Передмова
Цей пост не є туторіалом. Це лише проблема, яка в мене виникла і я ділюсь думками як би я її вирішував, спираючись на свої знання та досвід.
Що взагалі сталось?
Після деплою, на одному з серверів при старті вилетів OutOfMemoryError.
Дослідивши хіпдамп/стектрейс, проблема була при витягуванні даних з бази:
@Component
@RequiredArgsConstructor
@Slf4j
public class SomeDataInMemoryCache {
private final MyDataRepository myDataRepository;
private final Map<UUID, MyData> myDataCache = new ConcurrentHashMap<>();
@PostConstruct
public void init() {
// ERROR here -> myDataRepository.getDataList(..);
List<MyData> dataList = myDataRepository.getDataList(..);
dataList.forEach(data -> myDataCache.put(someKey, data));
log.debug("Size of data list={}", dataList.size());
}
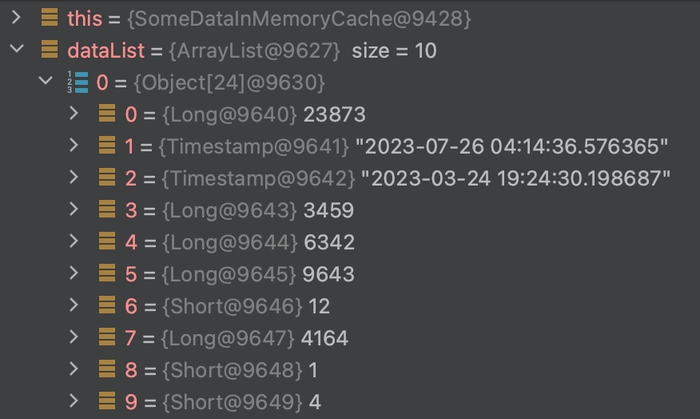
}Сутність, яку ми дістаємо, не є громіздкою, в неї немає зв’язків, і дані, витягуються не всі, а за певний проміжок часу. Ми їх кладемо в ін-меморі кеш на рівні джави, оскільки нам потрібний швидкий і багаторазовий доступ до даних (зараз немає змоги використовувати Redis або його аналоги).
Я розраховував к-ть сутностей і пам’ять, яку вони затратять, будучи в кеші при хайлоаді. Чого ми не змогли врахувати — це пікове навантаження на хіп при витягування даних, включаюючи оверхед, який дає Spring Data JPA. Про що я? →
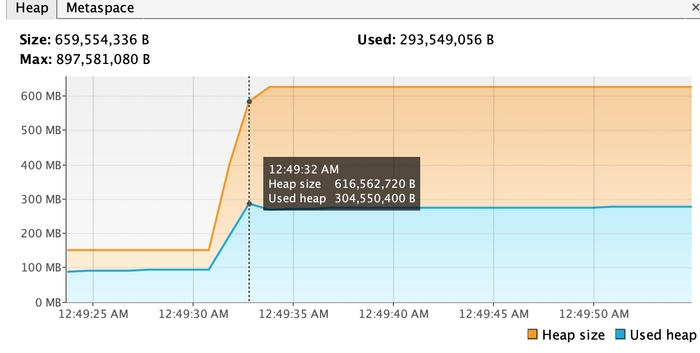
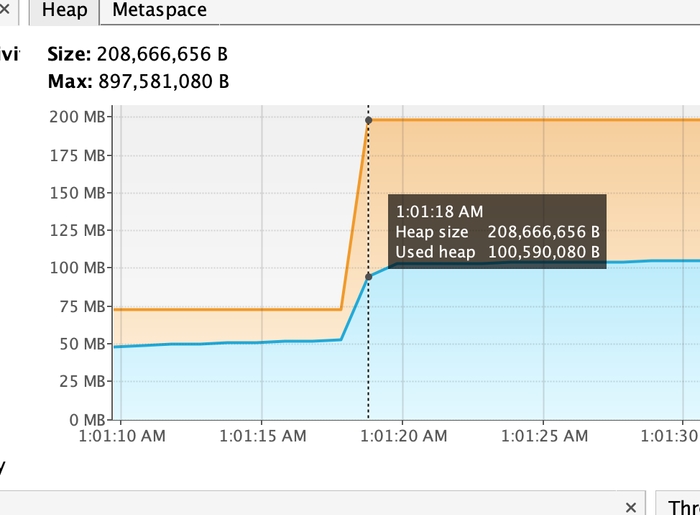
Щоб репродюснути проблему локально, я поставлю -Xmx850M, симулюючи обмежену к-ть пам’яті хіпа JVM (на проді стоїть інше кастомне значення, яке є не дуже великим в сучасних реаліях).
