Я розпочинаю серію статей, присвячених задачі класифікації. Формат “101” взятий з американської навчальної програми, де таким номером позначають вхідні курси, курси рівня junior. Для прикладу буду використовувати свій проект з кеглевського змагання, який увійшов у перші 45%.
Розділювальна площина (гіперплощина)
Виходячи з назви, основна ціль задачі класифікації - віднести конкретні дані до конкретного класу, але як саме це можна зробити, і чому навіть найскладніші нейронні мережі не мають 99% точності?
Уявіть, що вам треба відсортувати 10 книг різних жанрах по 5 жанрах. Скоріше за все, ви прочитаєте короткий опис кожної книги, візуально оціните обкладинку, можливо, прочитаєте про автора. Опис, обкладинка та автор - це ознаки, за яким буде проводитися сортування.
Задача класифікації в машинному навчанні має схожу, але більш математичну реалізацію. Основна мета якої - побудувати розділювальну площину з мінімальним значенням функції помилки. Все ще звучить доволі просто, еге ж? Але давайте подивимося на те, що таке навчальні дані насправді.
Для навчання нейромережі потрібно мати датасет, який складається з n-кількості ознак. Разом ознаки (features) формують простір ознак, кількість вимірів якого і є головним викликом, кількість вимірів = кількості ознак. Розглянемо на прикладі: маємо датасет з 2 ознак: гендер 1 та гендер 2, задача - класифікувати дані по класам. Даний датасет є двовимірним, оскільки має 2 ознаки.
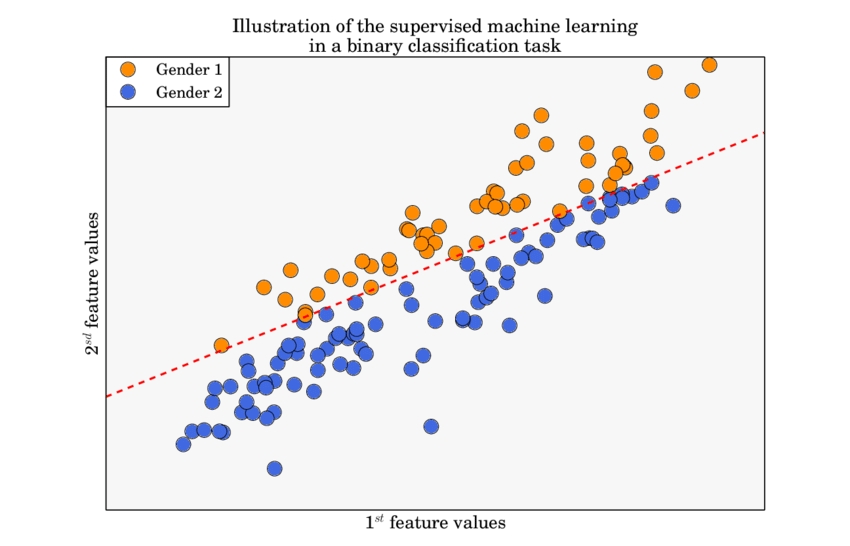
Наведена задача є задачею бінарної класифікації, про неї - далі. Розділювальна функція (червона пунктирна лінія), по якій алгоритм буде класифікувати, є лінійною, тобто, щоб вирішити дану задачу можна використати найпростіший алгоритм - логістичну регресію. На перший погляд, все просто, але датасети для реальних задач можуть мати 50, 100, 500 вимірів.
Велика розмірність - великі проблеми
Дві основні проблеми в даних, через які алгоритм або нейромережа мають низьку точність - це кількість вимірів та форма.
