Всім привіт!
У попередній статті про Exactly Once Delivery Semantics в Apache Kafka я висловив думку:
"exactly-once" в розподілених системах — це завжди комбінація підходів, а не одна чарівна конфігурація
Але щоб це твердження не звучало голослівно, варто зрозуміти, як саме працюють механізми дедуплікації під капотом: як Kafka реально запобігає дублюванню повідомлень та де саме закінчується “exactly-once” гарантія.
У попередній статті ми згадували Idempotent Producer та Transactional Producer/Consumer на концептуальному рівні. У цій — розберемо їхню внутрішню механіку та практичні обмеження.
Поїхали…
Згадаємо ключові характеристики Idempotent Producer та Transactional Producer/Consumer
Перш ніж занурюватись в деталі, коротко згадаємо що це за компоненти та яку роль вони виконують:
Idempotent Producer (`enable.idempotence=true`):
Кожен producer отримує від Broker унікальний Producer ID (PID) та веде Sequence Number per partition
Broker дедуплікує повідомлення за парою (PID, Sequence Number) — якщо повідомлення з таким sequence вже є, повторний запис ігнорується
Захищає від дублікатів при мережевих retry в рамках однієї сесії (поки PID не змінився)
Transactional Producer (`transactional.id` + `enable.idempotence=true`):
Розширює Idempotent Producer стабільним transactional.id, який переживає рестарти
Kafka персистить mapping transactional.id → PID + Epoch в Transaction Log на диску
При рестарті producer отримує той самий PID з новим Epoch (zombie fencing)
Підтримує атомарний запис кількох повідомлень (all-or-nothing transactions)
Transactional Consumer (`isolation.level=read_committed`):
Читає тільки committed повідомлення (фільтрує aborted transactions)
Працює в парі з Transactional Producer — без нього read_committed не має сенсу
Розглянемо на базі наступних питань:
Що таке PID і Sequence number та як Idempotent Producer використовує їх для дедуплікації?
Які проблеми виникають під час рестарту Idempotent Producer та як це вирішується?
Як Transactional Producer запобігає дублікатам після рестарту?
PID та Sequence Number
Щоб коректно дедуплікувати повідомлення, Apache Kafka має вміти відрізняти повторну відправку (retry) від нового повідомлення.
Для цього Idempotent Producer використовує два ключові параметри — PID та Sequence Number.
Саме вони дозволяють Kafka розпізнавати дублікати при мережевих retry.
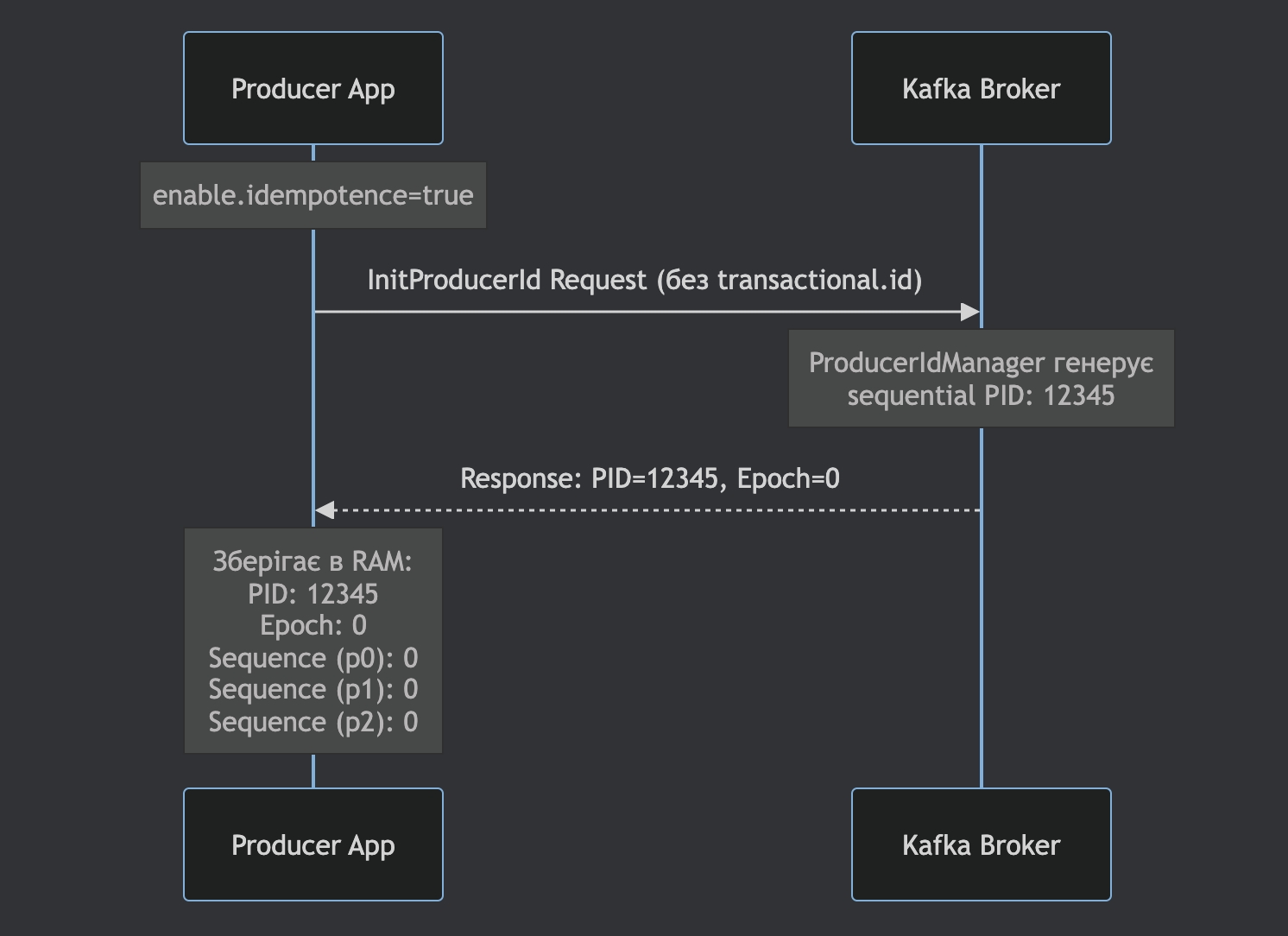
PID (Producer ID) — унікальний ідентифікатор producer-а, який присвоює Kafka broker
Sequence Number — окремий counter для кожної partition, який веде producer
Відразу виникає питання: як саме Kafka присвоює Producer ID?
