Партиції це складові топіка, банально різні його частини, які були створенні для того, щоб зробити читання/записування даних масштабованим.
This distributed placement of your data is very important for scalability because it allows client applications to both read and write the data from/to many brokers at the same time.
Партиція
Кожен топік поділений на визначену кількість партицій, зазвичай, це одна партиція по дефолту, але кількість партицій можна наконфігурувати: num.partitions
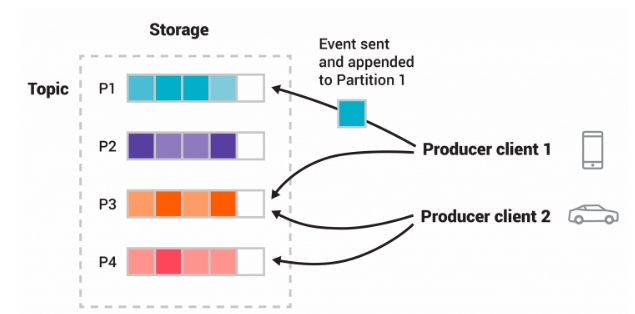
Два різні продюсери публікують, незалежно один від одного, нові івенти в топік, записуючи події в партиції. Івенти з однаковим ключем (на малюнку позначені кольором) записуються в одну партицію. Зауважте, що обидва продюсери можуть писати в той самий розділ, якщо це необхідно.
Кожна партиція складається з бакетів (на малюнку квадрати, які поступово наповнюють різнотонові івенти одного кольору).
Партиції, як і їхні реплікації, зберігаються на різних кафка брокерах, щоб забезпечити надійність даних.
Насправді топік це логічне поняття, яке об’єднує всі партиції, немає окремого файлу для топіку. Коли створюються партиції, то їх об’єднуть приписанням до одного топіку для ієрархізації і зручнішого менеджементу.
Як кафка визначає в яку партицію записати дані?
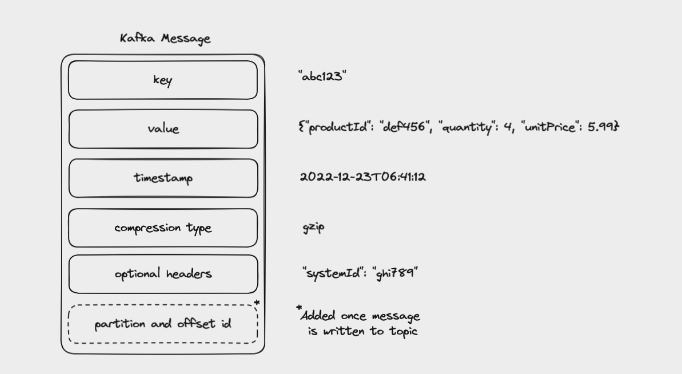
У Kafka визначення того, в яку партицію буде записано повідомлення, відбувається за допомогою ключа (key) повідомлення. Kafka використовує кількість партицій разом з хеш-функцією ключа повідомлення, щоб визначити партицію, в яку потрібно записати повідомлення.

Якщо клієнт не вказав ключ для івента, то Kafka використовує раунд-робін або інші стратегії для вибору партиції.
Після того, як Kafka вибрала партицію вона записується в кінець логу цієї партиції, зазвичай ці логи називаються якось так: <topic_name>-<partition_number> my_topic-0.
Офсети
Офсет - це унікальний ідентифікатор, приписаний партішинам які містять повідомлення. Найважливіше його використання полягає в тому, що він ідентифікує повідомлення за допомогою ідентифікаторів, які доступні в партішинах. Іншими словами, це позиція в партішині для наступного повідомлення, яке буде надіслано споживачеві.
У Kafka, офсети в партиціях використовуються для відстеження прогресу консюмера в читанні повідомлень з партиції. Кожен консюмер записує в Kafka свій власний офсет для кожної партиції, з якої він читає дані. Офсет позначає зміщення (або позицію) останнього прочитаного повідомлення у партиції.
Коли консюмер читає повідомлення з партиції, він оновлює свій офсет для певної партиції, щоб вказати наступне повідомлення, яке він буде читати. Офсет може бути оновлений консюмером наприкінці кожного повідомлення або батча повідомлень, залежно від конфігурації споживача.