Запустимо код →
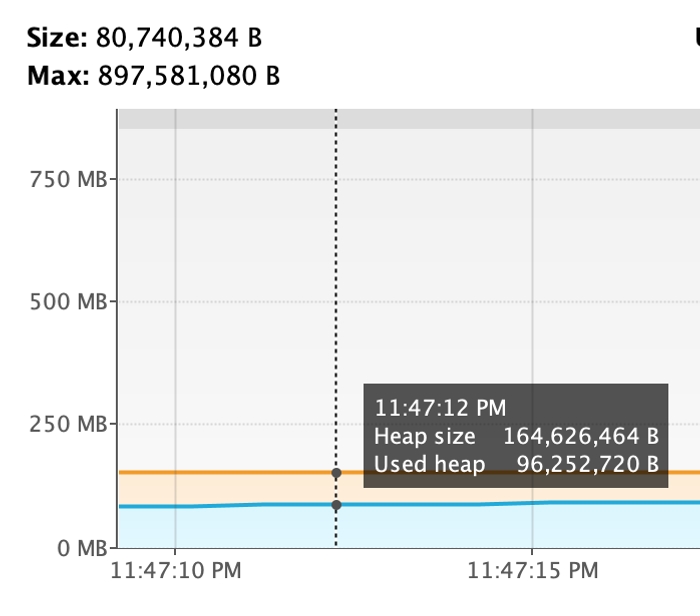
Caused by: java.lang.OutOfMemoryError: Java heap space
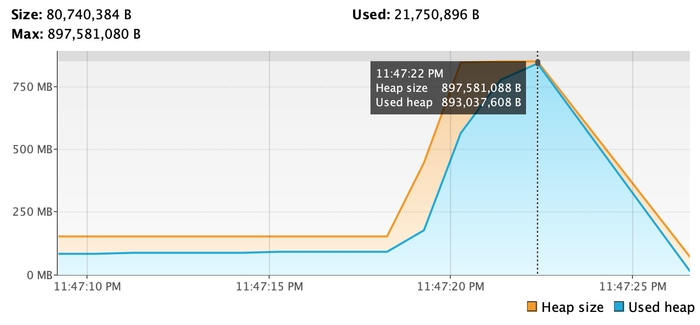
Давайте заради експерименту, спробуємо використати Hibernate, а не Spring Data JPA.
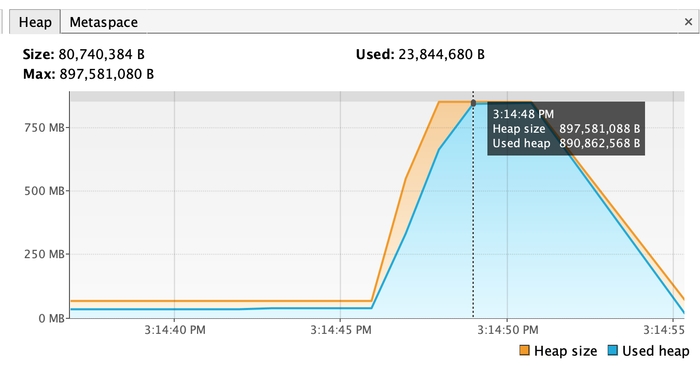
893 mb vs 284 mb
Давайте подивимось, які об’єкти повертають відповідні репозиторії.
JPA(Hibernate) repo:
@Component
@RequiredArgsConstructor
public class MyDataJpaRepo {
private final EntityManager entityManager;
public List<Object[]> getDataList() {
Query nativeQuery = entityManager.createNativeQuery(MyDataRepository.QUERY);
return nativeQuery.getResultList();
}
}
Тут все окей, повертається result set з нашими полями.
Розмір однієї сутності: 205 байт
Spring Data JPA Repo:
public interface MyDataRepository extends JpaRepository<SomeEntity, Long> {
// in real code there is no "*", we use projection to fetch specific fields and I filter by some parameters
String QUERY = "SELECT * FROM mydata limit 140000;";
@Query(value = QUERY, nativeQuery = true)
List<MyData> getDataList(/*parameters*/);
}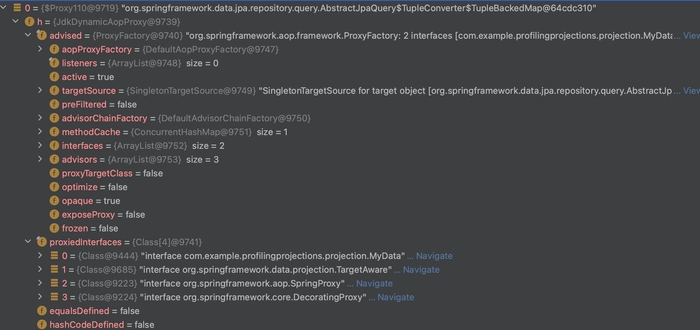
Розмір однієї сутності: 581 байт, через проксювання.
