення, шукає брокера до якого треба п’дєднатись і плюнув у нього даними і нічого не чекає.
Режим 1 (Leader Acknowledge) - це дефолтний режим, продюсер очікуватиме відповіді, що дані збереглись в лідера.
Режим -1 - у цьому режимі продюсер чекатиме поки оновляться всі ISR репліки.
acks=all
Це важливо, бо режим впливатиме на час, протягом якого, продюсер буде заблокаваний.