Почну з першої проблеми - багатовимірність. Уявіть, що ви заблукали в печері, який шанс вийти з печери, маючи 2 або 200 ходів? Багатовимірність призводить до довшого часу навчання, перенавчання моделі, та прокляття багатовимірності (феномен Хьюза):
Чим більше розмірності матриць, тим більше ресурсів потрібно на операції з ними
Модель не можу узагальнювати (generalization)
У багаторозмірних площинах неймовірно складно знайти відстань від однієї точки даних до іншої, у випадку класифікації це феномен Хьюза: чим більше вимірів, тим легше знайти розділювальну поверхню під час тренування, але в той же час, тим важче моделі зробити узагальнення (generalization).
Задля оптимізації та візуалізації використовують методи Зменшення розмірності (Dimensionality reduction), такі як PCA, MDS та інші. Основний принцип їх роботи - перенести кожний екземпляр, кожну точку даних, у простір меншої розмірності, зазвичай 2- 3 вимірних.
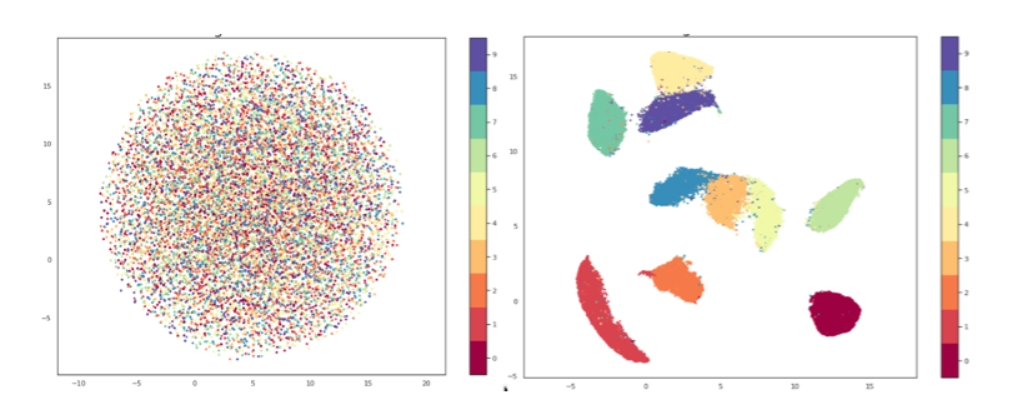
Методи Зменшення розмірності є дуже важливою частиною feature engineering, їм буде присвячений окремий довгочит.
Друга проблема - це форма даних, в залежності від неї інженер обирає метод Зменшення розмірності: лінійний або нелінійний. Для розділення даних у багатовимірних просторах потрібно побудувати розділювальну площину. Чи може ця площина бути нелінійною, наприклад, розділити дані на малюнку зліва? Теоретично - так, але це вже виходить за рамки поняття розділювальної площини та не використовується у машинному навчанні.
На прикладі дані 2-х вимірні дані зліва переводять у 3-х вимірний простір, у якому можна побудувати розділювальну площину.
