Це друга частина довогочиту на тему RVC. Хто не знає, ця технологія дозволяє перетворювати голос однієї людини на інший. Саме завдяки їй створюють діпфейки, де заставляють якихось відомих людей говорити що завгодно.
Тут ви дізнаєтесь де можна знайти готові навчені моделі RVC, як створити свою (це може бути як і ваш голос, так й іншої людини), як використовувати моделі та замінувати голос.
В першій частині я пояснив, як працює технологія RVC. Якщо ви її не читали, рекомендую спочатку прочитати саме першу частину, а потім перейти до другої.
Перед початком наголошу, що стаття зроблена для ознайомлення та не призиває до дії. Не виходьте за рамки етичності, моралі та закону. Поважайте себе та інших, пам’ятайте про авторське право. За всі свої дії ви відповідаєте самостійно.

Приклад роботи моделі RVC на прикладі мого голосу
Де взяти готові моделі RVC?
Це не дуже розповсюджена технологія, проте її доступність дозволяє ентузіастам швидко створювати нові моделі, завдяки чому в інтернеті вже доступна велика їх кількість. Як правило, моделі навчають на базі голосів відомих людей, акторів, різних персонажів.
Саме тому, якщо ви хочете використати голос якоїсь публічної людини, можна спочатку перевірити, чи не створив хтось його модель та не опублікував її в інтернеті. Для цього вже є багато тематичних ресурсів. Я поділюся посиланнями на деякі із них, але пам’ятайте про авторське право.
Англомовний Discord сервер (є багато моделей; деякі із них – копії голосів відомих українців) - https://discord.gg/v5fctx3J
«Склад» моделей на HuggingFace - https://huggingface.co/QuickWick/Music-AI-Voices/tree/main
П’ять японських моделей від одного автора – клік 1, клік 2, клік 3, клік 4, клік 5.
Як створити свою модель RVC?
Це не дуже складно та не займає багато часу, якщо порівнювати з навчанням інших, пов’язаних зі штучним інтелектом моделей, тому впевнений, що у вас все вийде 🙂
Запис та обробка датасету (голосу)
Спочатку потрібно підготувати датасет – це те, на чому ви будете навчати свою модель. Я буду навчати RVC перетворювати свій голос. Ви ж можете спробувати зробити таке зі своїм.
Як ви вже знаєте з першої статті (сподіваюсь, що знаєте) для навчання своєї моделі потрібно мінімум 10 хвилин запису голосу. Для кращої якості бажано виключити шуми, сторонні звуки та додати запис аудіо з різним емоційним спектром.
Я рекомендую вам завантажити програму Krisp, яка автоматично, використовуючи машинне навчання, прибирає шуми та сторонні звуки.
Для запису аудіо будемо використовувати програму з відкритим кодом під назвою Audacity.
В їх установці немає нічого складного, тому я не буду додатково описувати цей процес (як встановити Audacity, як встановити Krisp).
Спочатку запускаємо Krisp та переконуємося, що він працює.
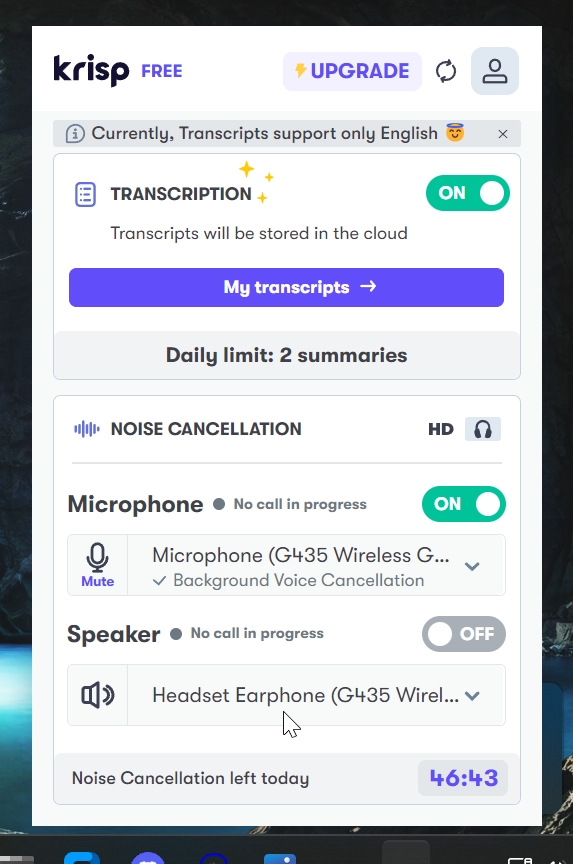
Настала черга Audacity.
Запустіть програму.
Зайдіть у розділ Зміни --> Параметри (Ctrl + P).
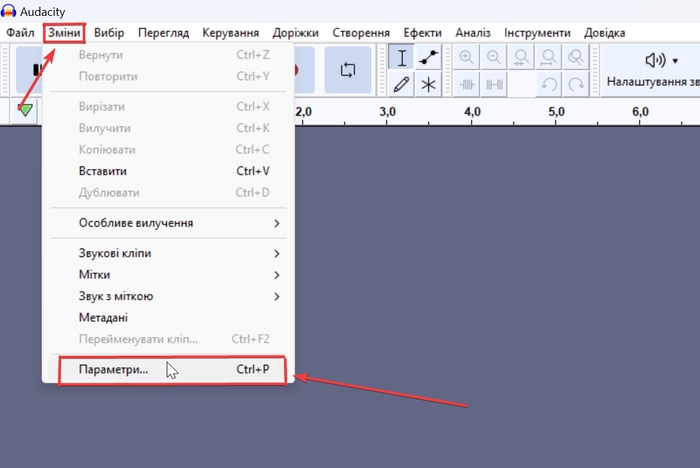
Перейдіть до Параметри звуку.
У Відтворення --> Пристрій виберіть потрібний вам пристрій, куди буде відтворюватися звук.
У Запис --> Пристрій повинен бути обраний Krisp Microphone. Якщо його немає у списку, перезавантажте Audacity. Якщо це не допомогло, то у вас проблеми з Krisp: перевірте програму на коректність роботи.