Що можна зробити? (1-3 варіанти ненайкращі)
1) Використати звичайний Hibernate, через відсутність оверхеду з боку спрінга
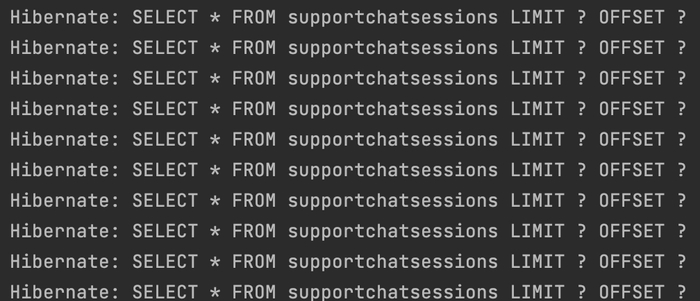
2) Оскільки ми боремось з піковим навантаженням, спричиненим витягуванням великого об’єму даних за раз, ми можемо розбити його на частини. Тобто виконати N запитів, замість одного.
Знизу приклад. Варто зауважити, що к-ть частин варто ретельно рахувати. Давайте просто спробуємо виконати 10 запитів, замість 1
public void callPartition() {
log.info("Calling spring data jpa projections partition");
int entitiesPerPartition = 14_000; // Number of entities per partition
int totalPartitions = 10; // Total number of partitions
for (int i = 0; i < totalPartitions; i++) {
int offset = i * entitiesPerPartition;
List<MyData> chatSessions = myDataRepository.getDataList(entitiesPerPartition, offset);
}
}
3) Поєднати 1 і 2 варіанти
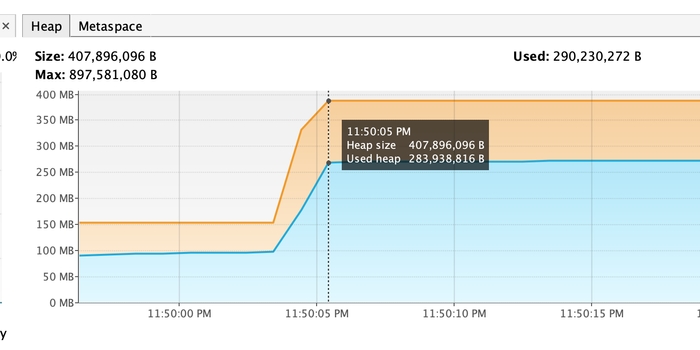
4) Використати Stream API в Spring Data JPA Repo
До:
-Xmx850M

Після:
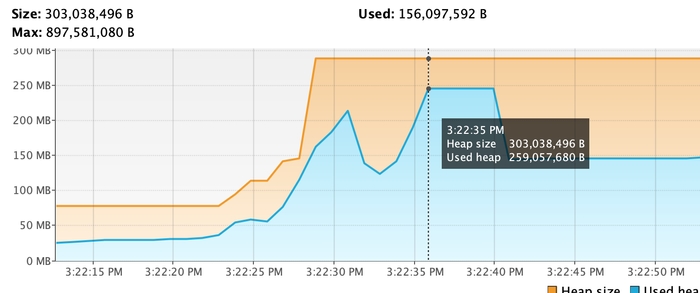
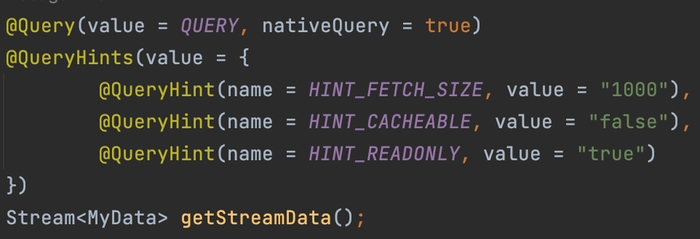

Використання стрімів дозволяє ефективно обробляти великі набори даних, не завантажуючи всі дані в пам'ять одночасно. Це покращує продуктивність і знижує споживання пам'яті порівняно з вибіркою всіх сутностей за один раз.
Під капотом там звичайний JDBC connection fetch size.
org/springframework/data/jpa/repository/query/JpaQueryExecution.java
static class StreamExecution extends JpaQueryExecution { .. }Якщо полізти всередину, то можемо побачити таке:
public ScrollableResultsImplementor<R> performScroll(ScrollMode scrollMode, DomainQueryExecutionContext executionContext) {
return executionContext.getSession().getJdbcServices().getJdbcSelectExecutor().scroll(jdbcSelect,scrollMode,jdbcParameterBindings,SqmJdbcExecutionContextAdapter.usingLockingAndPaging( executionContext ),null);
}default JdbcSelectExecutor getJdbcSelectExecutor() {
return JdbcSelectExecutorStandardImpl.INSTANCE;
}protected void bindParameters(PreparedStatement preparedStatement) throws SQLException {
final QueryOptions queryOptions = executionContext.getQueryOptions();
// set options
if ( queryOptions != null ) {
if ( queryOptions.getFetchSize() != null ) {
preparedStatement.setFetchSize( queryOptions.getFetchSize() );
}
if ( queryOptions.getTimeout() != null ) {
preparedStatement.setQueryTimeout( queryOptions.getTimeout() );
}
}preparedStatement.setFetchSize(queryOptions.getFetchSize()