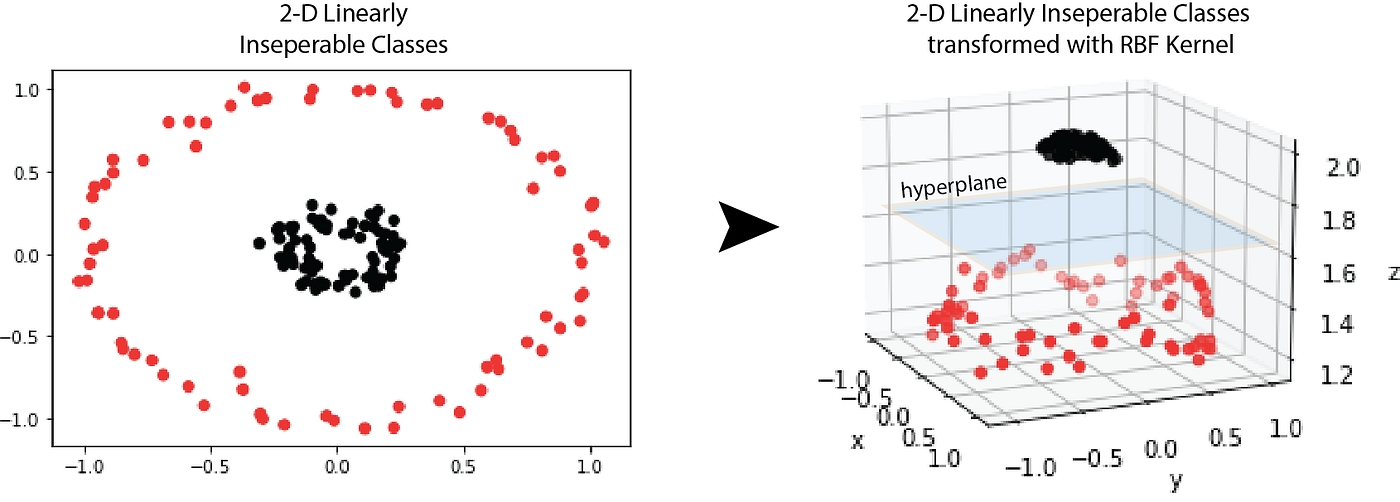
Варто зазначити, що алгоритми Зниження розмірності є частиною feature engineering, тобто, якщо ви маєте непотрібні ознаки, які можна видалити або застосувати feature cross, то це потрібно зробити.
Model - driven vs data - driven approach
Існує два підходи до побудови моделі: приділити більше часу обробці та перетворення даних або зробити мінімальну обробку даних, натомість зосередити всі сили на розробці потужної та оптимізованої моделі. Кожний підхід має свої переваги та недоліки, в залежності від поставленої задачі. Особисто я прихильниця data - driven і ось чому:
Брак потужностей: щоб побудувати складну та точну модель, яка може опрацьовувати великовимірні датасети, потрібна величезна кількість даних, більший час навчання, складніший тюнінг та оптимізація, навіть якщо використовувати квантизацію та інші ефективні методи.
Проблема узагальнення: навіть найкращі моделі, наприклад, той же ChatGPT мають bias на окремі теми - упередженість щодо національності, раси, тощо.
Створити високоточну модель для необроблених в більшості випадків набагато складніше та ресурсоємно, ніж обробити дані.
Ентропія
Ентропія випадкової величини X - це рівень невизначеності, притаманний можливому результату змінної.
Звучить абстрактно, але зараз стане зрозуміліше. Спершу, розглянемо приклад: визначимо ймовірність діставання фігур різного типу з контейнера.
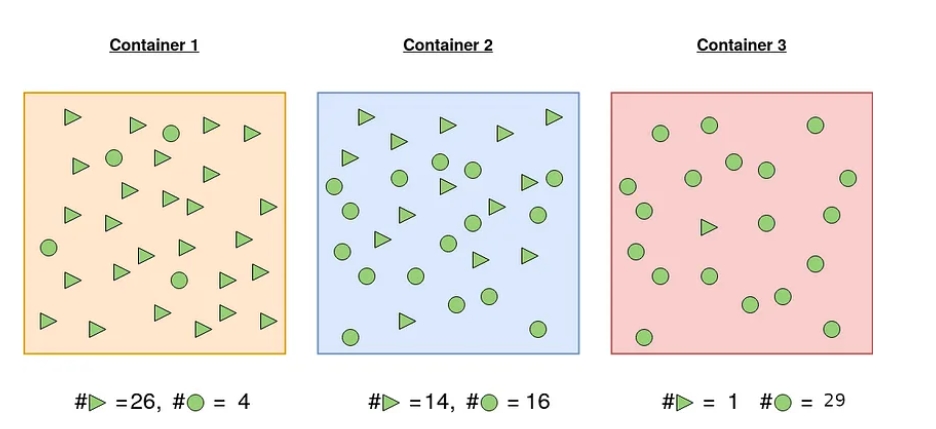
Контейнер 1: Ймовірність витягнути трикутник становить 26/30, а ймовірність витягнути коло - 4/30.