Давайте подивимось:
Ключові моменти
PID присвоюється broker-ом, а не producer-ом
PID логічно поводиться як інкрементний ідентифікатор, який broker видає новим producer session
Для Idempotent Producer PID зберігається в RAM процесу і не переживає рестарт сервісу
Sequence Number — окремий counter для кожної partition
Що це означає на практиці
Kafka може визначити, чи є повідомлення повторною відправкою або новим записом.
Дедуплікація працює лише в межах однієї producer session.
Після рестарту producer отримує новий PID — і це створює новий набір ризиків, які розглянемо далі.
Що відбувається під час рестарту Idempotent Producer?
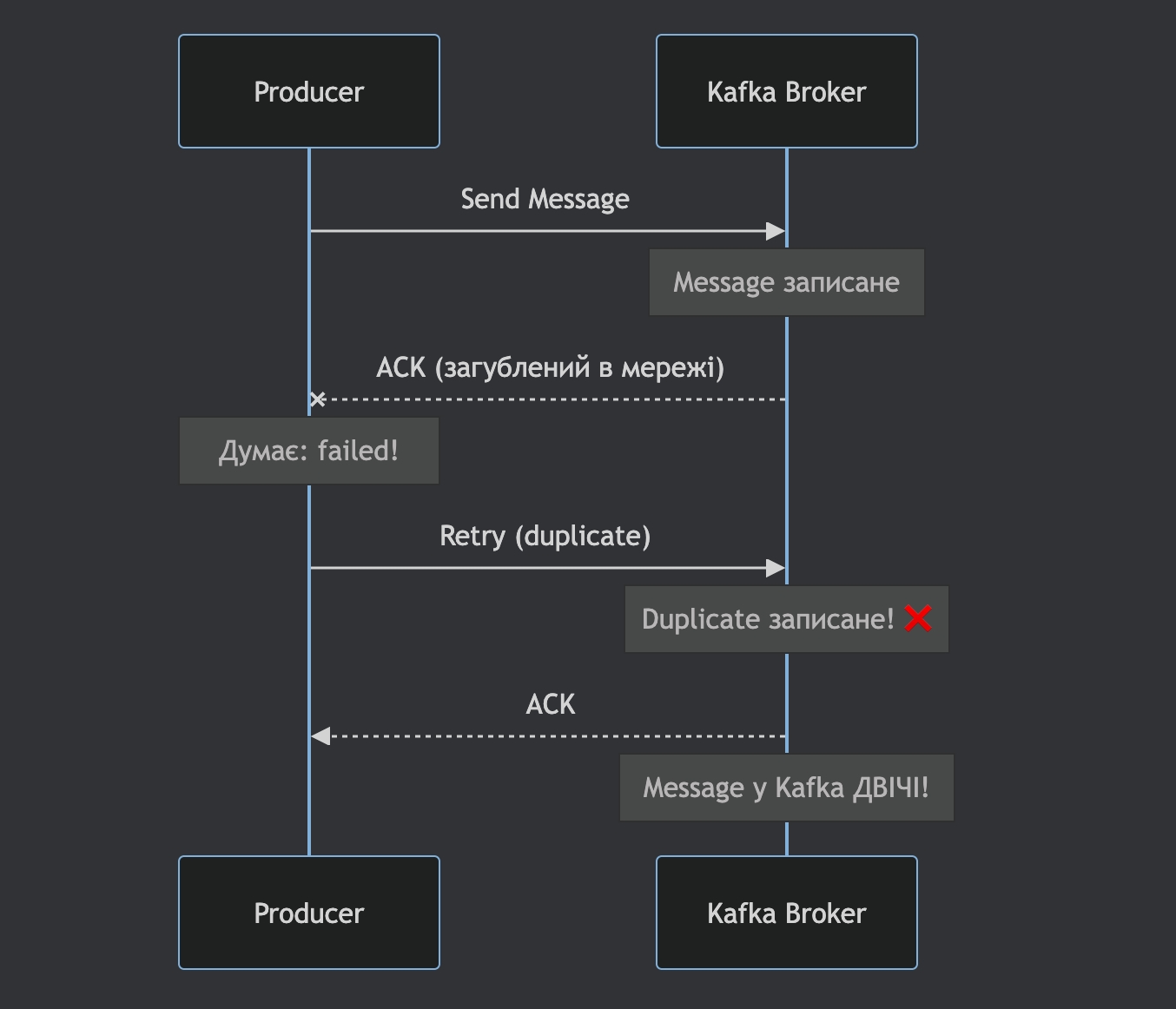
Один із найважливіших сценаріїв — це рестарт producer-а під час відправки повідомлень.
Уявімо ситуацію:
producer відправляє повідомлення
запис успішно потрапляє в Apache Kafka
ACK губиться через мережеву помилку
producer падає і перезапускається
після рестарту він відправляє повідомлення повторно
Без додаткових механізмів це призводить до дубліката в топіку.
