Інтро
У світі сучасної розробки та використання програмних продуктів, ефективне управління логами стало надзвичайно важливим. Це дозволяє забезпечити високу доступність, швидку діагностику та вирішення проблем, а також оптимізацію продуктивності. Один із найбільш популярних інструментів для цієї мети – це ELK стек.
ELK
ELK стек (Elasticsearch, Logstash, Kibana) є потужним інструментом для збору, обробки та візуалізації логів. Інтеграція Spring Boot застосунку з ELK стеком дозволяє централізовано зберігати логи, здійснювати їхній аналіз та створювати інформативні дашборди для моніторингу. У цьому пості ми розглянемо, як налаштувати Docker Compose для ELK стеку та Spring Boot застосунку, а також як налаштувати конфігурації для інтеграції.
Компоненти ELK стеку
Elasticsearch - це розподілений пошуковий та аналітичний двигун/сервер, побудований на Apache Lucene. Він забезпечує швидкий повнотекстовий пошук та аналіз великих обсягів даних у режимі реального часу.
Основні характеристики:
Розподілена архітектура, що забезпечує високу доступність та масштабованість
Підтримка RESTful API для взаємодії
Гнучкість схеми, що дозволяє зберігати дані різної структури
Можливість агрегації та аналізу даних
Logstash - це інструмент для збору, обробки та передачі логів. Він може приймати дані з різних джерел, трансформувати їх та відправляти в Elasticsearch або інші сховища.
Ключові особливості:
Підтримка широкого спектру вхідних та вихідних форматів
Можливість фільтрації та трансформації даних на льоту
Плагінна архітектура для розширення функціональності
Буферизація даних для забезпечення надійності передачі
Kibana - це веб-інтерфейс для візуалізації та аналізу даних, що зберігаються в Elasticsearch.
Основні можливості:
Створення інтерактивних дашбордів
Потужні інструменти для візуалізації даних (графіки, діаграми, etc)
Можливість виконання складних запитів до даних
Налаштування оповіщень на основі заданих умов
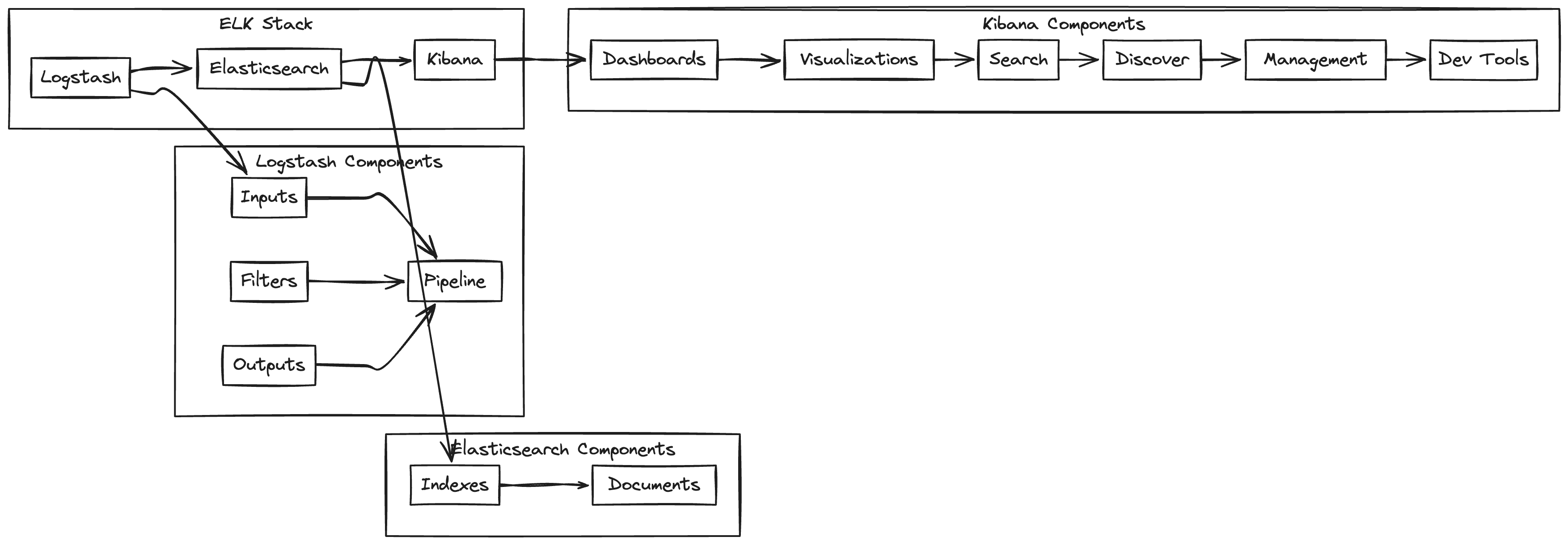
Як це працює разом
Збір даних. Logstash збирає логи та метрики з різних джерел (файли, бази даних, мережеві потоки).
