Нещодавно я писав у своєму Telegram каналі про нову технологію RVC, яка буквально дозволяє створювати високоякісні голосові діпфейки. Я не буду повторюватись, тому рекомендую вам прочитати цей пост за посиланням для кращого розуміння цієї технології та мого ставлення до неї. За цей час я дізнався про цю розробку більше та готовий поділитися з вами цікавою та можливо, корисною інформацією про RVC.
Перед тим, як почати, хочу зазначити, що я тільки нещодавно дізнався про цю технологію і я не спеціаліст в ній. Джерела, звідки я брав інформацію, можуть бути не на 100% правдиві, тому рекомендую додатково перевіряти те, у чому ви сумніваєтесь.
📝 Для довідки: Діпфейк – це технологія, що використовує штучний інтелект для створення фальшивих відео, аудіо або зображень, які здаються реалістичними, але фактично є недостовірними.
Приклад роботи RVC
Що таке RVC?

RVC розшифровується як «Retrieval-based Voice Conversion», що в перекладі означає «Перетворення голосу на основі пошуку». Ця технологія використовує глибоку нейронну генеративну мережу для перетворення голосу диктора на інший голос.
Існують різні типи генеративного AI, такі як ChatGPT, Stable Diffusion і Midjourney. Основна концепція — штучний інтелект, який генерує нову інформацію на основі даних на яких вона навчена та вхідних даних, які надає користувач. Генеративний AI відрізняється тим, що у відповіді він генерує новий вміст, якого немає в його пам’яті.
«Retrieval-based Voice Conversion» базується на моделі VITS («Voice To Voice AI», «Штучний інтелект голос до голосу»), яка є найсучаснішою наскрізною системою перетворення тексту в мовлення та дає змогу створювати голоси на основі будь-якого вихідного голосу будь-якою мовою.
RVC можна використовувати для створення реалістичних і виразних голосових перетворень з мінімальним обсягом даних і обчислювальних ресурсів.
Хто заснував цю технологію та зробив великий внесок в її розвиток? На жаль, я не знайшов якоїсь конкретної інформації. Можу сказати те, що технологію RVC розробили в Японії, де її активно розвивають та використовують. Також я знайшов англомовний Діскорд сервер, де люди спілкуються між собою на тему пов’язану з цією розробкою, діляться моделями (там є гілки з чатами і з іншими мовами, проте української там немає). Підсумовуючи, RVC підтримується та розвивається за рахунок її спільноти.
Як навчається RVC?
Тут буде пояснюватися внутрішня робота RVC, особливо механізм навчання. Для розуміння природи цієї моделі потрібно знати, як штучний інтелект вивчає особливості набору даних.
Всі дані, які ми передаємо для навчання розташовуються в просторі. Простір, у якому вони розміщуються, називаються «латентним простором». Нижче ви можете побачити, як він може виглядати у RVC.
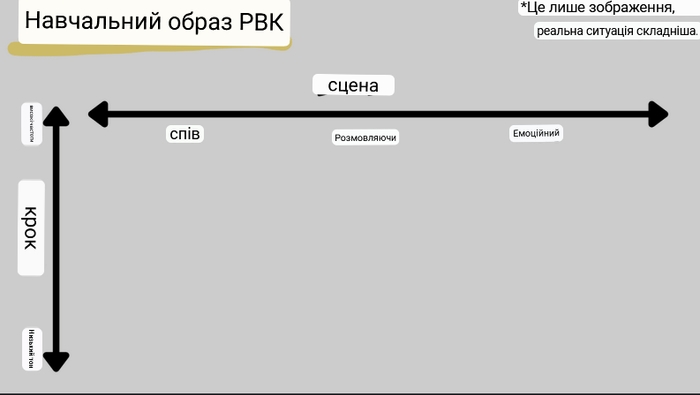
(❕Увага❕) Наведені зображення латентного простору, можуть сильно відрізнятися від фактичного латентного простору RVC, тому, будь ласка, не сприймайте наступний вміст як абсолютну істину, а розглядайте його як матеріал для кращого розуміння технології.
Тут ми припускаємо, що латентний простір RVC є двовимірним. На двовимірній осі вертикальна вісь — висота звуку, а горизонтальна — місце дії (читання, емоційне вираження, спів тощо).
Розгляньмо конкретний процес навчання. Для прикладу розглянемо випадок вивчення фрази «Hello».
По-перше, «Hello» ділиться на символи та кожен звук відповідає латентному простору (у фактичній роботі він ділиться на більш детальні часові сегменти). Цього разу ми ставимо умову, щоб фраза «Hello» була звичайним розмовним виразом і персонаж говорив на відносно високому тоні.