Рішення — Idempotent Producer
@Configuration
public class IdempotentProducerConfig {
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> config = new HashMap<>();
config.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
config.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
config.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// IDEMPOTENCE: Kafka запам'ятовує кожен message за (ProducerID + SequenceNumber)
config.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
// Idempotence requires:
config.put(ProducerConfig.ACKS_CONFIG, "all");
config.put(ProducerConfig.RETRIES_CONFIG, Integer.MAX_VALUE);
config.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 5);
return new DefaultKafkaProducerFactory<>(config);
}
}Як працює Idempotence?
Idempotent producer дозволяє Kafka за допомогою аналізу PID та Seq визначити, чи є повідомлення повторною відправкою.
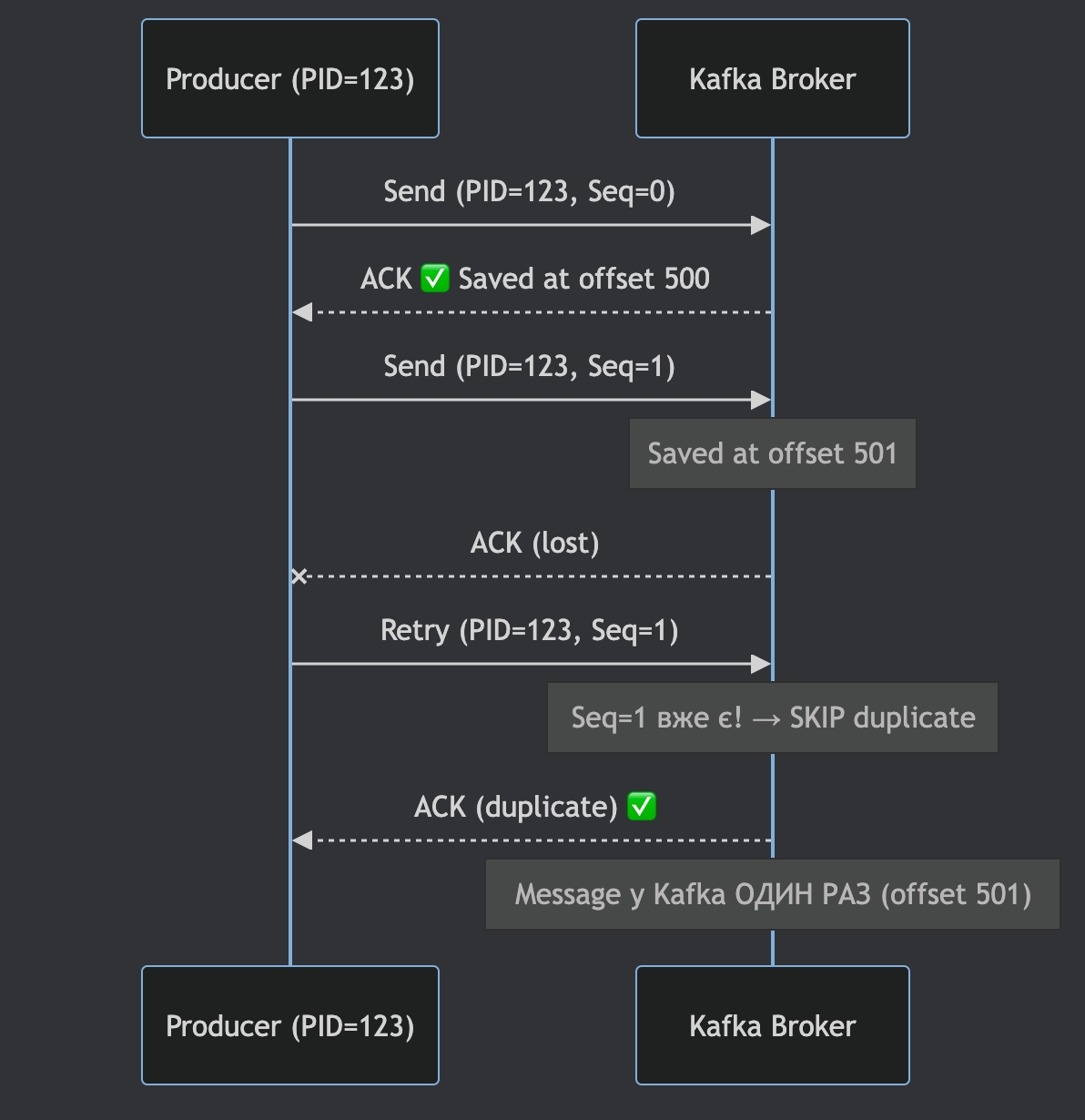
Концептуально broker виконує перевірку:
if (record.producerId == 123 && record.sequence <= lastSeq) {
// Duplicate! ACK but don't write
return ACK;
}Тобто broker запам’ятовує останній sequence number для кожного PID і відкидає повторні записи.
Важливий нюанс — PID існує лише в межах однієї producer session.
Після рестарту сервісу producer отримує новий PID, і broker більше не може пов’язати нову сесію зі старою. Це означає, що idempotent producer сам по собі не гарантує захист від дублікатів після restart.
Думаю, багато хто впізнає в своїх продакшн-проєктах подібний сценарій:
// Реальний сценарій з Spring Kafka
@Service
public class OrderService {
@Autowired
// enable.idempotence=true
private KafkaTemplate<String, String> kafkaTemplate;
public void createOrder(Order order) {
// 1️⃣ Send to Kafka
kafkaTemplate.send("orders", order.getId(), toJson(order));
// Internal: (PID=12345, Seq=5) → Broker writes to offset 1050
// Broker sends ACK
//
// 2️⃣ ❌ ACK втрачено! (network issue, timeout, partition leader election)
// Producer думає: "Failed to send"
//
// 3️⃣ Producer CRASH! (OutOfMemoryError, kill -9, deployment restart)
// PID=12345 втрачений (був тільки в RAM)
//
// ❓ Що в Kafka?