Обробка. Logstash фільтрує та трансформує дані відповідно до заданих правил.
Індексація. Оброблені дані відправляються в Elasticsearch для індексації та зберігання.
Аналіз та візуалізація. Kibana дозволяє користувачам створювати запити до Elasticsearch та візуалізувати результати.
→
Розглянемо найпростіший спосіб інтеграції з ELK. Ми логи будемо писати у файл, читати з файлу і відправляти їх просто як рядки, не як json. По цьому можна зробити окремий пост.
Налаштування Docker Compose для ELK
Спочатку, подивимось на ієрархію директорій. Це важливо.
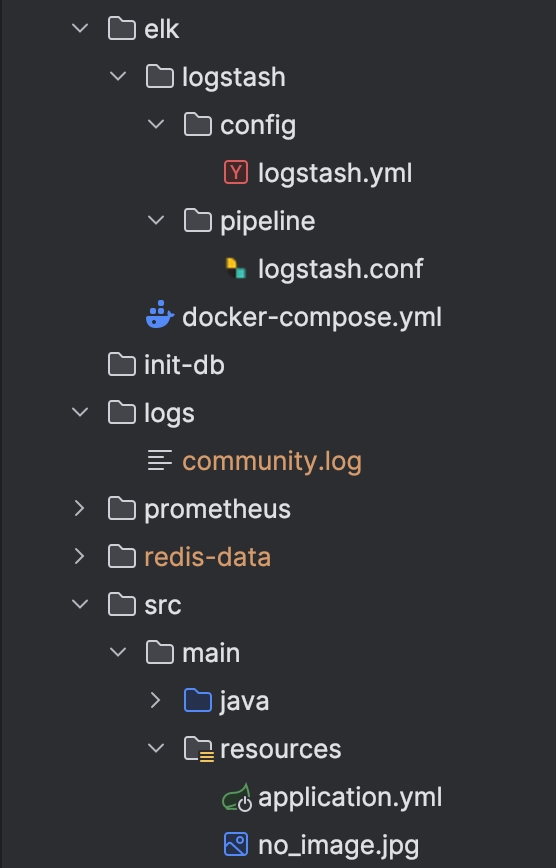
elk/logstash/config/logstash.yml
Файл logstash.yml використовується для загальної конфігурації Logstash. Він визначає основні параметри роботи сервісу Logstash, такі як налаштування мережі, шляхи до конфігураційних файлів, etc.
http.host: "0.0.0.0" # Вказує Logstash приймати HTTP-запити з будь-якої IP-адреси
log.level: debug # Рівень логування для виведення докладної інформації для відладки
node.name: logstash # Ім'я вузла Logstash в кластері
path.config: /usr/share/logstash/pipeline/logstash.conf # Шлях до конфігураційного файлу Logstash (logstash.conf)
path.logs: /usr/share/logstash/logs # Шлях до директорії для зберігання логів Logstash
elk/logstash/config/logstash.conf
Файл logstash.conf використовується для конфігурації Logstash, Цей файл містить три основні секції: input, filter та output, кожна з яких виконує специфічну роль у процесі обробки даних.
input - Ця секція визначає джерела даних, які Logstash буде збирати та обробляти. Вона вказує, звідки Logstash має отримувати логи або інші дані.
filter - Ця секція визначає, як обробляти, трансформувати або фільтрувати дані, які були отримані з джерел. Вона дозволяє виконувати різні операції, такі як парсинг, перетворення даних та видалення непотрібної інформації.
output - Ця секція визначає, куди будуть відправлені оброблені дані. Це може бути Elasticsearch, інші бази даних, файли або інші системи.