Контейнер 2: Ймовірність витягнути трикутник становить 14/30 і 16/30 у випадку кола. Ймовірність вибору певної форми майже 50 на 50. Впевненість у виборі фігури менша, ніж у випадку 1.
Контейнер 3: Ймовірність витягнути коло становить 29/30, а ймовірність витягнути трикутник - 1/30. З високою ймовірністю можна стверджувати, що вибрана фігура буде колом.
В якому з цих трьох випадках можна бути максимально впевненим у передбаченні того, яку фігуру витягнете? Інтуїтивно у випадку 3, що і підтверджує ентропія.

Простими словами ентропія - це показник передбачуваності. Чим менший показник ентропії, тим впевненіше можна бути.
Ентропія як функція втрат
Ця частина присвячена класифікації за допомогою тільки нейромереж, методи машинного навчання, що використовуються для класифікації, працюють за іншими принципами.
Важливо пам’ятати різницю між функцією втрат та оптимізатором. Функція втрат оцінює різницю між класом (лейблом) та передбаченим нейромережею значенням, тоді як оптимізатор змінює ваги (матриця W) під час Backpropagation для знаходження мінімума функції втрат. Всі активаційні функції для класифікації повертають вірогідність конкретного класу.
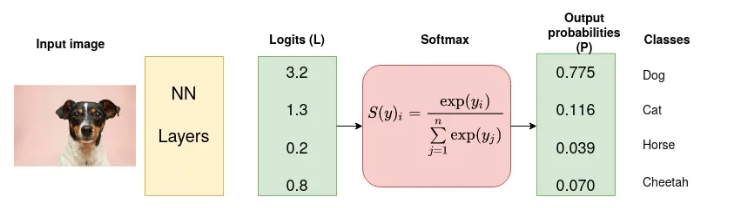
Але як можна оцінити точність передбачення нейромережі, якщо це вірогідність? Чи можна просто відняти вірогідність від лейблу? Перш за все, якщо просто віднімати, вірогідність стає звичайним числом, що нічого не оцінює. Якщо ж оцінювати передбачену вірогідність за формулою ентропії, отримаємо показник "впевненості в передбаченні''. Для більшого розуміння розрахуємо ентропію для цієї передбаченої ймовірності та справжнього класу:
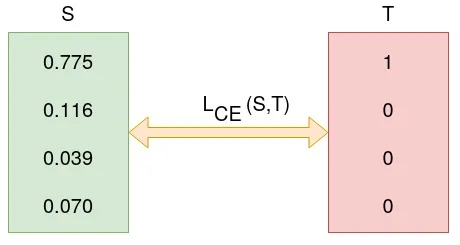

Ентропія у 0.3677 є показником того, що нейромережа не дуже "впевнена'' у власному передбаченні. Перевіримо вірогідність для наступної епохи:
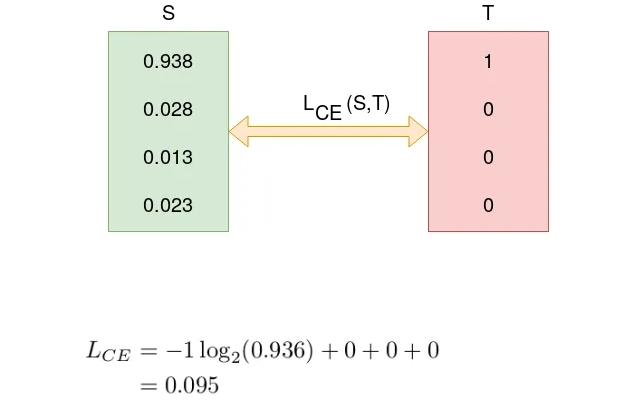
Значення ентропії знизилося (вірогідність правильного класу, першого, стала вищою) - нейромережа навчається.