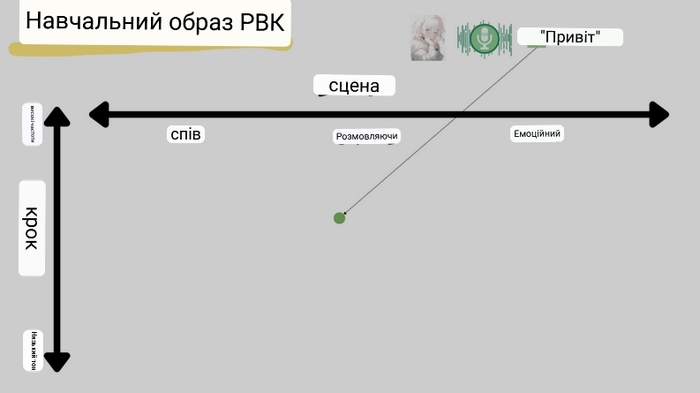
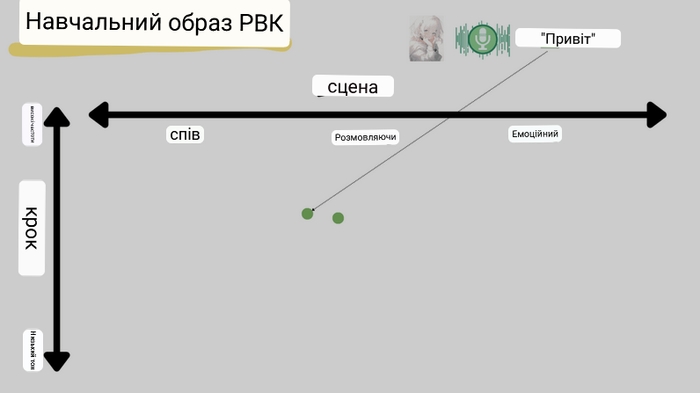
Коли ці аудіодані вивчаються, звуки розміщуються в певних місцях у просторі. Зокрема, «Hello» героїні буде розміщено в позиції, що відповідає сцені, в якій вона зазвичай говорить на відносно високому тоні.
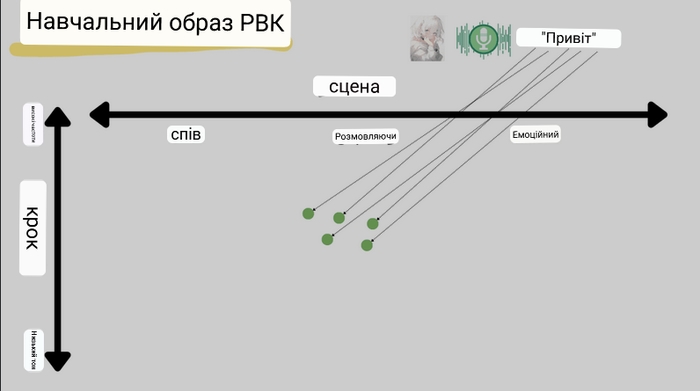
Потім вводяться різні голосові дані, і в міру навчання, характеристики голосу персонажа виражаються на латентному просторі. Наприклад, якщо набір даних містить не лише розмовні вирази, а й емоційні, голос персонажа-героїні буде розподілено у відносно високому діапазоні між звичайними розмовними словами та емоційними виразами.
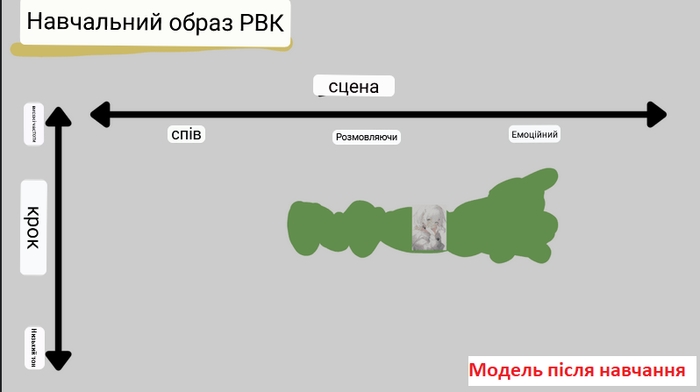
Таким чином, модель можна навчити на широкому спектрі даних, що містять суміш різноманітних характеристик і нюансів, які вивчаються та впорядковуються на латентному просторі. Це є базою, завдяки якій RVC може відтворювати різні голосові якості та стилі мовлення.
Як працює RVC?
Коли в навчену модель RVC подається аудіо з голосом людини, який потрібно перетворити, модель змінює мовлення на основі заданих функцій.