Збережіть зміни: натисніть на кнопку Гаразд.
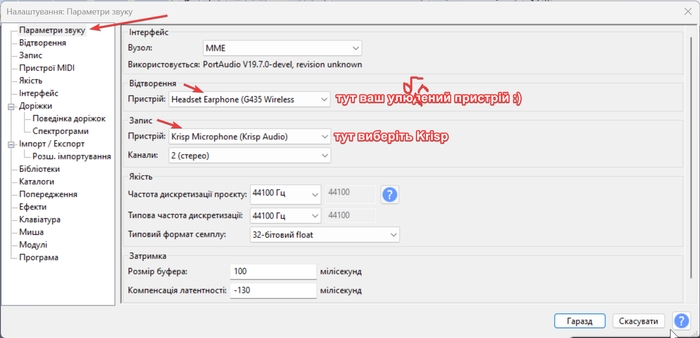
Тепер необхідно записати аудіо з вашим голосом. Особисто я просто прочитав вірші Лесі Українки «Contra Spem Spero!» та Тараса Шевченко «Мені тринадцятий минало...». Це у сумі 4 хвилини. Також я прочитав новину «48 школярів з Донеччини отримали найвищий бал за НМТ» (+2 хвилини). У фіналі я знайшов на Вікіпедії статтю про фільм «Інтерстеллар» (дуже класний фільм, раджу його подивитися) та зачитав блок Сюжет (+8 хвилин). Від шуму аудіо можна не чистити, оскільки це зробив за нас Krisp, а ось нормалізацію вже бажано провести. Для цього виберіть все аудіо (Ctrl + A), Ефекти --> Гучність і стискання --> Нормалізація --> Застосувати.
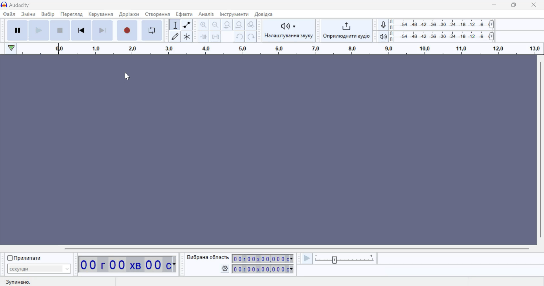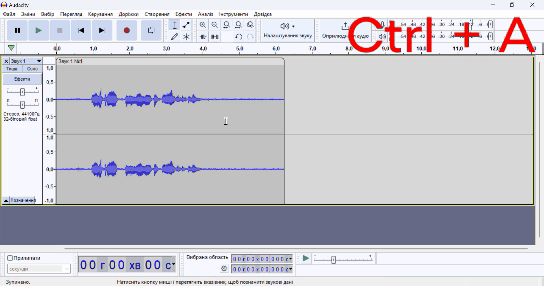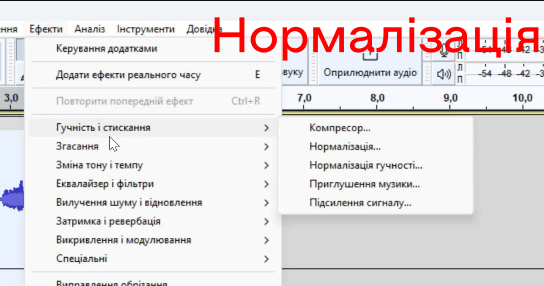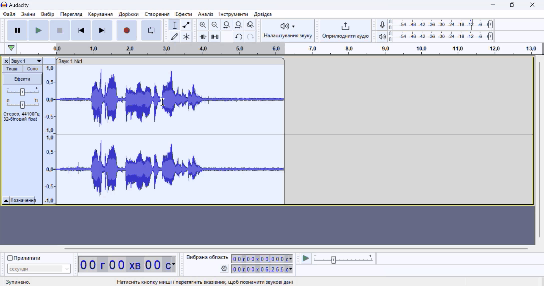
На гіфці вище ви можете побачити шуми на місцях, де я мовчу. Такого у вас не повинно бути, якщо Krisp працює нормально!
Далі потрібно вирізати місця, де ви мовчите, запинаєтесь тощо. Для цього виберіть курсором необхідну ділянку, яку потрібно видалити, та натисніть на клавішу Delete.
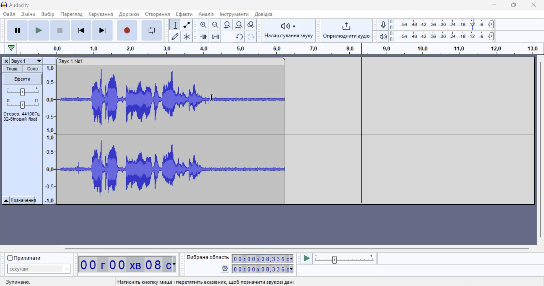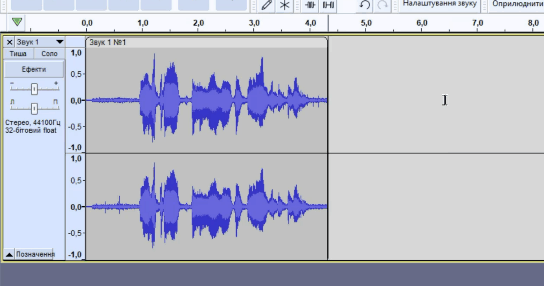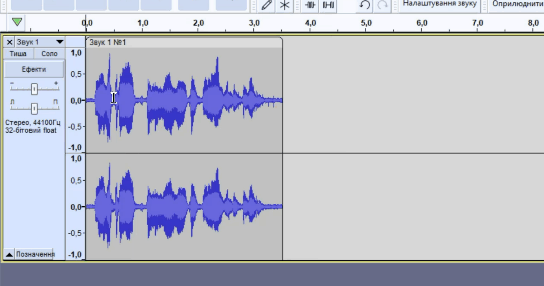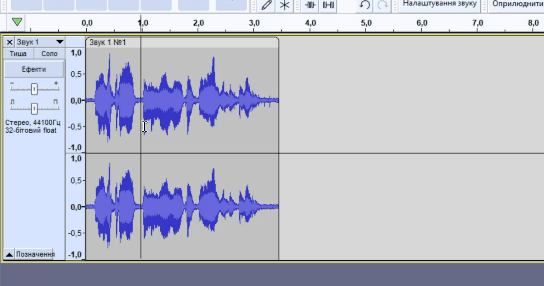
Аудіо запис потрібно поділити на відрізки десь по 10 секунд. Це можна зробити вручну завдяки Audacity, а можна і автоматизувати. Єдиний мінус в такому автоматичному підході – це те, що ваші слова можуть бути обрізані, що може негативно вплинути на якість моделі. Саме я вдався до автоматичного підходу і розповім саме про нього. Готове велике аудіо зберігаємо у форматі WAV з кодуванням 32-bit float з назвою audio.