Офсети зберігаються у внутрішньому топіку Kafka, consumer offsets topic. Цей топік зберігає офсети (commited offsets) для всіх партицій. Кожен раз, коли консюмер записує свій офсет, ця зміна записується у топік для зберігання офсетів.
Коли консюмер починає читати повідомлення з партиції, він спочатку перевіряє топік дял збереження офсетів, щоб отримати останній офсет, з якого він починав читати. Потім консюмер продовжує читати повідомлення з цього офсету. Якщо будуть проблеми, то консюмер знайде де йому треба продовжити читати повідомлення використовуючи офсети.
Коли Kafka стартує новий топік, то офсер рівний 0. Якщо створюється нова консюмер група вже для існуючого топіка, то офсет почнеться, або з початку, або з кінця топіку (Конфігурується).
Офсет приписується брокером, коли повідомлення записується в партицію. Він визначає унікальну позицію, яка належить йому всередині партиції.
Кожен консюмер, з групи консюмерів, читаючи з партиції веститиме вій власний офсет, який відрізнятисеться від консюмерів в іншій консюмер групі. Консюмер оновляє свій офсет, але офсети партішинів не оновляються.
Динамічне розширення
Що буде, якщо всі партиції топіка заб’ються даними? Тут все залежить від конфігурації, деякі продюсери будуть чекати acknowledge від брокера, деякі (асинхронні) оброблять помилку, коли та вернеться від брокера.
Але чи можна якимось чином динамічно розширювати партицію, або кількість партицій? Можна напряму спілкуватись з кафкою через CLI команди і змінювати кількість партицій напряму, що не дуже зручно. Ще можна використовував Kafka Streams, якщо ви змінюєте кількість потоків або розподіл ключів, Kafka Streams може автоматично розширювати або зменшувати кількість партицій для відповідності новій конфігурації.
Наразі Kafka не надає вбудованої функціональності для автоматичного збільшення кількості партицій, коли вони заповнюються, тобто треба все робити ручками.
Зазвичай дефолтний розмір партиції становить 1 ГБ або 1,048,576 КБ. Це означає, що коли ви створюєте новий топік в Kafka без явної конфігурації розміру партицій, вона отримує розмір 1 ГБ на кожну партицію за замовчуванням.
Максимум у брокері може бути 4000 партицій і в кластері 200 000 партицій.
Порядок і усунення дублікатів
Це одне із найпопулярніших питань на технічних інтерв’ю.
Kafka гарантує, що будь-який споживач визначеної партиції топіку завжди читатиме події цієї партиції в тому самому порядку, в якому вони були записані.
Порядок:
Найпростіше це зробити топік з однією партицією.
Якщо декілька партицій, то ми можемо записати всі дані за ключем в одну партицію, і змусити консюмера читати конкретну партицію, що негативно вплине на розширюваність з сторони консюмера.
External Sequencing with Time Window Buffering - (Зовнішнє секвенування з буферизацією у часовому вікні). Тут все просто, ми клеймуємо кожну послідовність глобальним порядковим номером, а консюмери буферизують дані і ділять їх по часовим вікнам.
Декілька консюмерів отримують різні повідомлення і можуть відновлювати порядок з різних партицій, у такому підході краще мати спільний ресурс, який буде доступний консюмерам.
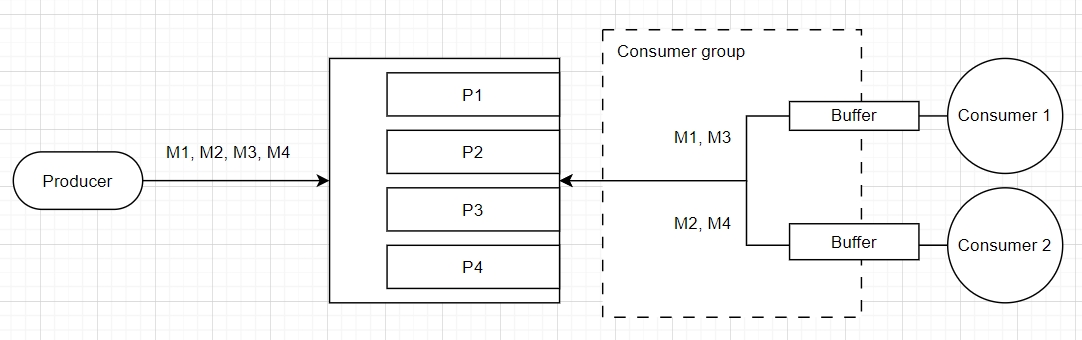
Буфери групують дані по часу, а потім сортують по порядковому номеру З сторони консюмерів дані групуються по часовим вікнам, а потім обробляються послідовно. Повідомлення, які надходять протягом певного періоду часу, ми об’єднуємо в пакети, а коли вікно закінчується, ми обробляємо пакет. Це гарантує, що повідомлення протягом цього періоду часу оброблятимуться в порядку, навіть якщо вони надходять у різний час у межах вікна.