Categorical Cross-Entropy vs Sparse Categorical Cross-Entropy
В залежності від вигляду, в якому подаються класи (лейбли) до нейромережі базується вибір функції ентропії. Що категоріальна, що спарс ентропія використовують однакову формулу ентропії.
Categorical Cross-Entropy: якщо лейбли у вигляді one - hot вектора, тобто справжній клас позначений 1, всі інші класи позначені як 0. Наприклад, ваш датасет складається з 3 класів: собаки, коти, папуги. Фотографія, де є собака, буде мати вектор [клас собака, клас кіт, клас папуга] = [1,0,0].
Sparse Categorical Cross-Entropy: якщо лейбли - це номер класу, 1,2,3…, тощо.
На практиці рекомендується все ж використовувати лейбли у вигляді one - hot вектора, бо між векторами немає зв’язку. Наприклад, якщо ваші лейбли нумерувалися у довільному порядку, клас “1“ - це хліб, клас “2“ - собака, нейромережа може ''подумати'', що між собакою та хлібом є зв’язок.
Ансамблювання
Пам’ятаєте шкільну гру “Що? Де? Коли?”? Моя команда часто їздила на змагання, і саме там я зрозуміла цінність командної роботи. Ансамблювання працює за схожим принципом - об’єднуючі результати кількох моделей, можна підняти якість передбачення, знизити variance, bias, підняти рівень генералізації (узагальнення) навіть на даних з шумом.
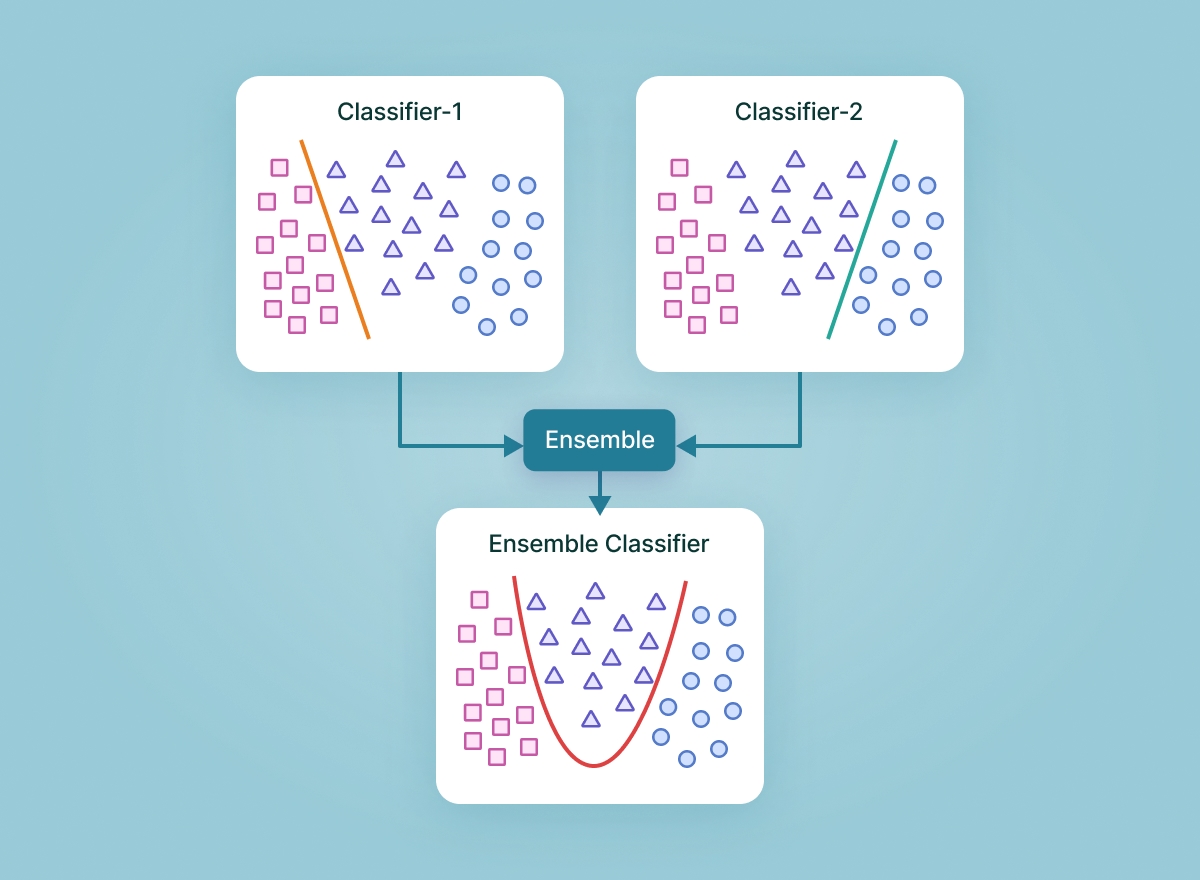
Як обрати моделі для ансамблювання?