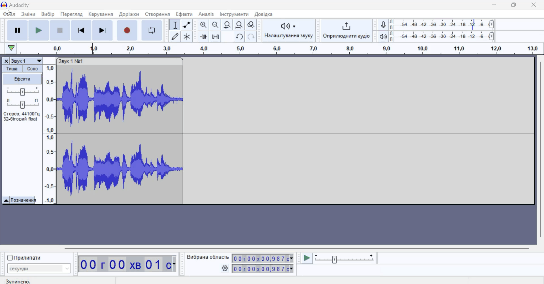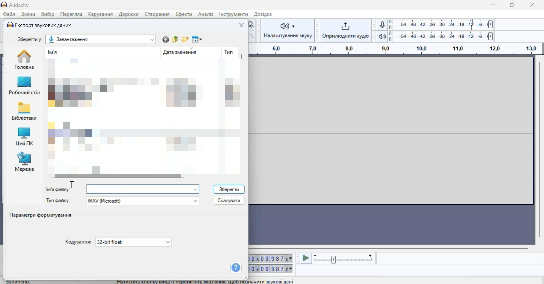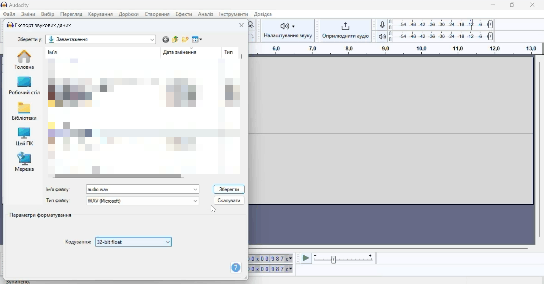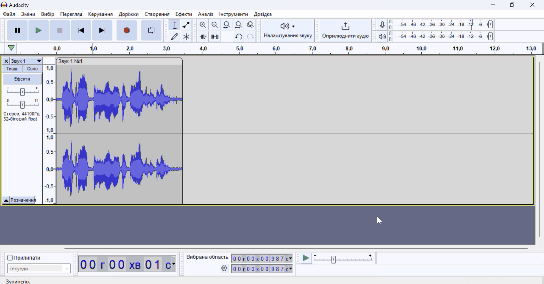
Я написав невеликий скрипт, можете використовувати його для обрізки аудіо рівно на проміжки по 10 секунд. У вас повинен бути встановлений Python та бібліотека SoundFile. Створіть окрему теку. В ній створіть файл main.py та помістіть в нього код нижче.
import os
import soundfile as sf
def split_audio_wav(input_file, output_directory, duration=10):
# Завантаження аудіофайла
audio, sr = sf.read(input_file)
# Обчислення тривалості аудіофайлу в секундах
audio_duration = len(audio) / sr
# Визначення кількості відрізків
num_segments = int(audio_duration / duration)
# Створення директорії для збереження відрізків
os.makedirs(output_directory, exist_ok=True)
# Розрізання аудіофайлу на частини
for i in range(num_segments):
# Обчислення часових міток для початку і кінця відрізка
start_time = i * duration
end_time = (i + 1) * duration
# Отримання індексів семплів для початку та кінця відрізка
start_index = int(start_time * sr)
end_index = int(end_time * sr)
# Отримання відрізка аудіо
segment = audio[start_index:end_index]
# Формування імені файлу для збереження відрізка
output_file = os.path.join(output_directory, f"segment_{i+1}.wav")
# Збереження відрізка у вигляді WAV-файлу
sf.write(output_file, segment, sr, format='WAV')
print(f"Відрізок {i+1} збережено як {output_file}")
def start():
input_file = "audio.wav"
output_directory = "segments"
print("Початок...")
split_audio_wav(input_file=input_file, output_directory=output_directory)
print("Готово, відрізки збережено у теку " + output_directory)
if __name__ == "__main__":
start()
В цю теку помістіть ваш аудіо файл з Audacity, він повинен мати назву audio.wav. Запустіть скрипт. Для цього увімкніть термінал та введіть наступні команди:
cd повний шлях до папки
python main.pyДочекайтеся закінчення обробки аудіо.
На цьому кроці датасет повністю готовий. Можна переходити до наступного кроку.
Тренування (навчання) моделі
Тепер саме цікаве. Ми будемо тренувати свою модель на Google Colab. Він дозволяє запускати код, створювати та редагувати Notebook-и. Особливістю Colab є можливість безкоштовного використання обчислювальних ресурсів, включаючи процесори та графічні прискорювачі для виконання складних обчислювальних задач. Тобто ви можете створити свою модель RVC навіть на слабому пристрої, ваші ресурси не будуть залучені.
Для цього перейдіть за посиланням. Дочекайтеся завантаження сторінки та продублюйте цей Notebook до себе (Файл --> Зберегти копію на Диску).