input {
file {
path => "/usr/share/logstash/logs/*.log"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "service-%{+YYYY.MM.dd}"
}
}
elk/docker-compose.yml
version: '3.8'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.13
ports:
- "9200:9200" # Порт для доступу до Elasticsearch
- "9300:9300" # (-)
networks:
- elk-network
environment:
- discovery.type=single-node # Налаштування для одновузлового кластера
- xpack.security.enabled=false # Вимкнення безпеки X-Pack для спрощення налаштування
logstash:
image: docker.elastic.co/logstash/logstash:7.17.13
ports:
- "50000:50000" # Порт для отримання даних Logstash
volumes:
- ./logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml # Налаштування Logstash
- ./logstash/pipeline:/usr/share/logstash/pipeline # Конфігурації Logstash
- ../logs:/usr/share/logstash/logs # Логи, які обробляються Logstash
command: [ "-f", "/usr/share/logstash/pipeline/logstash.conf"] # Команда для запуску з конкретним конфігом
depends_on:
- elasticsearch # Запуск Logstash після Elasticsearch
networks:
- elk-network # Мережа для взаємодії з іншими сервісами ELK стеку
kibana:
image: docker.elastic.co/kibana/kibana:7.17.13
ports:
- "5601:5601" # Порт для доступу до Kibana
depends_on:
- logstash # Запуск Kibana після Logstash
networks:
- elk-network
volumes:
esdata:
driver: local # Локальний драйвер для зберігання даних Elasticsearch
networks:
elk-network:
driver: bridge # Тип мережі для взаємодії всіх сервісів ELK стеку
Зверніть увагу на volumes(томи) у logstash. Ви маєте правильно замаунтити локальну директорію з логами.
Контейнери взаємодіють через спільну мережу та томи. Застосунок записує логи у спільний том, доступний також контейнеру Logstash. Logstash зчитує ці логи з тому, обробляє їх і відправляє до Elasticsearch через спільну мережу. Elasticsearch індексує отримані дані, а Kibana використовує ці дані для створення візуалізацій і дашбордів для аналізу. Томи забезпечують спільний доступ до даних між контейнерами, а мережа дозволяє контейнерам обмінюватися даними та взаємодіяти один з одним.Налаштування застосунку для роботи з ELK
application.yml (application level)
...
logging:
level:
root: info
file:
name: logs/community.logdocker-compose.yml (application level)
version: '1'
services:
app:
image: overpathz/communitybot
build: .
container_name: community-app
ports:
- "8080:8080"
depends_on:
- redis
- rabbitmq
- db
environment:
.. env vars
volumes:
- ./logs:/app/logs
.. other containers- ./logs:/app/logsБудучи в директорії elk →
docker-compose -f docker-compose.yml build && docker-compose -f docker-compose.yml up -dМаємо побачити ось це
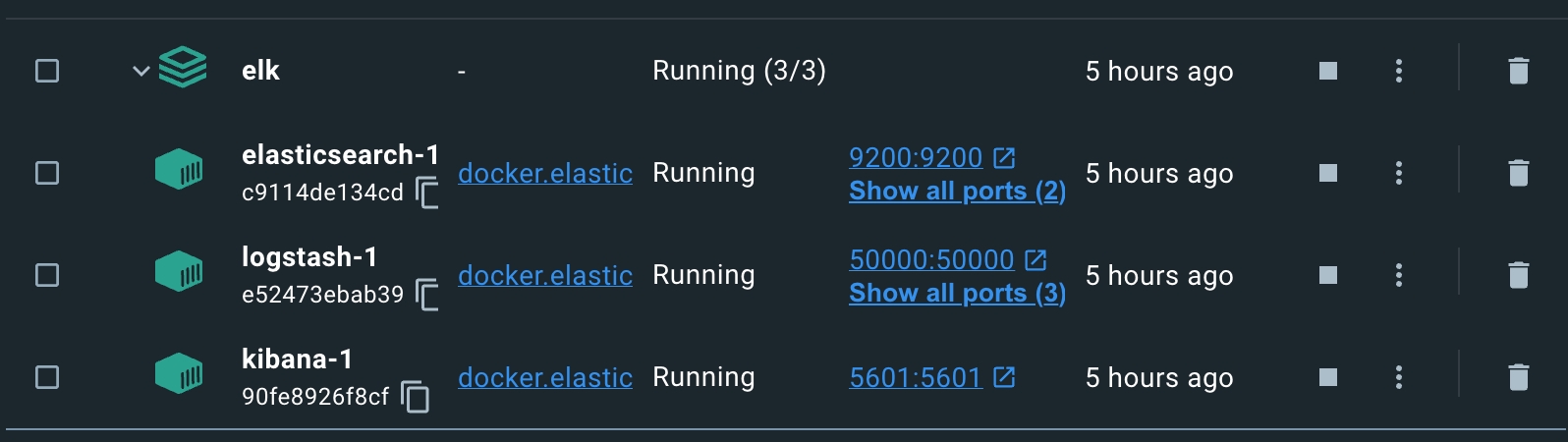
Запускаємо і дивимось логи
Щоб переконатися, що Kibana працює, переходимо за адресою:
http://localhost:5601/app/home
Чекаємо ще трішки, оновлюємо сторінку і потрапляємо сюди
Окей. ELK піднятий. Далі, билдаємо і ранимо наш застосунок. Та сама команда, але тепер в руті нашого проекту.