Спочатку ми аналізуємо голос, який вимовляє користувач. У цей час він розбивається на невеликі частини і обробляється, так само як і під час навчання. Як приклад, ми аналізуємо фразу «Hello» та наносимо фонетичні особливості на латентний простір. Припустимо, що тут говорить людина з низьким голосом. У цьому випадку відображена позиція також буде розміщена в діапазоні низьких частот.
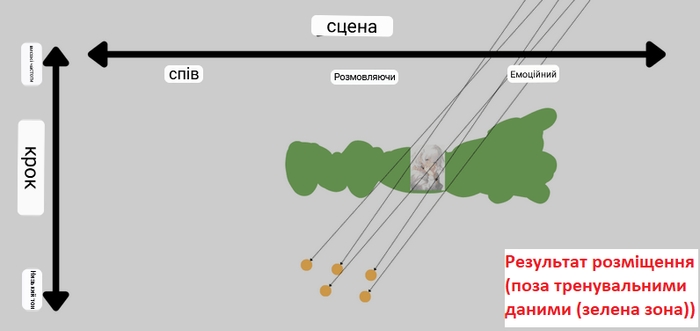
Однак є одна проблема. Вхідний (переданий) звук може не існувати ні в одній області латентного простору, отриманого під час навчання. Іншими словами, коли надається вхід із характеристиками мовлення, які модель не вивчила, важко конвертувати мовлення належним чином.
Ось де «перетворення висоти» вступає в гру. Перетворення висоти — це функція, яка змінює тональність голосу. Використовуючи це, можна налаштувати тональність вхідного голосу та перемістити його в діапазон, близький до даних під час навчання.
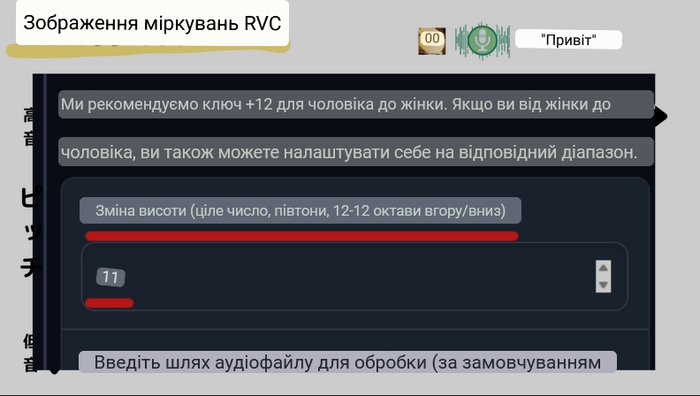
Наприклад, якщо хлопець хоче перетворити голос на жіночий, або дівчина хоче змінити свій голос на чоловічий використовується перетворення висоти, щоб зробити це як можна краще. Таким чином, голос користувача налаштовується на відповідну позицію в латентному просторі, і виконується перетворення голосу.
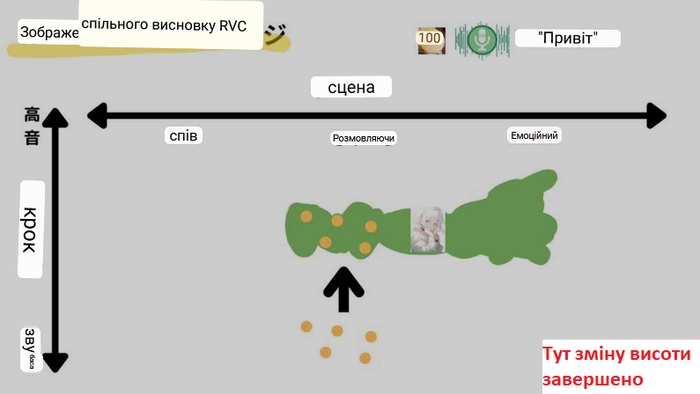
У цей час основою для перетворення є дані, отримані під час навчання, і вони приймаються майже такими, як є. У результаті голос користувача буде перетворено на вивчений цільовий голос на основі його характеристик.
Якщо все пройшло добре, голос користувача перетворюється на природний вихідний голос іншої людини. Таким чином вимова фрази «Hello» перетворюється не дивлячись на стать людини, яка говорить у переданому аудіо та стать людини на чиєму голосу і була навчена модель.
Однак тут слід зазначити, що якість цього перетворення значною мірою залежить від ступеня відповідності між введеною мовою користувача та навчальними даними. Зокрема, коли характеристики вхідного мовлення не збігаються з навчальними даними, правильне перетворення стає складним. Саме тому важливо налаштувати вхідне мовлення за допомогою перетворення висоти тону та інших технологій, на кшталт очищення від шумів, щоб наблизити його до навчальних даних. Також важливим є якість самої моделі.