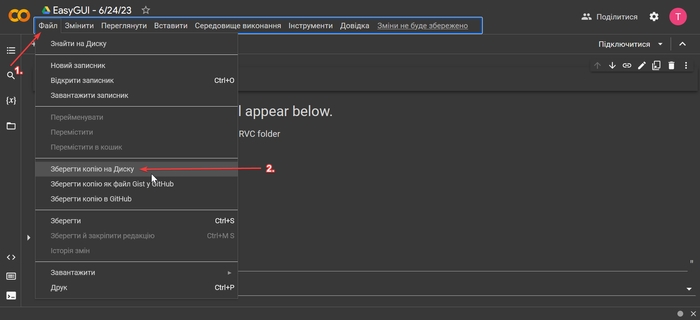
В новому вікні ми вже будемо робити всю магію. Запустіть перший блок під назвою «Open the public URL that will appear below» натиснувши на кнопку плей.
Дочекайтесь появи «Running on public URL». Перейдіть за посиланням.
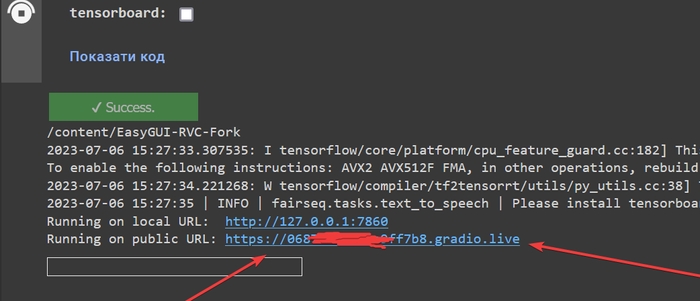
Відкриється сторінка з вмістом, як на скріншоті нижче. Перейдіть на вкладку «Train».
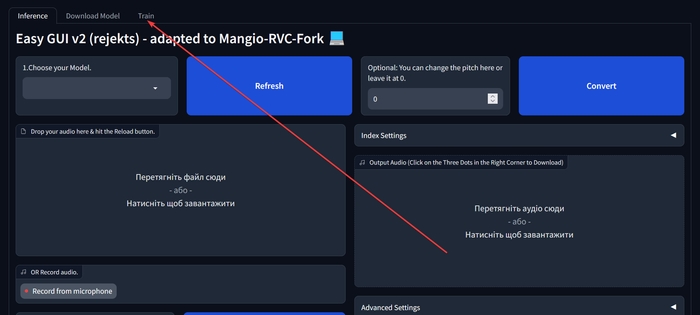
В «Voice Name» введіть назву вашої моделі, наприклад, можете використовувати своє ім’я чи псевдонім.
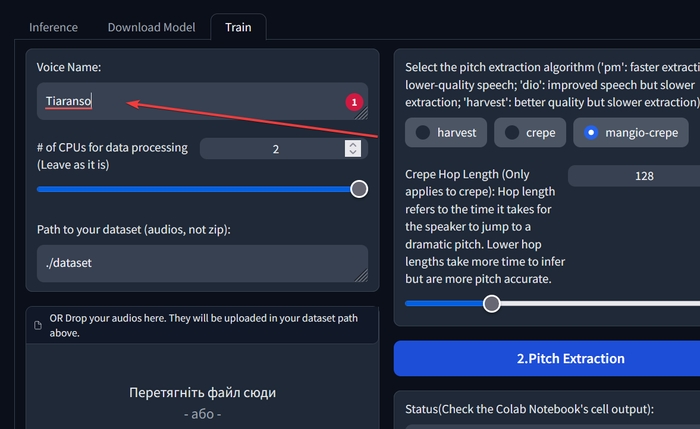
Трохи нижче натисніть на «Натисніть, щоб завантажити». Завантажте всі аудіофайли в форматі wav, які ви порізали на проміжки по 10 секунд.
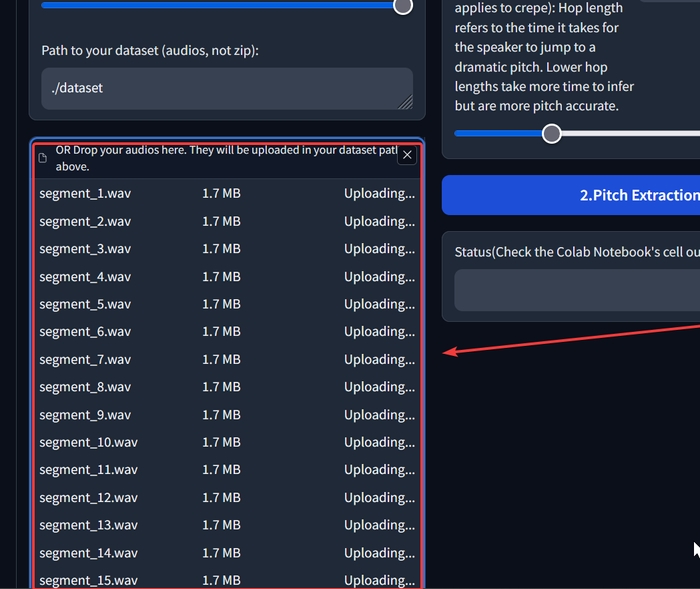
Дочекайтесь, поки всюди напис «Uploading…» заміниться на «Download». Натисніть на кнопку у самому низу «1.Process The Dataset».