docker-compose -f docker-compose.yml build && docker-compose -f docker-compose.yml up -d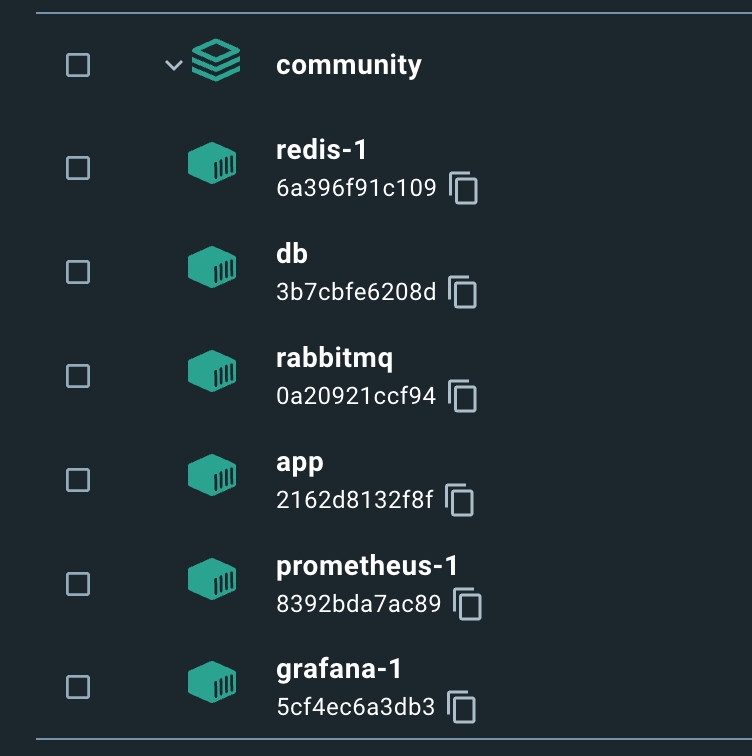
У вас може не бути стільки контейнерів, нас цікавить наш основний (якщо це не мікросервіс), в мене це app.
Заходимо всередину → Files → Маємо впевнитися, що наш лог файл справді існує і він не пустий (тобто, що в нього дійсно пишуться логи)
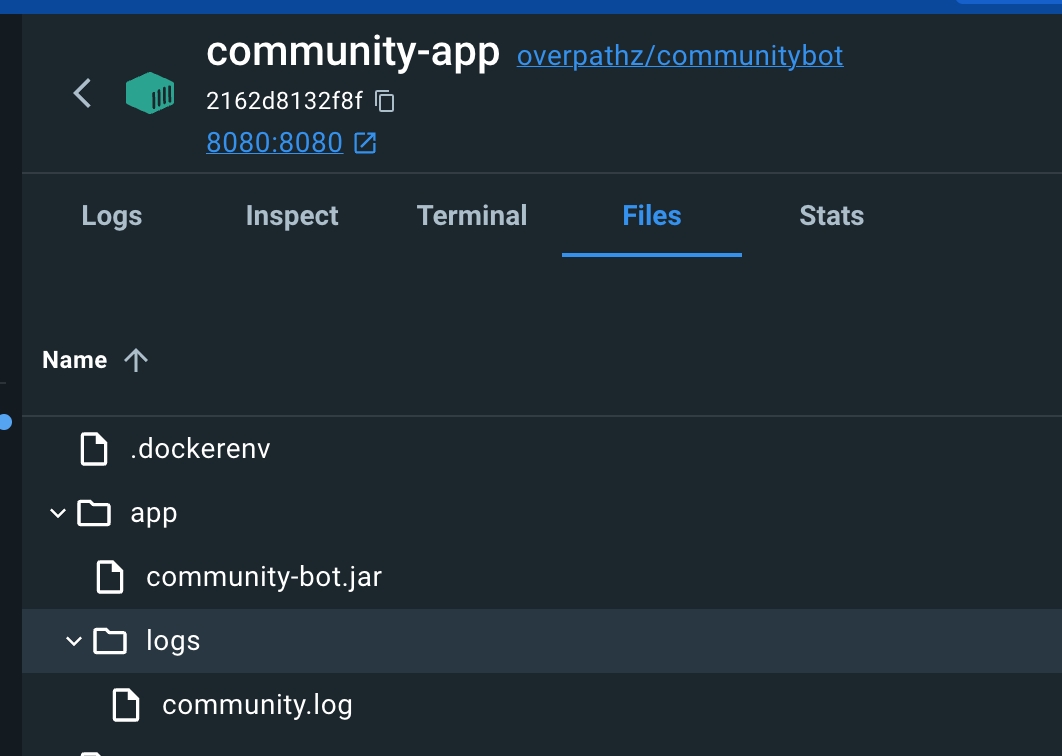
Заходимо в кібану.