Є два підходи: Гомогенний - ансамблювання моделей однакового типу, та гетерогенний - ансамблювання моделей різного типу.
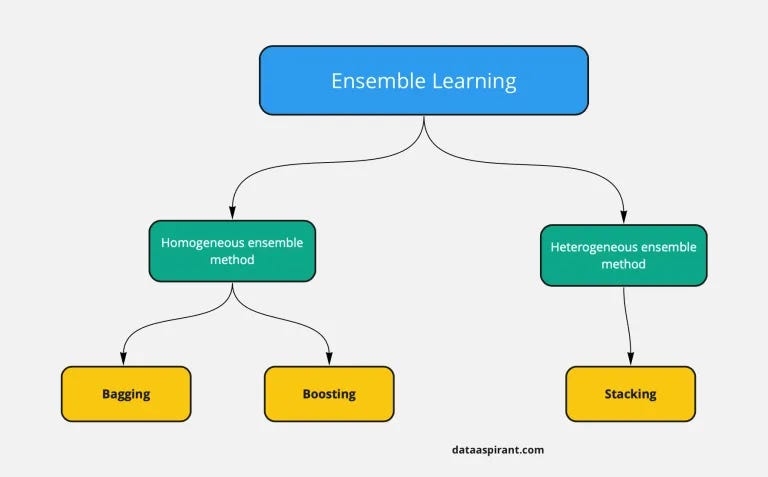
Гомогенне ансамблювання реалізовано в двух алгоритмах: Bagging та Boosting
Bagging
Гомогенне ансамблювання, зменшує variance.
Навчання: Паралельне навчання
Приклад: Random Forest
Цей метод передбачає навчання декількох екземплярів моделі на різних підмножинах навчальних даних, створених за допомогою bootstrapping (випадкової вибірки із заміною).
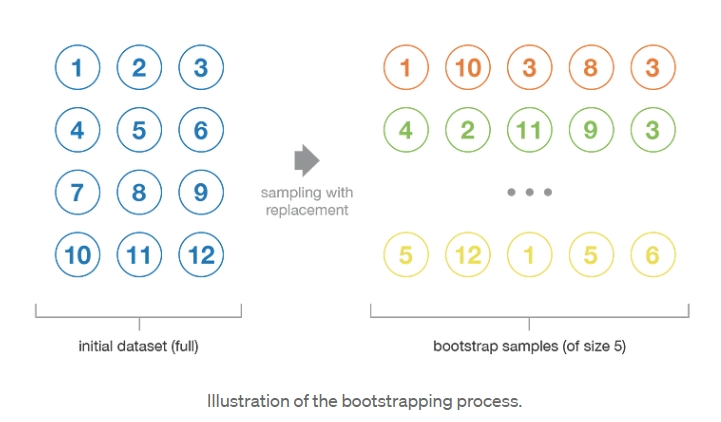
Bootstrapping дозволяє тренувати модель на незалежних підмножинах (samples) датасету, не знаючи реального розподілу даних, тим самим підвищуючи узагальнення. Bootstrap-вибірки часто використовуються для оцінки дисперсії або довірчих інтервалів статистичних оцінок, оскільки кожна вибірка є незалежною.