// → Message "order-123" вже ЗАПИСАНЕ at offset 1050!
// → Але producer не знає про це (ACK lost)
// ═══════════════════════════════════════════════════════════════
// 4️⃣ Application restarts (Kubernetes pod restart, new deployment, etc.)
// NEW PID=67890!
// 5️⃣ Application retry logic (з deduplication table, retry queue, etc.)
kafkaTemplate.send("orders", order.getId(), toJson(order)); // RETRY!
// Internal: (PID=67890, Seq=0) → Broker writes to offset 1051
// ✅ Success!
// ═══════════════════════════════════════════════════════════════
// ❌ РЕЗУЛЬТАТ: DUPLICATE в топіку!
// offset 1050: (PID=12345, Seq=5) "order-123" ← Original (ACK lost)
// offset 1051: (PID=67890, Seq=0) "order-123" ← Retry after restart
//
// Broker НЕ може deduplicate:
// - PID=12345 vs PID=67890 → різні producers
// - Kafka не знає що це той самий order!
}
}Саме цю проблему можна вирішити за допомогою Transactional Producer, який розглянемо далі.
Як Transactional Producer запобігає дублікатам після рестарту?
Ключова відмінність — transactional.id.
Це стабільний ідентифікатор producer-а, який переживає рестарти JVM або сервісу.
Kafka персистить mapping transactional.id → PID + Epoch в Transaction Log (на диску), тому при рестарті producer отримує той самий PID, а Kafka може відновити його стан і гарантувати консистентність.
Конфігурація Transactional Producer
config.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
// ✅ STABLE ID
config.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "order-service-tx-1");
Producer producer = new KafkaProducer(config);Що відбувається при першому старті:
Kafka генерує PID
Зберігає mapping у transaction log
Веде state producer-а між рестартами
"order-service-tx-1" → PID=12345, Epoch=0Kafka Transaction Log (persisted to disk)
┌──────────────────────────────────────┐
│ Transactional ID → Producer State │
├──────────────────────────────────────┤
│ "order-service-tx-1" → PID=12345 │
│ Epoch=0 │
│ Last Seq=5 │
└──────────────────────────────────────┘Це ключова відмінність від Idempotent Producer без transactional.id, де PID існує тільки в RAM.
Повний lifecycle: від старту до рестарту
Розглянемо сценарій покроково.
Step 1: Producer Startup (first time)
Producer запускається вперше:
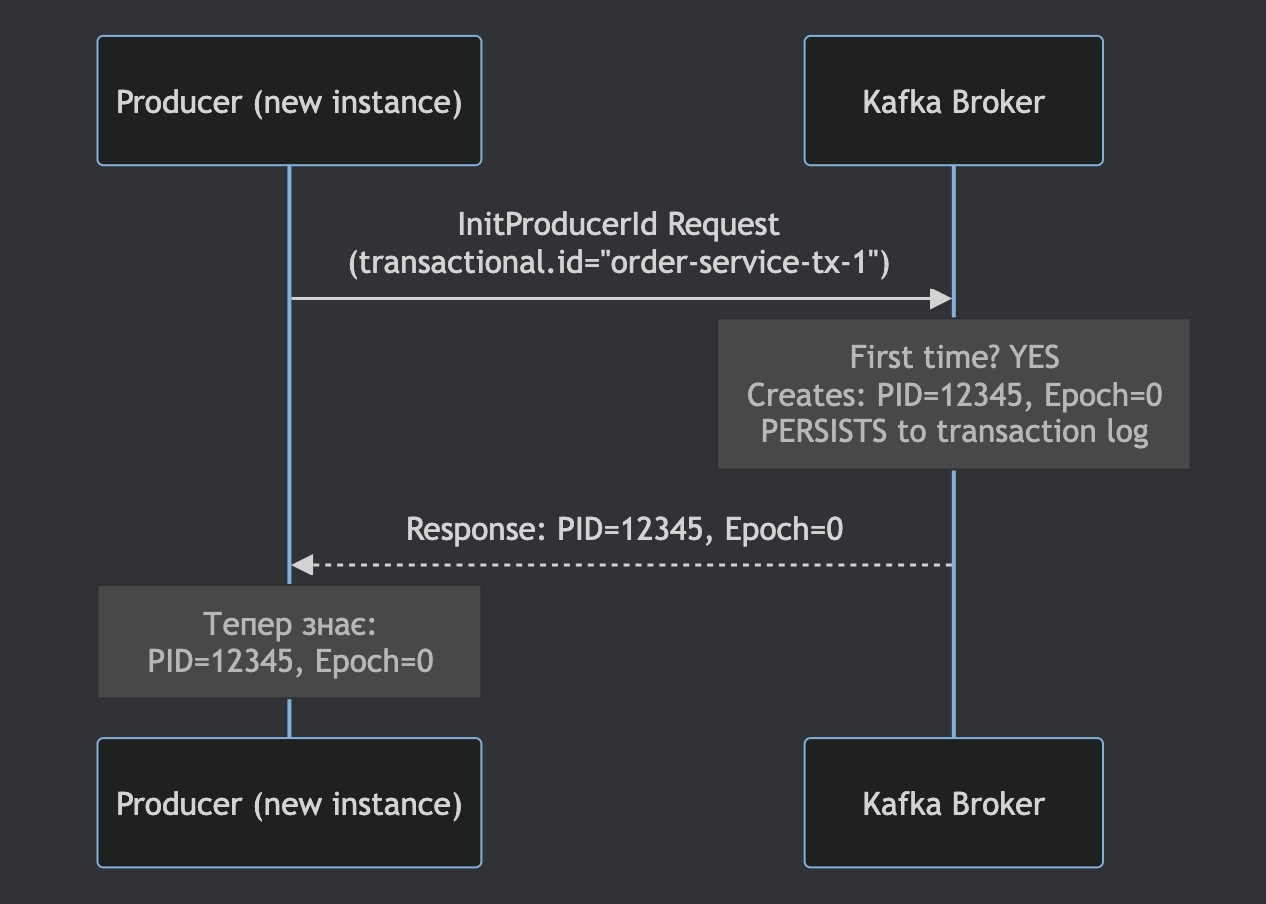
Producer отримує:
PID = 12345
Epoch = 0
і починає транзакційні записи.