Консюмер буферизує повідомлення та змінює їх порядок на основі порядкових номерів перед обробкою. Нам потрібно переконатися, що повідомлення обробляються в правильному порядку, і для цього консюмер повинен мати буферний період, коли він считує повідомлення кілька разів перед обробкою буферизованих повідомлень, і цей буферний період має бути достатньо довгий, щоб впоратися з потенційними проблемами впорядкування повідомлень
Дублікати:
Ідемпотентні продюсери - це фіча кафки спрямована на доставку повідомлень точно один раз, таким чином запобігаючи будь-яким дублікатам. Це важливо в сценаріях, коли виробник може повторити спробу надіслати повідомлення через помилки мережі або інші тимчасові збої. Хоча основною метою ідемпотентності є запобігання дублюванню повідомлень, вона опосередковано впливає на порядок повідомлень. Kafka досягає ідемпотентності, використовуючи дві речі: ідентифікатор виробника (PID) і порядковий номер, який діє як ключ ідемпотентності та є унікальним у контексті конкретного розділу. Легко конфігурується -
enable.idempotence=trueСторона клієнта - тут доволі просто, ви можете зробити свою реалізацію для запобігання дублікаті, наприклад кеш. Це допоможе уникнути дублікатів на рівні бізнес логіки, але не на рівні стабільності системи. Сюди входить і UUID для кожного івента з сторони клієнта, це значить що в тілі самого івента можна робити унікальний запис для подальшої ідентифікації з тими івентами, що в кеші.
Викоритовувати одного продюсера на партицію і, коли виникатимуть проблеми з мережею порівнювати спожите повідомлення з останнім в партиції.
Скільки треба вибрати партицій для топіка?
Питання із зірочкою.
Тут необхідно добре розуміти вашу систему. Пам’ятайте, що кожну партицію (і її репліку), її офсети буде менеджити Kafka. Тут необхідно враховувати вимоги до пропускної здатності, чи ви очікуєте на масштабування системи, чи ви використовуєте ключі для партицій (чи для вас важливий порядок повідомлень), треба врахувати фактор реплікації і звісно необхідно зрозуміти наскільки вам важлива надійність ваших даних.
Чимось таким архітектори займаються, коли ви думаєте, що вони нічим не займаються.
Стратегії партиціювання (Kafka ≥ 2.4)
Стратегія | Опис |
|---|---|
Хешування за ключем | Ключ івента хешується і по ньому визначається партиція для запису. Дефолтний для повідомлень з ключем. |
Uniform sticky partitioner (Рівномірне закріплене партиціювання) (Застаріле) | Повідомлення надсилаються до закріпленого розділу (поки не буде досягнуто параметрів batch.size або часу linger.ms), щоб зменшити затримку. |
Sticky Partitioner (Закріплене партиціювання) | Схоже до Uniform sticky partitioner , але повідомлення надсилаються батчами. Дефолтний для повідомлень без ключа. |
Раунд-робін партиціювання | Використовується тільки раунд-робін |
Власне партиціювання | Імплементуйте власне партиціювання на стороні клієтна через інтерфейс Partition. |
(Sticky partitioning) Якщо дані не поміщаються в закріплену партицію то закріплена партиція змінюється і залишені дані поміщаються в нову закріплену партицію, тобто пів батчу може бути в одній партиції, а пів в іншій. Для старого алгоритму закріпленого партиціювання нові дані просто почнуть надсилатись у нову партицію. Не забувайте, що партиції створюються мануально.
Кожна з стратегій партиціювання може бути доречною залежно від вашої бізнес логіки.