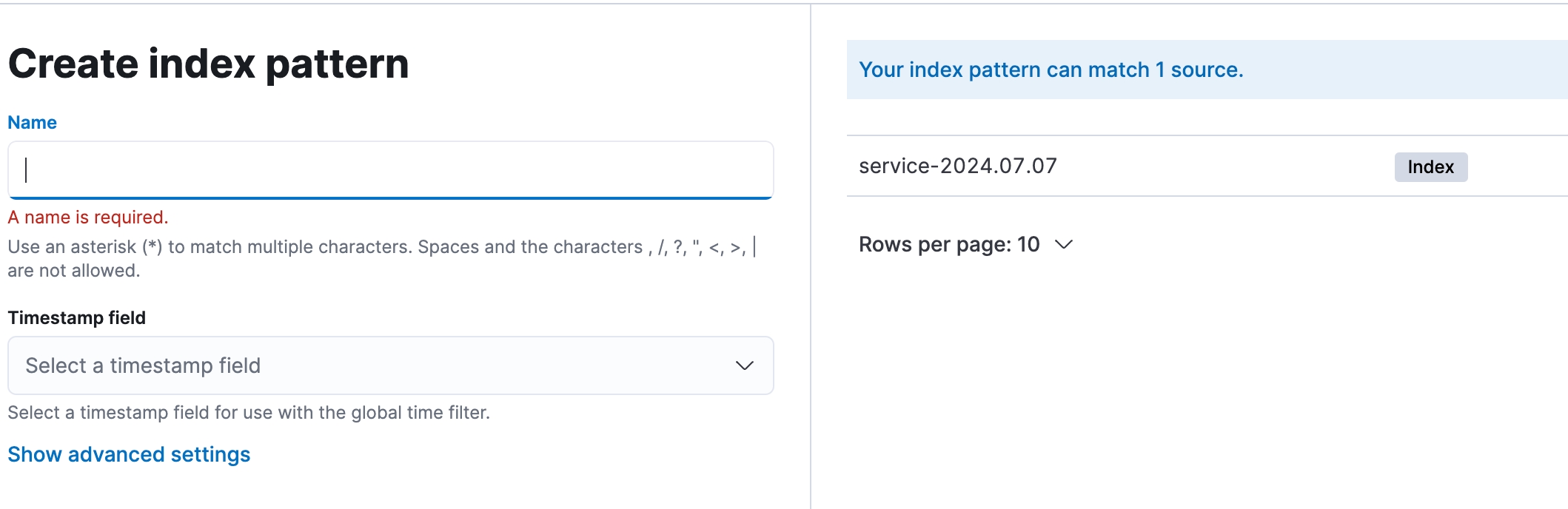
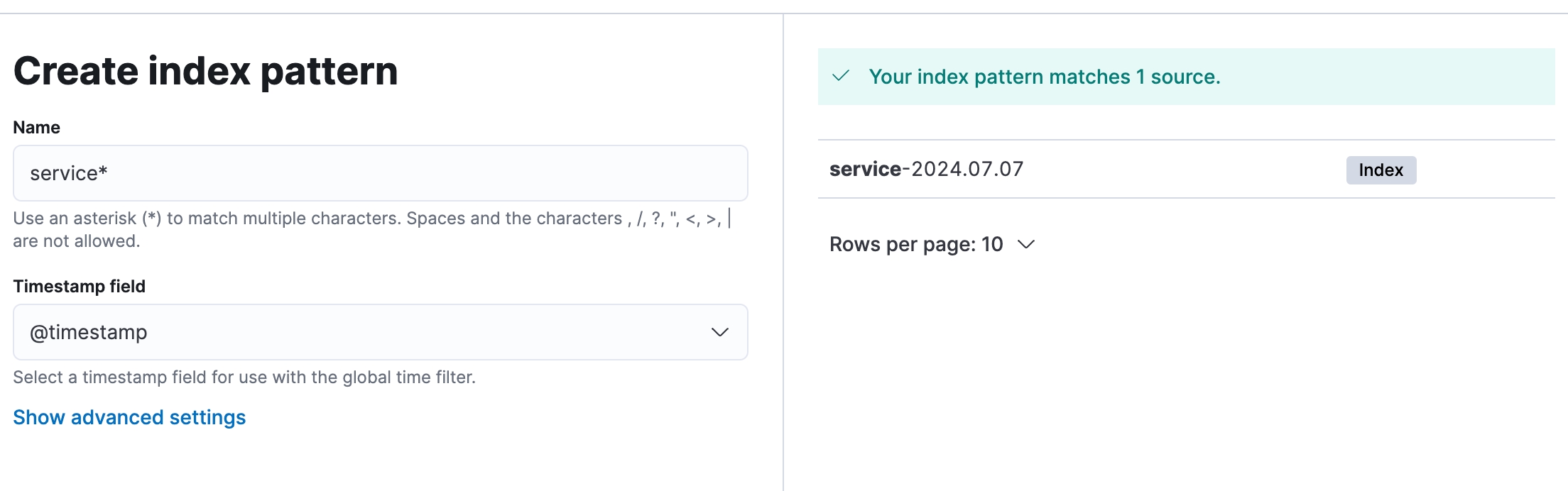
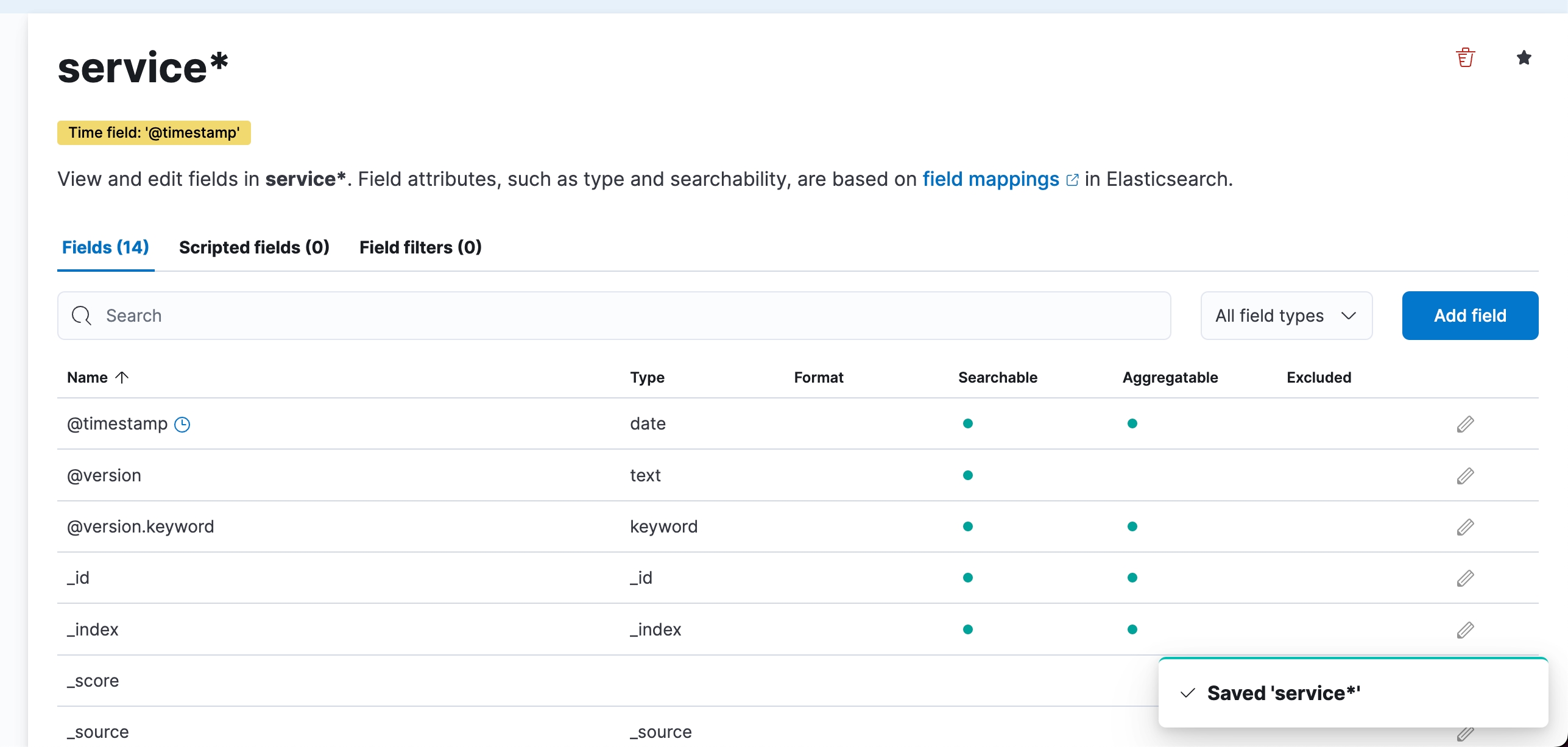