Step 2: Message Send + Crash
Producer відправляє повідомлення, але падає до commit транзакції.
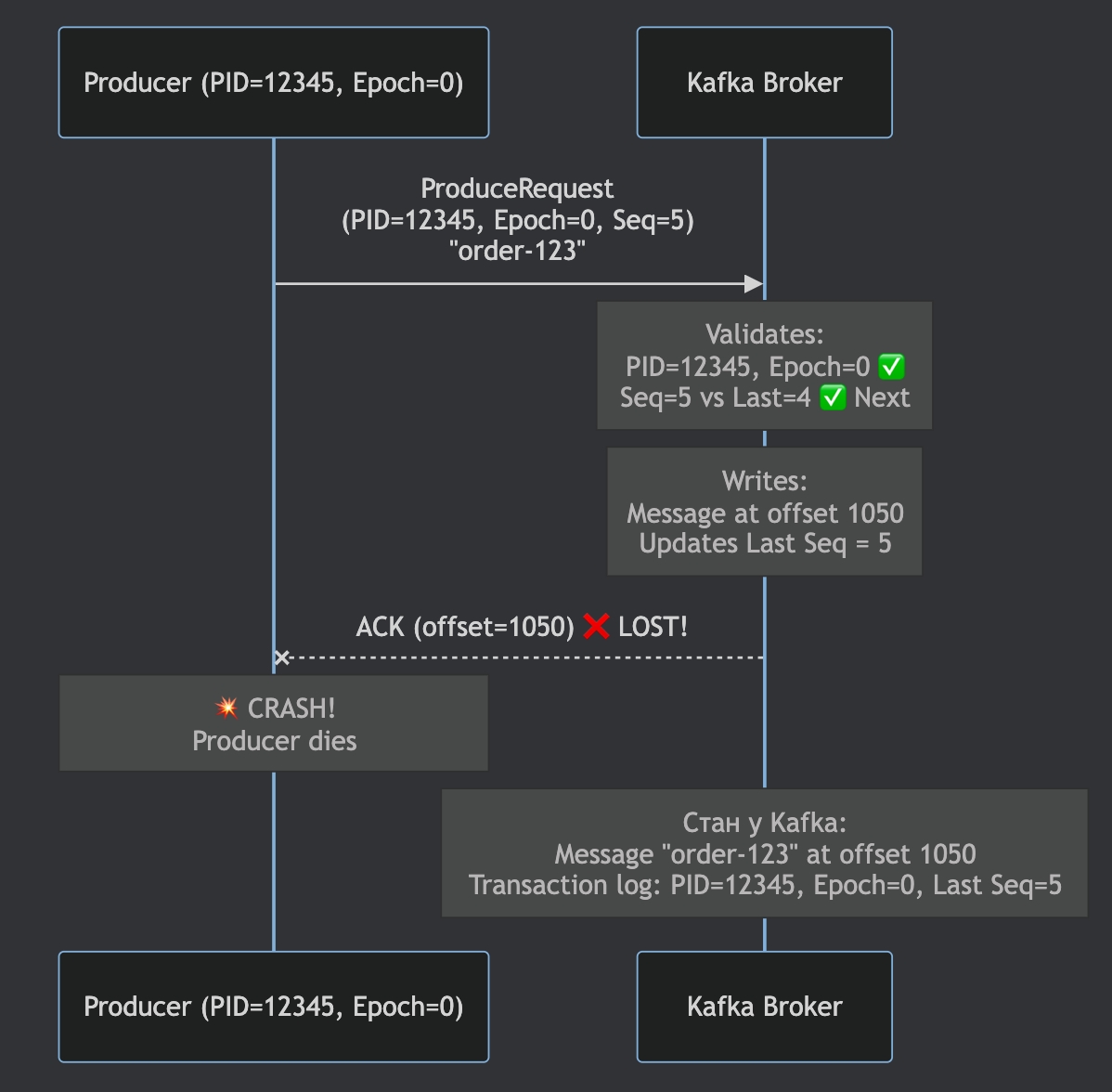
Стан Kafka після crash:
повідомлення фізично записано в log
транзакція не завершена
commit marker відсутній
offset 1050: (PID=12345, Epoch=0, Seq=5) "order-123"Це важливо: Kafka поки що не знає, чи це валідний результат транзакції.