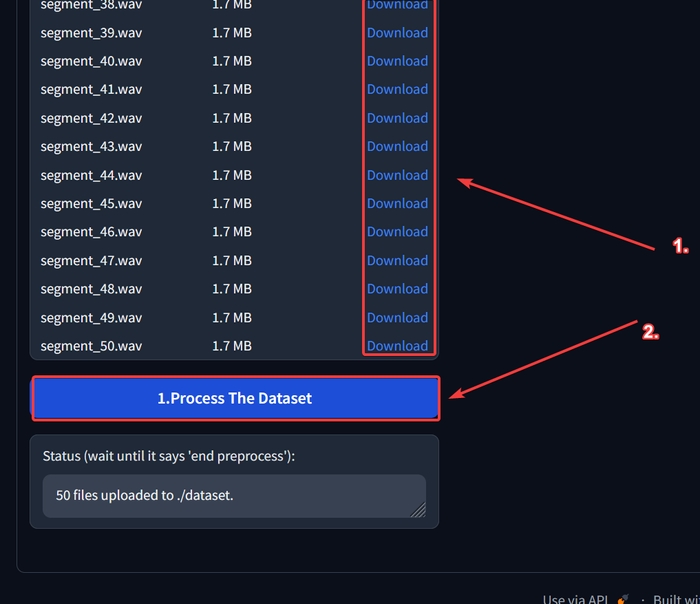
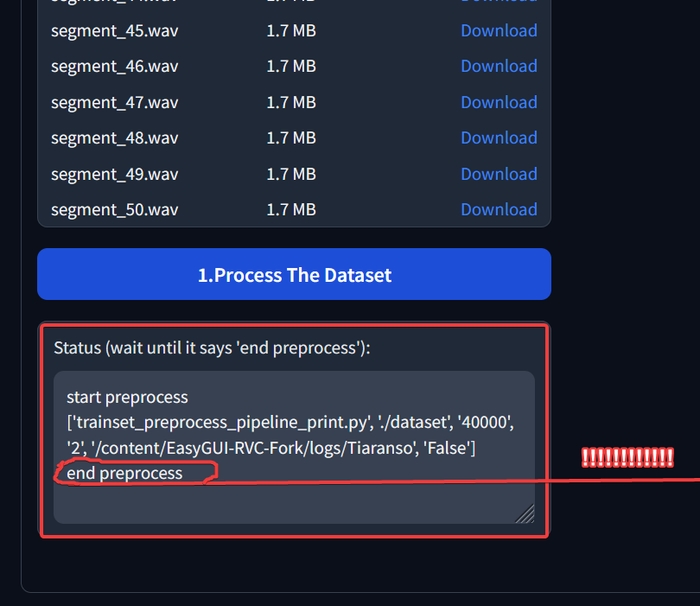
Дочекайтесь, поки у самому низу в блоці «Status» з’явиться напис «end preprocess».
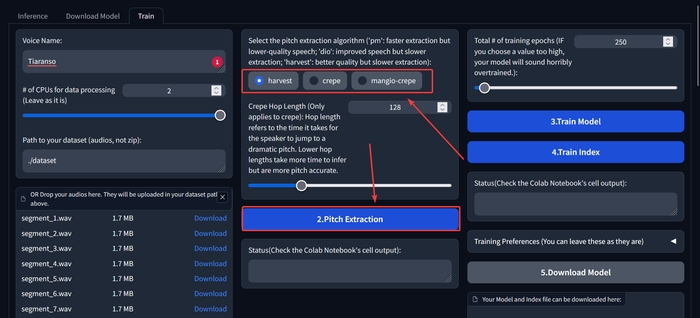
Тепер потрібно вибрати алгоритм видобування висоти тону.
«harvest» - швидка обробка, але низька якість моделі.
«crepe» - потрібно більше часу, але покращена якість моделі.
«mangio-crepe» - потрібно ще більше часу, але якість моделі ще краща.
Це так, як я зрозумів (може щось плутаю). Виберіть потрібний алгоритм та натисніть на кнопку «2.Pitch Extraction».
Знову перейдіть на сторінку Google Colab та дочекайтеся напису «all-feature-done».
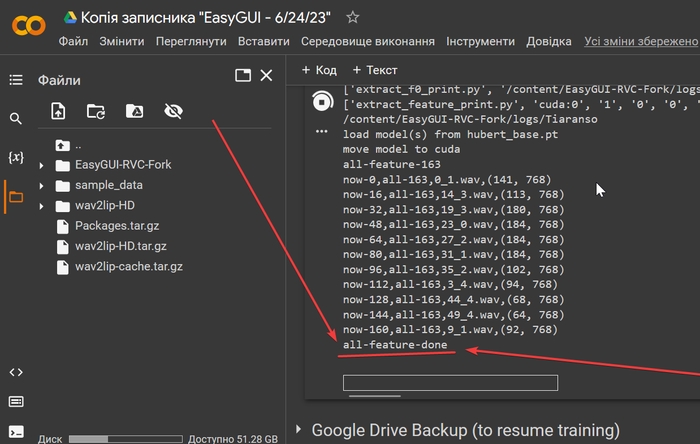
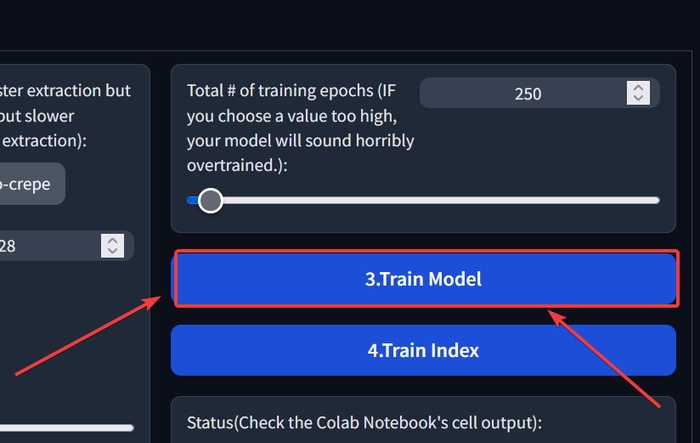
Знову поверніться на попередню сторінку. Натисніть на «3.Train model».
Знову увімкніть колаб. Дочекайтеся напису «Training is done. The program is closed».
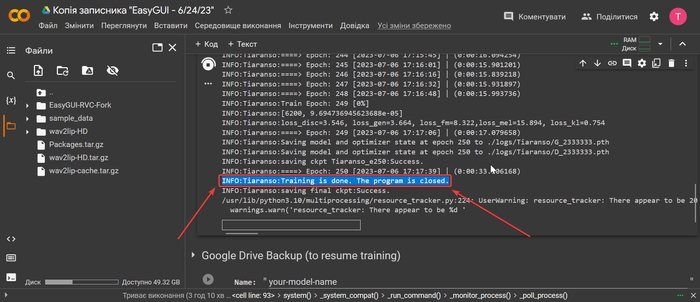
Повертаємося назад та натискаємо кнопку «4.Train Index».