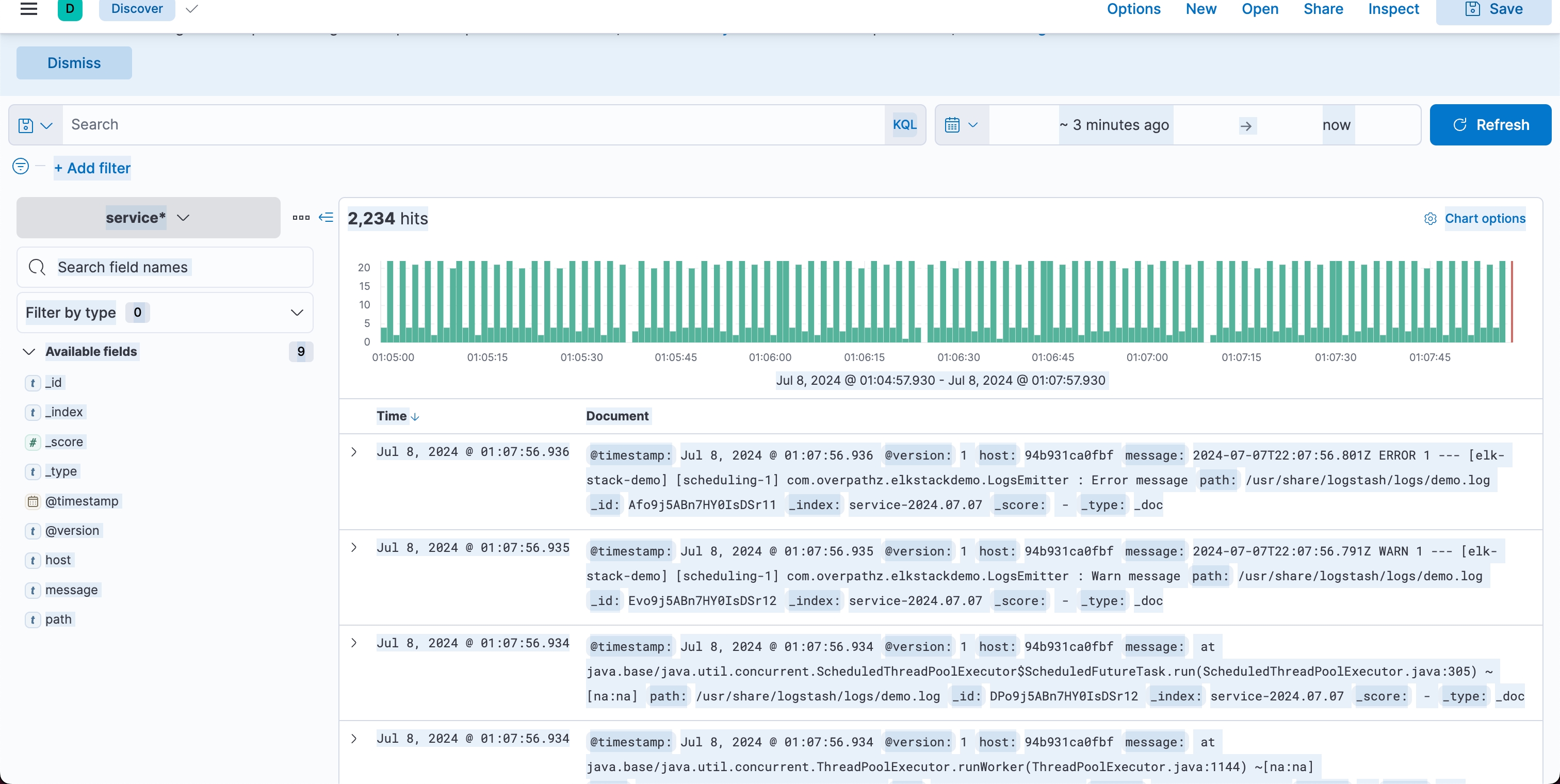
Index Pattern (шаблон індексу) в Kibana визначає набір індексів в Elasticsearch для пошуку та візуалізації даних. Наприклад, шаблон service-* включатиме всі індекси, що починаються з service-, як-от service-2023.07.07.