Умовно можна розділити на дві частини: Bootstrapping та Aggregating (те, що по суті і є ансамблювання)
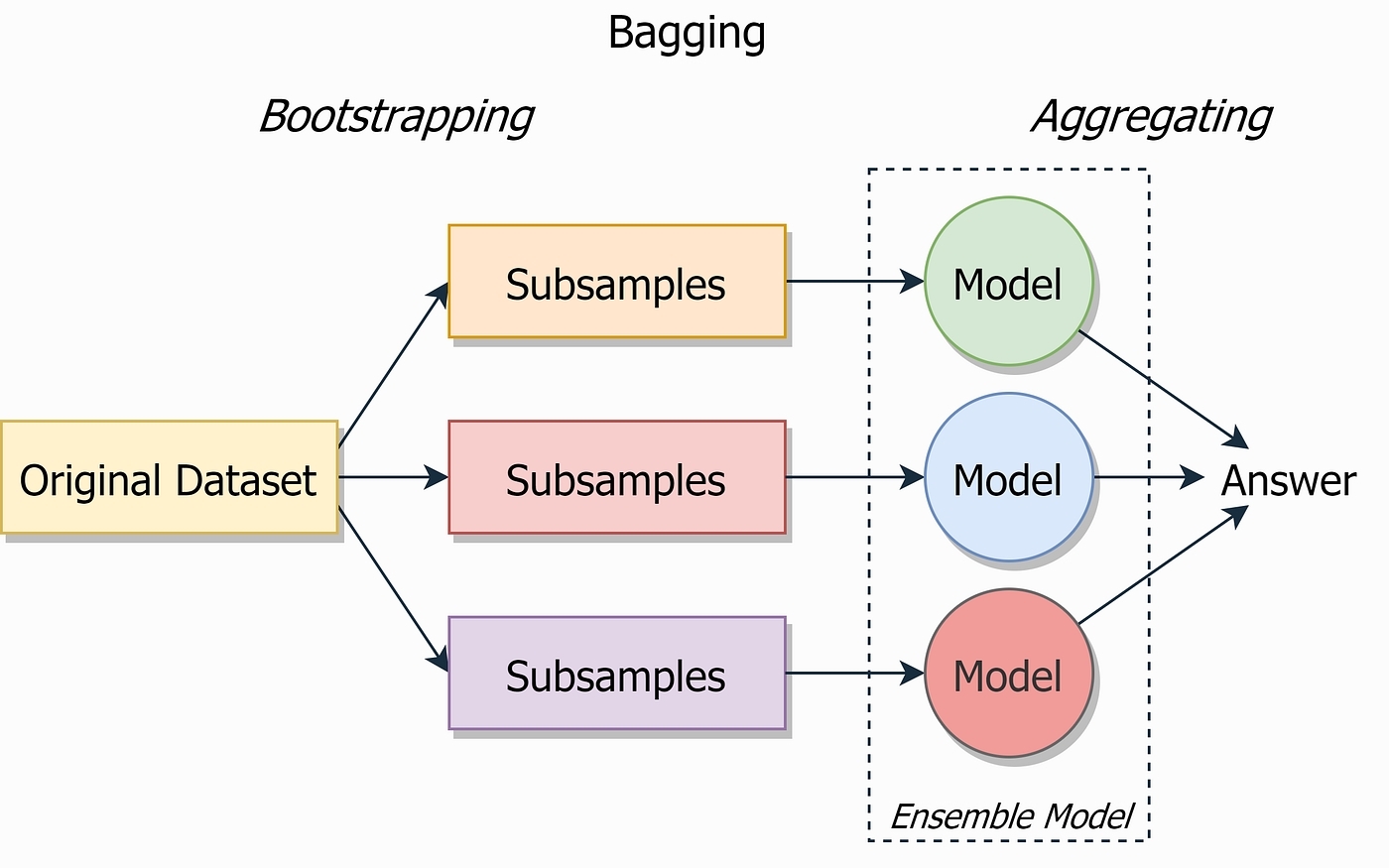
Є два види фінальної функції (частина Aggregating), яка зводить результат передбачення всіх моделей: для задачі регресії - це середнє зважене, для класифікації - голосування (voting), hard - voting, коли передбачений клас - це той клас, який спрогнозували (передбачили) більшість моделей, soft - voting, спрогнозованим класом є клас з найбільшої середньої ймовірністю.