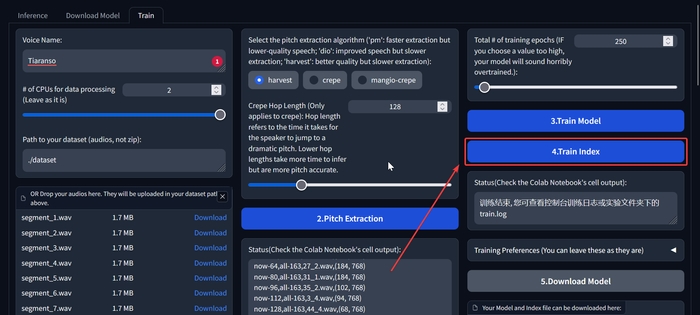
Чекаємо на напис «щось.index».
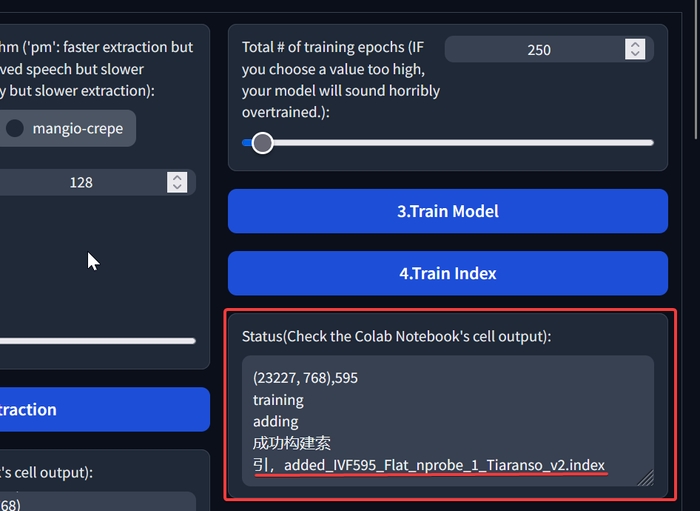
Натискаємо на фінальну кнопку «5.Download Model».
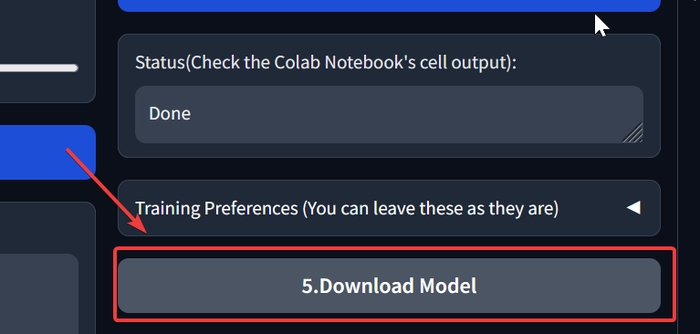
Зберігаємо .pth та .index файли.
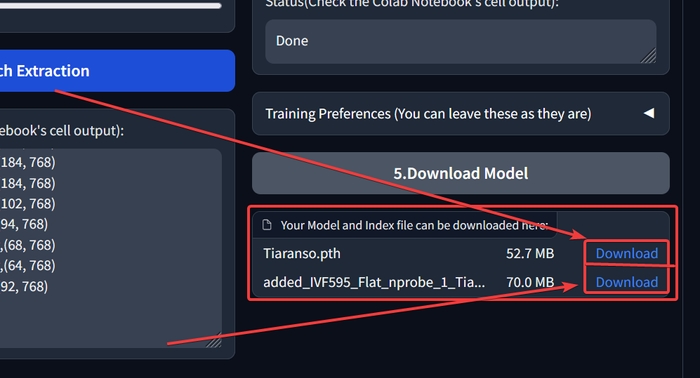
Після завантаження файлів можете сміливо (та гордо) вимикати ці дві вкладки. Вітаю, ви створили свою власну модель.
Як використовувати готову модель та замінити голос?
Підготовка програми
Для цього можна використовувати спеціальну Open Source програму. Для її встановлення перейдіть за цим посиланням на її репозиторій в GitHub. Натисніть на Code, Download ZIP.
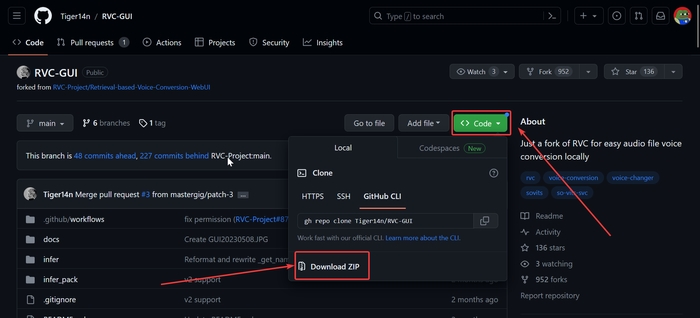
Завантажений архів розархівуйте в окрему теку. Запустіть файл RVC-GUI.bat
Чекаємо, поки запуститься програма.