Logstash відправляє* оброблені логи до Elasticsearch, де вони зберігаються в індексах з іменами у форматі service-YYYY.MM.dd. Щоб Kibana могла отримати доступ до цих індексів, потрібно створити відповідний Index Pattern. Таким чином, Logstash обробляє і відправляє дані до Elasticsearch, де вони індексуються і стають доступними для пошуку і візуалізації в Kibana через Index Pattern.
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["elasticsearch:9200"]
index => "service-%{+YYYY.MM.dd}"
}
}Тепер, після додавання індекс патерну, заходимо сюди:

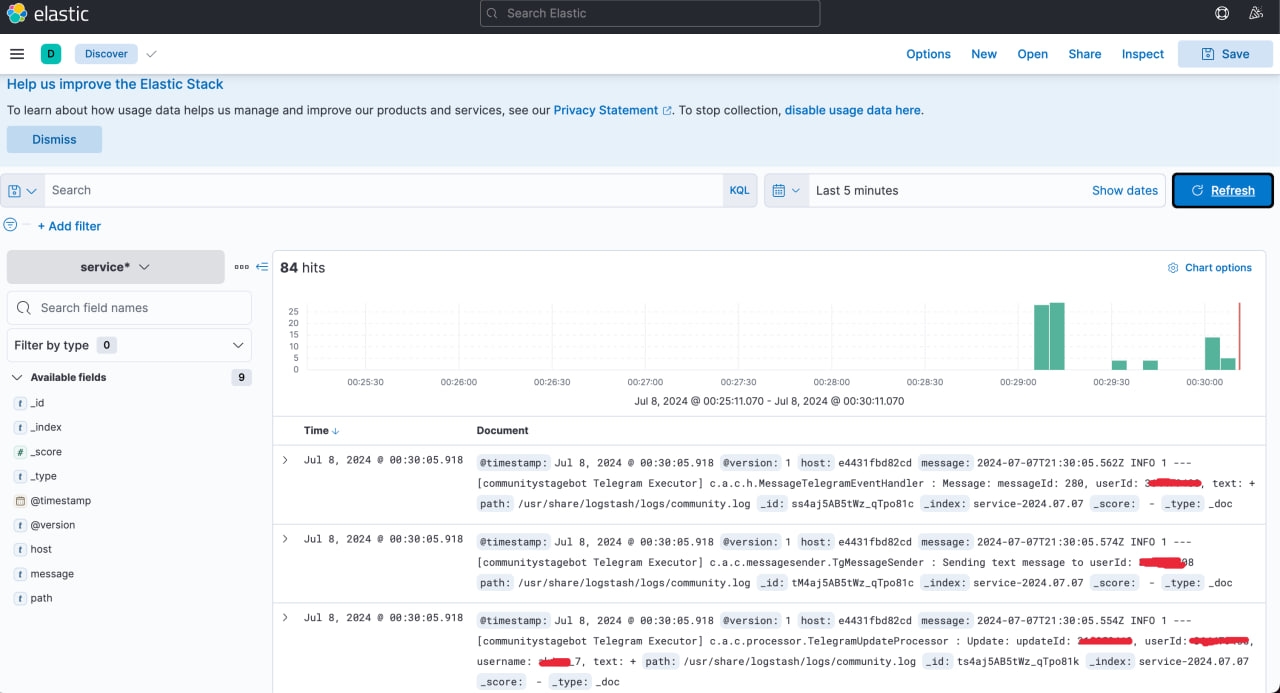
Вуаля. Логи в кібані.
https://github.com/overpathz/elk-stack-java
Демо-версія проекту, де за тими ж інструкціями ви зможете запустити ELK стек та застосунок та подивитися на логи (які будуть автоматично згенеровані за вас).
Можливо, з’явиться довгочит про налаштування графани і прометеуса.
Але не від мене.
Yaroslav? :)