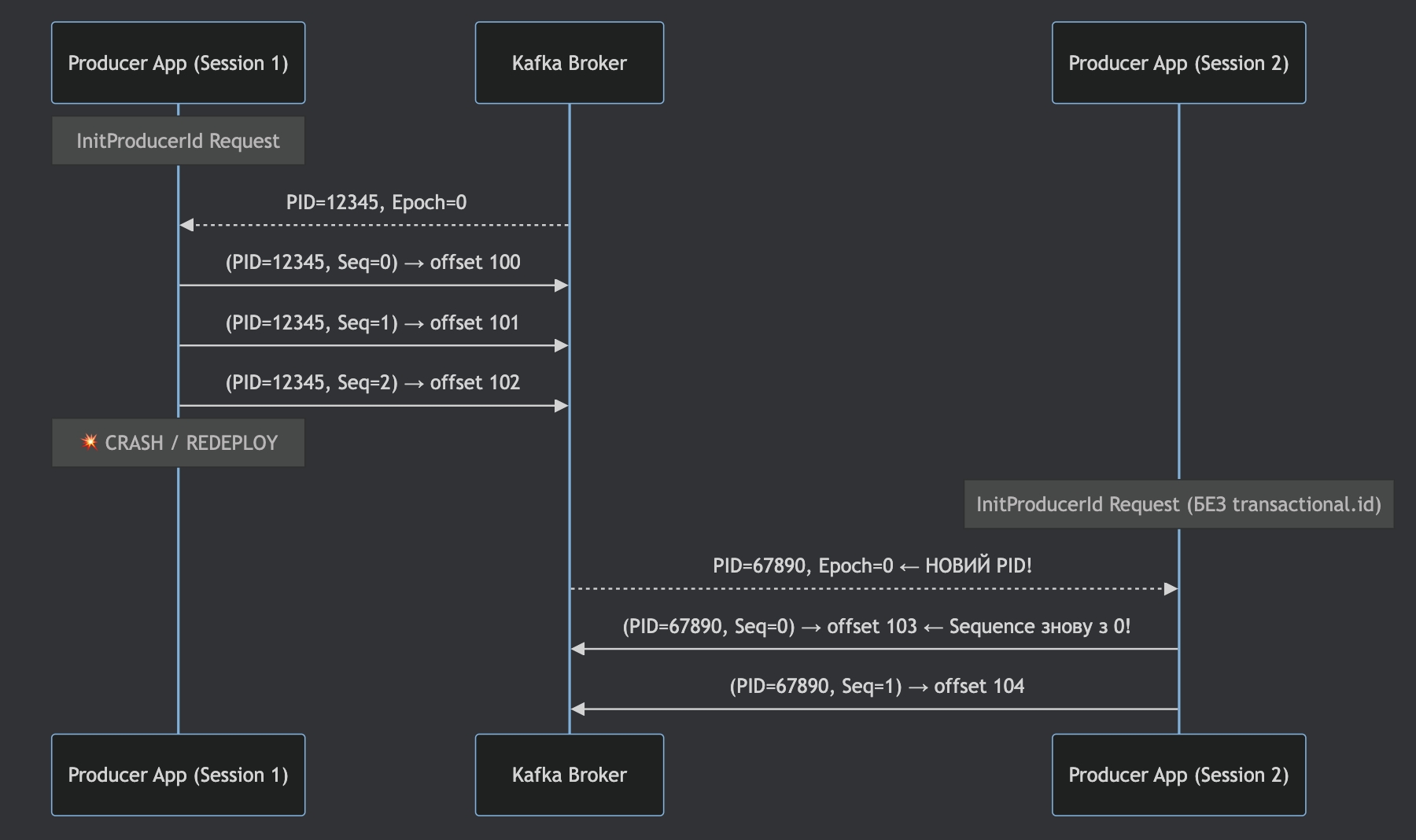
Step 3: Producer Restart — Kafka відновлює state
А ось тут починається найцікавіше.
Producer рестартує і знову відправляє InitProducerId з тим самим transactional.id
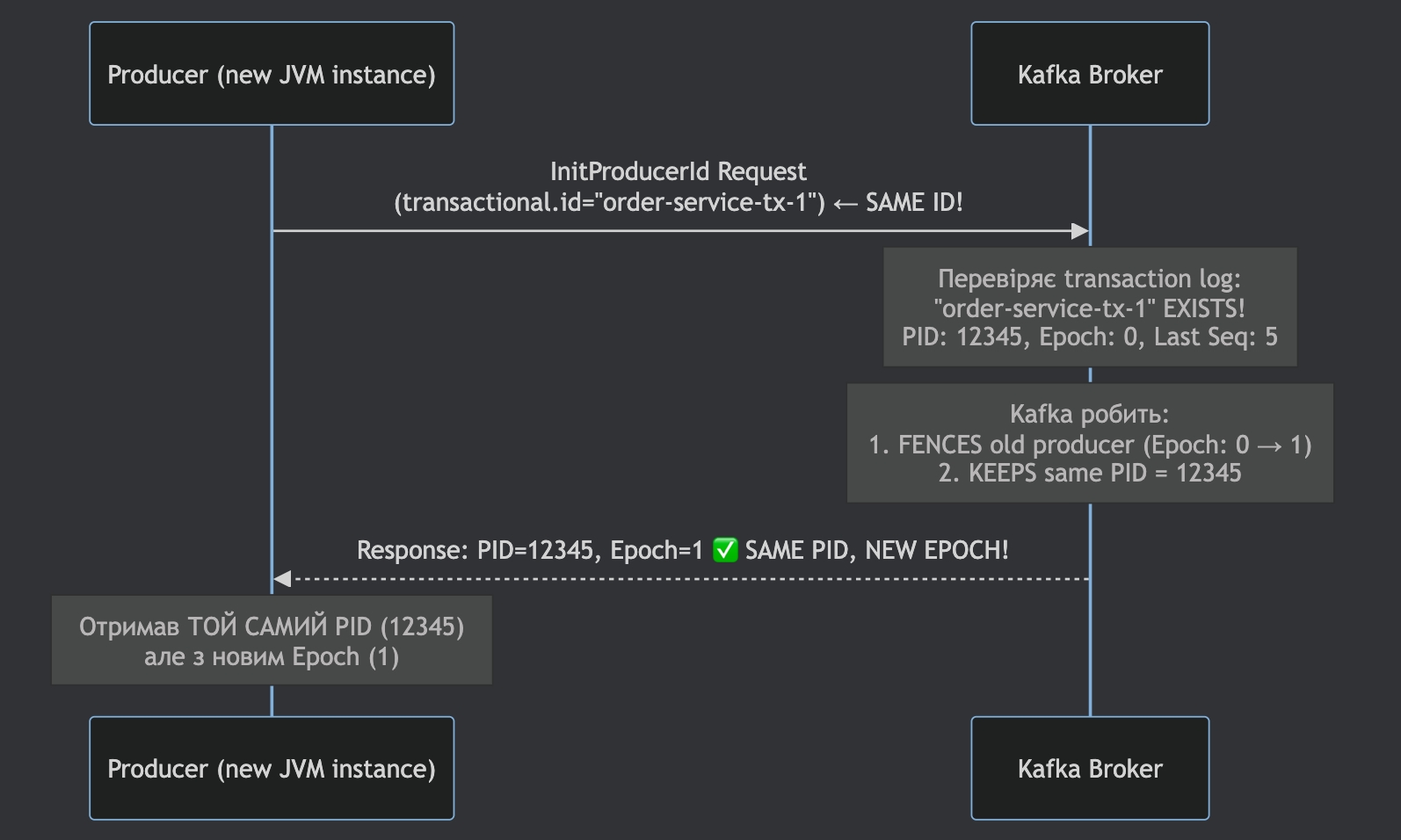
Kafka робить дві критичні операції:
Відновлює той самий PID
Інкрементує Epoch (fencing)
Будь-які записи зі старим epoch тепер вважаються невалідними. Це запобігає zombie producers (старим інстансам, що могли вижити).