Від чого залежить якість моделі?

Думаю, багато хто вважає, що якість моделі залежить в першу чергу від кількості вхідних даних. Насправді це не зовсім так, але я теж раніше так гадав. RVC розроблено на основі існуючої моделі, тому для створення своєї достатньо відносно невеликої кількості високоякісного голосу з низьким рівнем шуму.
Тобто, якщо є купа аудіо, наприклад, на 500 годин і в ньому є багато шуму й інших завад, якість моделі буде на незадовільному рівні + для навчання потрібно буде багато часу.
Рекомендовано створити невеликі відрізки аудіо (десь по 10 секунд) без сторонніх шумів й з різним емоціональним спектром (звичайний голос, переляканий тощо). Поширена думка, що мінімальна кількість високоякісного аудіо для навчання – це приблизно 10 хвилин.
Підсумовуючи, важливо, щоб дані навчання для RVC були «хорошими», а не «чим більше, тим краще». Іншими словами, середовище запису голосових даних і різноманітність вмісту, що читається вголос, сильно впливають на продуктивність моделі.
Які є аналоги RVC?
RVC не перша технологія, яка була розроблена для створення голосових діпфейків. До неї була SVC, або «Singing Voice Conversion», що в перекладі означає «Перетворення співочого голосу». Так, її основна мета саме змінювати голос вокалу. Її робота схожа на RVC, проте не така ефективна.
SVC вже можна вважати застарілою технологію, хоча вона була винайдена зовсім нещодавно. Зараз нові удосконалені розробки у сфері штучного інтелекту з’являються дуже швидко. RVC швидше і якісніше виконує свої задачі, не потребує так багато ресурсів. Хоча ще можна знайти моделі, які створені завдяки SVC, но їх стає все менше та ком’юніті активно критикує використання цієї технології та призиває перейти до RVC.
Також за альтернативу можна використовувати технологію TTS (Text To Speech, у перекладі Текст В Голос) - це технологія, яка розшифровує цифровий текст і синтезує з нього мову за допомогою штучного голосу. Порівнюючи з RVC, ця розробка вже працює інакше та існує багато років. Можна створити свою модель, але для цього потрібно багато ресурсів та часу. Ось посилання на цікаву українськомовну статтю на цю тему.
Про етичність цієї технології

Хочу зазначити, що можна створити модель голосу будь-якої публічної людини. Для цього потрібно тільки отримати достатню кількість вхідних даних. Готову модель можна використовувати в будь-яких цілях: як для хороших, так і ні.
Пам’ятайте, що краще використовувати та створювати свої моделі тільки у випадку, якщо у вас є дозвіл на це. Не виходьте за рамки етичності, моралі та закону. Необхідно поважати авторські права.
Увага! Ця стаття не призиває створювати, або використовувати RVC моделі та написана для ознайомлення.
fin.
На цьому перша частина статті, яка розповідає про RVC завершено. При написанні цього довгочиту були використані декілька ресурсів. З одного із них була взята велика частина інформації та навіть ілюстрації, тому окрема дяка її автору mossan_hoshi і дублюю посилання на його публікацію. Крім цього, посилання на інші джерела на тему RVC, які навіть не були використані у цьому довгочиті, ви зможете знайти у низу публікації, рекомендую вам ознайомитися з ними.
Найближчим часом вийде друга частина цієї статті, де вже буде розповідатися, як створити свою модель, де можна знайти готові моделі, як користуватися моделями тощо. Після її публікації я планую додатково записати велике відео на цю тему й опублікувати його на своєму YouTube.
Також буде знято відео як створити невеликий фільм використовуючи різні технології діпфейку, але воно вже буде доступне тільки підписникам мого Донателло починаючи з тарифу “Крутий жаб” за 180 гривень на місяць. Кошти з цієї платформи будуть йти на фінансування безкоштовних проєктів (наприклад, безоплатний переклад відео YouTube з англійської на українську мову (детальніше)). Це не обов'язково та я в ніякому разі не закликаю надсилати мені кошти, проте якщо у вас є бажання підтримати український контент, буду вдячним.
Також рекомендую підписатися на мій Telegram канал, де я ділюся всіма анонсами й купою цікавих і корисних публікацій.
На цьому все, дякую за увагу. Пишіть коментарі, хлопайте у долоні, підписуйтесь. До скорих зустрічей! 😉

Джерела:
1. https://guidady.com/rvc-ai/
2. https://www.techno-edge.net/article/2023/04/12/1146.html