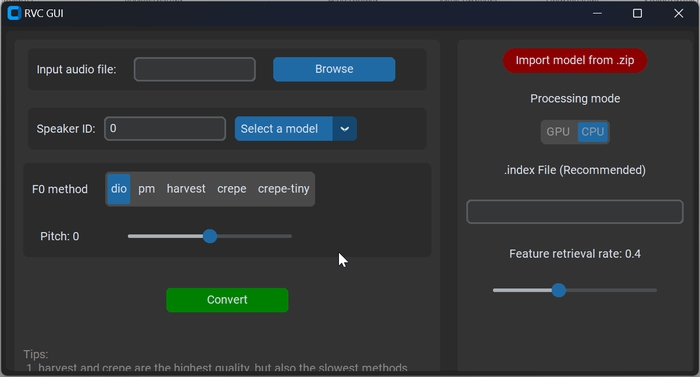
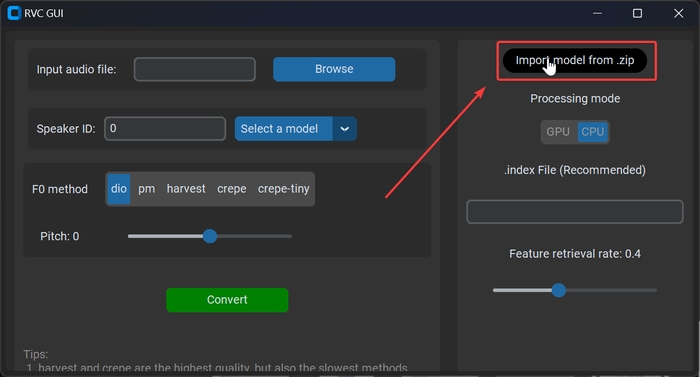
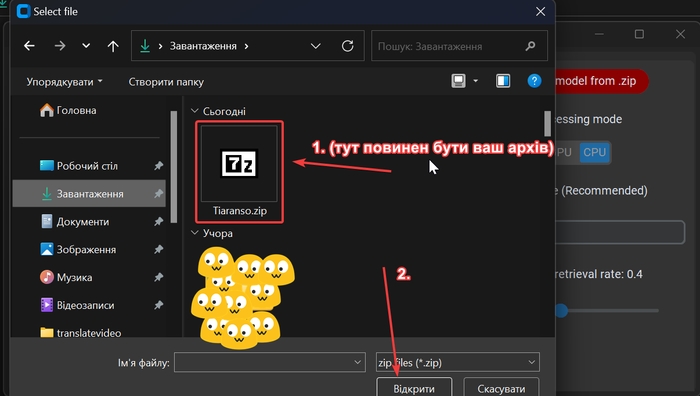
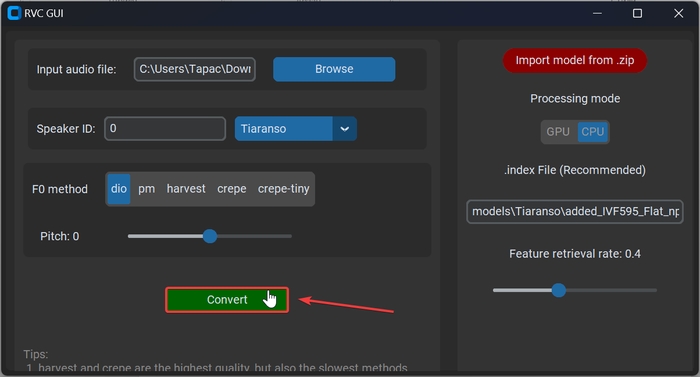
Тепер потрібно завантажити свою модель в zip форматі. В архіві повинні бути файли .pth та .index, наголошую, що підгримуються тільки моделі RVC. Натискаємо на «Import model from .zip» та вибираємо архів.
Модель повинна була з’явитися в списку, як на скріншоті. Вибираємо її.
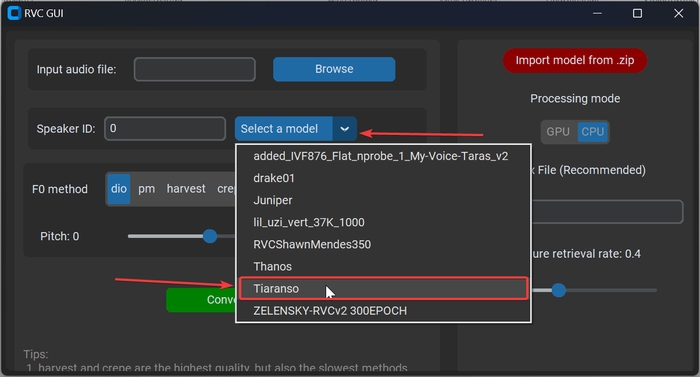
Тепер потрібно підготувати аудіо файл з записом голосу, який потрібно перетворити.
Як синтезувати голос робота?
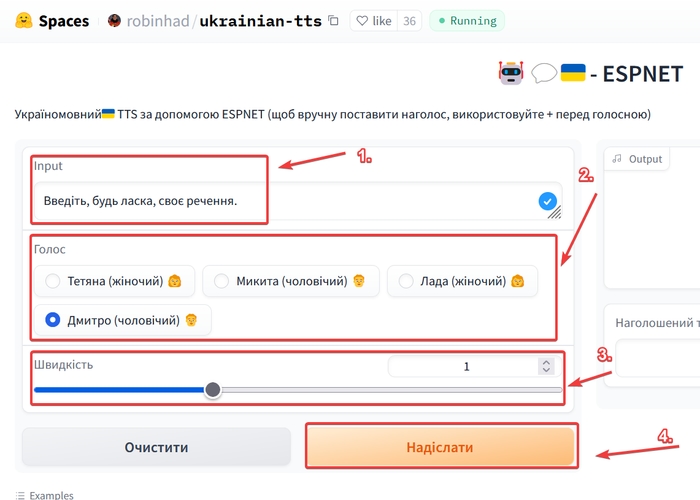
Взагалі можна знайти відносно багато синтезаторів мовлення, саме я буду використовувати Ukrainian TTS, голос Дмитро. В «Input» вводимо необхідний текст, вибираємо голос, швидкість і натискаємо на «Надіслати».
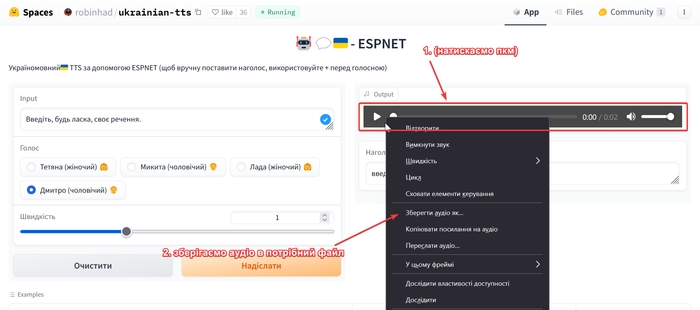
Отримане аудіо зберігаємо в потрібну теку.