Step 4: Retry після рестарту
Producer повторно відправляє повідомлення.
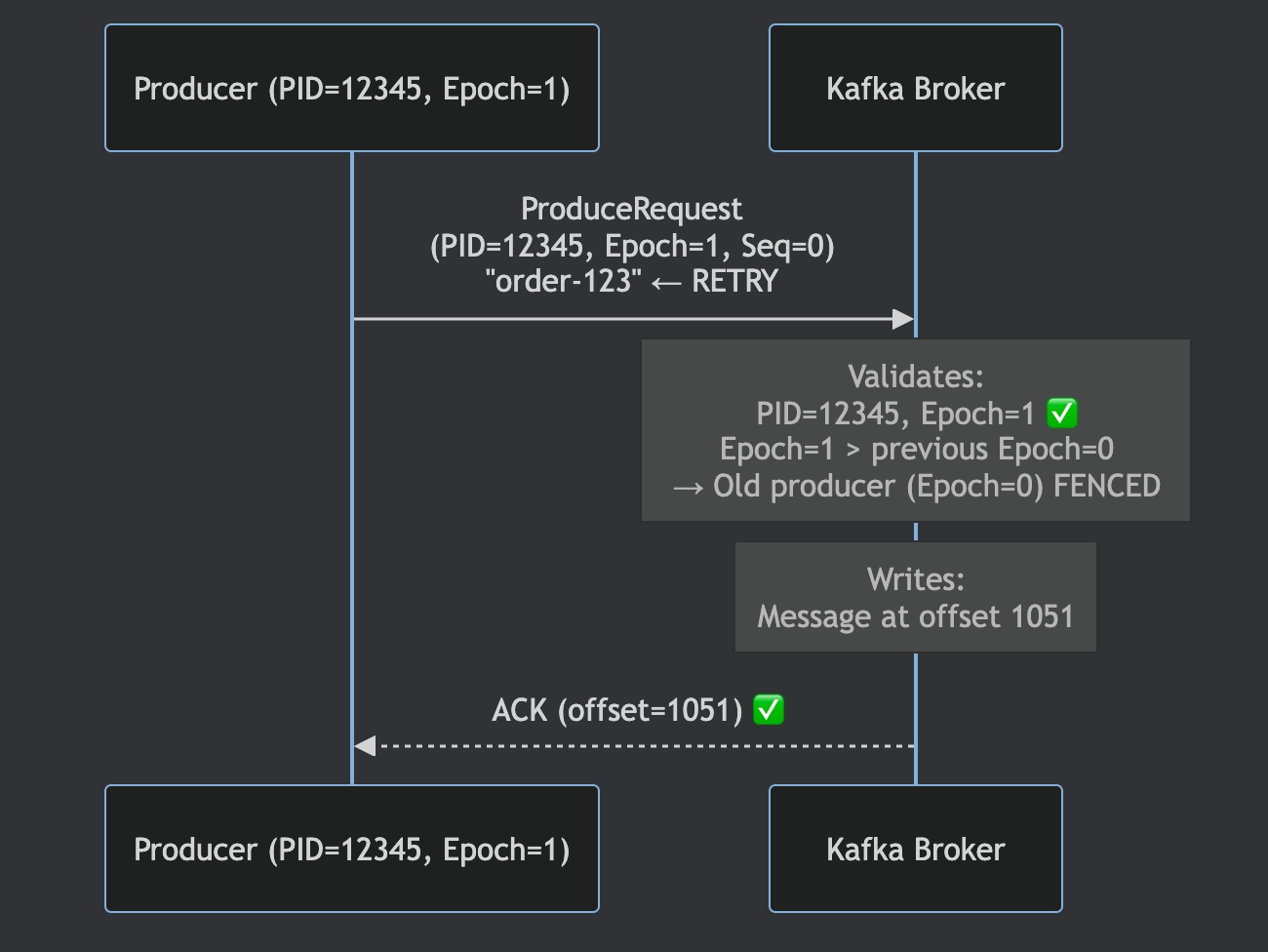
Фізично в Kafka log тепер два записи:
offset 1050: (PID=12345, Epoch=0, Seq=5) "order-123" ← From crashed producer
offset 1051: (PID=12345, Epoch=1, Seq=0) "order-123" ← From restarted producerЗдається, що є дубль — але тут вступає в гру transaction protocol.
Consumer Side — read_committed
config.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");Consumer бачить тільки committed дані:
Фізичні дані в Kafka:
offset 1050: (PID=12345, Epoch=0, Seq=5) "order-123"
↑ UNCOMMITTED! (немає commit marker, бо producer crash)
└─ Kafka позначає як ABORTED (коли Epoch змінився 0→1)
offset 1051: (PID=12345, Epoch=1, Seq=0) "order-123"
offset 1052: COMMIT marker (PID=12345, Epoch=1)
↑ COMMITTED ✅
Consumer з read_committed бачить:
✅ offset 1051: "order-123" (VISIBLE - committed transaction)
❌ offset 1050: FILTERED OUT (aborted transaction)
🎉 NO DUPLICATE! Consumer бачить тільки ОДНЕ повідомлення!Отже логічно:
🎉 Consumer отримує тільки одне повідомленняЯк саме Kafka розрізняє committed та aborted повідомлення?
Transactional Producer не видаляє дублікати фізично.
Kafka використовує механізм transaction visibility control через спеціальні control records — так звані Transaction Markers.
COMMIT marker
ABORT marker
Це спеціальні control records, які записуються в ту ж саму partition, що й data records, і визначають, чи повинні повідомлення бути видимими для consumer-а.
Приклад: що реально лежить у partition
Нехай маємо Kafka partition orders-0.
offset 1049: regular message
offset 1050: (PID=12345, Epoch=0, Seq=5) "order-123"
↑ ABORTED transaction (no commit marker before crash)
offset 1051: (PID=12345, Epoch=1, Seq=0) "order-123"
↑ Transaction started
offset 1052: COMMIT marker (PID=12345, Epoch=1)
↑ Transaction committed ✅
offset 1053: next message...
LSO (Last Stable Offset) = 1052Кожен запис у Kafka partition — чи то data record, чи то control record — отримує свій унікальний sequential offset.
Тобто COMMIT marker — це фізично окремий запис у логові partition, а не “прапорець” до попереднього повідомлення.
Процес виглядає так:
1. Producer відправляє data record → broker записує його на offset 1051 2. Producer викликає commitTransaction() → Transaction Coordinator записує окремий EndTxn (COMMIT) marker → broker записує його на offset 1052
Це два різних запити, два різних records, два різних offset-и.
Навіть якщо транзакція містить лише одне повідомлення — COMMIT marker завжди буде окремим записом.
Тобто в нашому прикладі consumer з read_committed бачить:
✅ offset 1049: regular message — нетранзакційний, видимий
❌ offset 1050: "order-123" (Epoch=0) — aborted transaction, FILTERED
✅ offset 1051: "order-123" (Epoch=1) — committed transaction, видимий
❌ offset 1052: COMMIT marker — control record, consumer не бачить
LSO (Last Stable Offset) = 1052Control records (COMMIT/ABORT markers) теж автоматично фільтруються — consumer ніколи їх не отримує в poll().
LSO (Last Stable Offset) — це offset, до якого всі транзакції мають фінальний статус (COMMITTED або ABORTED). Kafka використовує його як "межу безпеки" для read_committed consumer.
Як це працює в нашому прикладі:
Сonsumer з read_committed ніколи не читає далі LSO. Навіть якщо після LSO вже є записані data records — consumer їх не побачить, поки відповідна транзакція не завершиться. Уявімо що ми почали нову транзакцію на offset 1053
offset 1053: (PID=999, Epoch=0) "payment-456" ← transaction IN PROGRESS
offset 1054: regular message "event-789"
offset 1055: regular message "event-790"Consumer з read_committed не побачить навіть offset 1054 і 1055, хоча вони нетранзакційні. Kafka блокує все, що після незавершеної транзакції. Це гарантує порядок читання — consumer не "перестрибне"через pending транзакцію. Саме тому довгі транзакції в Kafka — це проблема: вони "притримують" LSO і блокують всіх read_committed consumer-ів від отримання нових повідомлень.
Ключові концепції
Концепція | Опис | Чому важливо |
|---|---|---|
| Stable identifier що переживає crashes | Дозволяє Kafka відновити той самий PID |
PID recovery | Kafka відновлює PID з transaction log | Забезпечує continuity sequence numbers |
Epoch | Version counter для fencing old producers | Запобігає zombie producers |
Transaction markers | COMMIT/ABORT markers у партиції | Роблять messages visible/invisible |
| Consumer isolation level | Фільтрує aborted messages |
LSO | Last Stable Offset | Гарантує що consumer не читає незавершені транзакції |
Ну от і приїхали…
Тепер видно, що Idempotent Producer та Transactional Producer вирішують різні рівні проблеми — і їх не варто плутати.
Idempotent Producer
Захищає від дублікатів при мережевих retry
Дедуплікує записи через
(PID + Sequence Number)Працює лише в межах однієї producer session
Як тільки producer рестартує:
отримує новий PID
broker більше не може пов’язати його з попереднім state
дедуплікація через restart не гарантується
Це чудове рішення для at-least-once без дублювання в межах сесії, але не для crash-consistency.
Transactional Producer
Додає стабільний
transactional.idKafka персистить mapping у внутрішньому transaction log
Відновлює producer state після рестарту
Інкрементує Epoch і фенсить zombie producers
Використовує transaction markers + LSO
У парі з
read_committedзабезпечує контроль видимості
Exactly-once досягається не через фізичне видалення дублікатів,
а через відновлення state та контроль видимості транзакцій.
Transactional Producer покриває сценарії:
crash до commit
duplicate send після restart
multi-partition atomic writes
producer fencing
Kafka не гарантує exactly-once а лише дає інструменти для реалізації і саме тут починається інженерія…