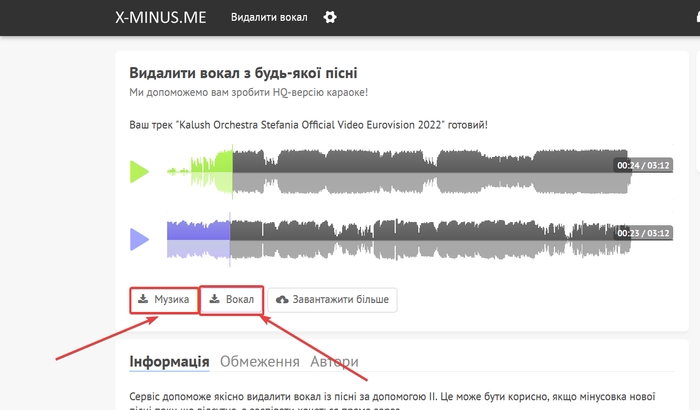
Як дістати вокал та мінусовку з пісні?
Ви можете замінити голос співака в якійсь пісні на свій. Для цього завантажте собі на комп’ютер її аудіо файл. Далі перейдіть за посиланням та загрузіть збережений запис треку.
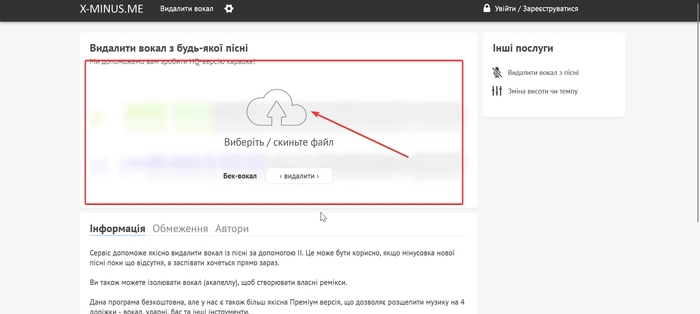
Дочекайтеся обробки та збережіть музику (мінусовка) та вокал собі на пристрій. Саме вокал потрібно буде передати програмі. Після перетворення ви можете об’єднати мінусовку та новий вокал з вашим голосом.
Перетворення голосу в програмі
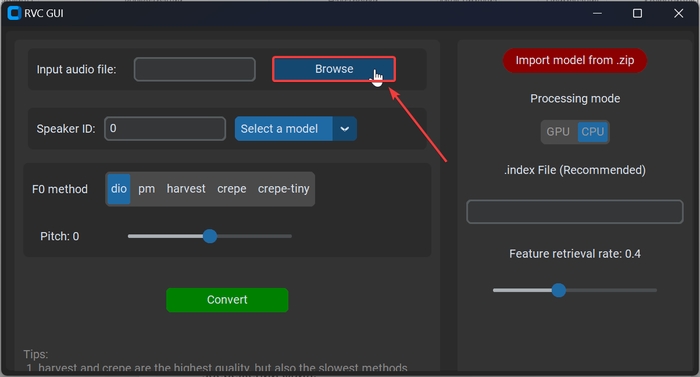
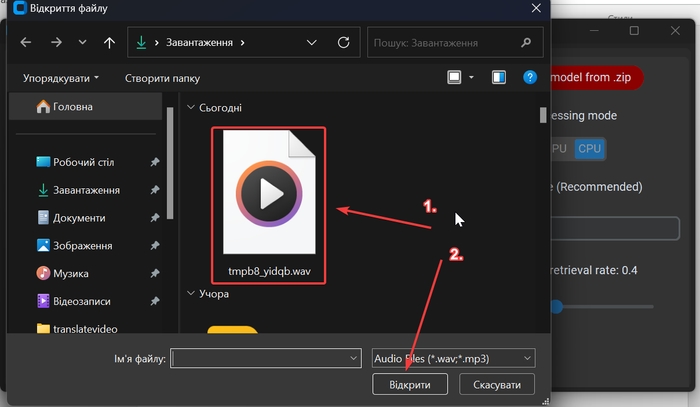
Повертаємося до програми. Натискаємо на «Browse» та вибираємо збережений аудіо файл з голосом.
Натискаємо кнопку Convert.
Чекаємо на текст «Success» та відкриваємо файл з перетвореним голосом.
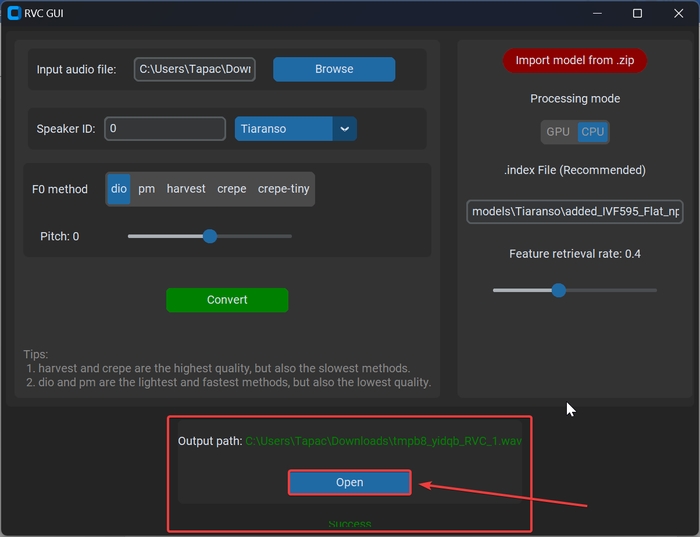
Готово! Біля кнопки «Open» показано шлях зберігання файлу та його назву. Можете використовувати перетворене аудіо у своїх цілях.
fin.
Другу частину довгочиту про RVC можна вважати завершеною. На цю тему я ще планую зробити відео на мій YouTube, яке підсумує дві статті. Також буде створено ЕКСКЛЮЗИВНИЙ КОНТЕНТ для підписників мого Донателло починаючи з підписки «Крутий жаб» за 180 гривень на місяць: відеоінструкція зі створення невеликого фільму використовуючи різні технології діпфейку.
Рекомендую підписатися на мій Telegram канал, де я ділюся всіма анонсами й купою цікавих і корисних публікацій.
На цьому все, дякую за увагу. Пишіть коментарі, хлопайте у долоні, підписуйтесь. До нових зустрічей! 😉
P.S: якщо у вас залишилися питання, діліться ними у коментарях, залюбки відповім на них.