Boosting
Гомогенне ансамблювання, зменшує bias
Навчання: Послідовне навчання.
Приклад: XGBoost, LightGBM
Моделі навчаються послідовно, при цьому кожна нова модель фокусується на помилках попередніх. Ідея полягає в ітеративному підборі моделей таким чином, щоб навчання моделі на даному кроці залежало від моделей, підібраних на попередніх кроках.
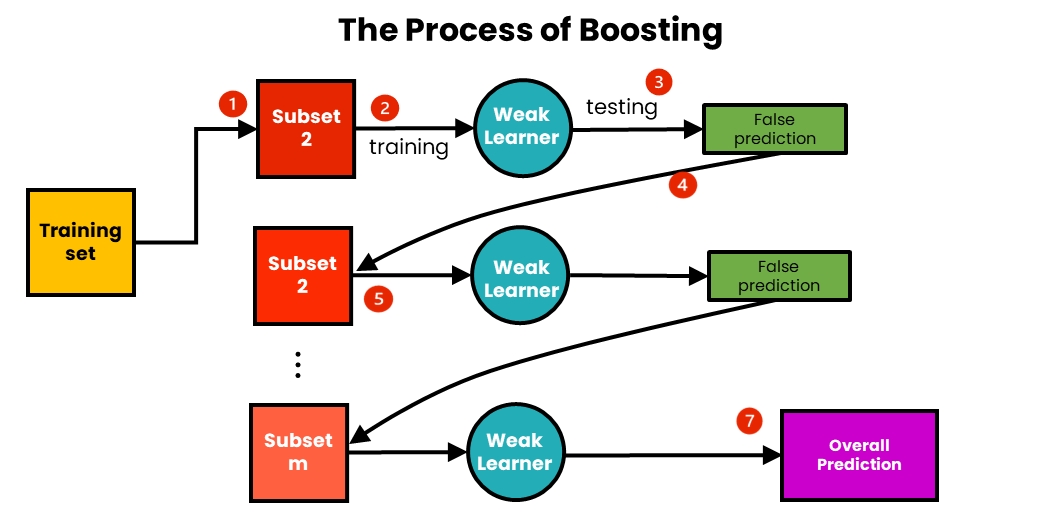
Кожній одиниці даних датасету присвоюється вага, неправильно класифіковані точки отримують більшу вагу в наступних ітераціях. Оскільки boosting є ітеративним методом, його найкраще використовувати на shallow моделях, ніж на великих та складних. На відміну від bagging, тут передбачення видає остання модель, фінальної функції немає.
Stacking
Гетерегенне ансамлювання, зменшує bias
Навчання: кожна модель навчається незалежно
Для Stacking моделі можуть навчатися як паралельно, так і послідовно. Вважається найбільш потужним алгоритмом, оскільки дає можливість використовувати різні типи моделей, а замість фінальної функції використовується мета-модель, яка оброблює передбачення вже навчених моделей.
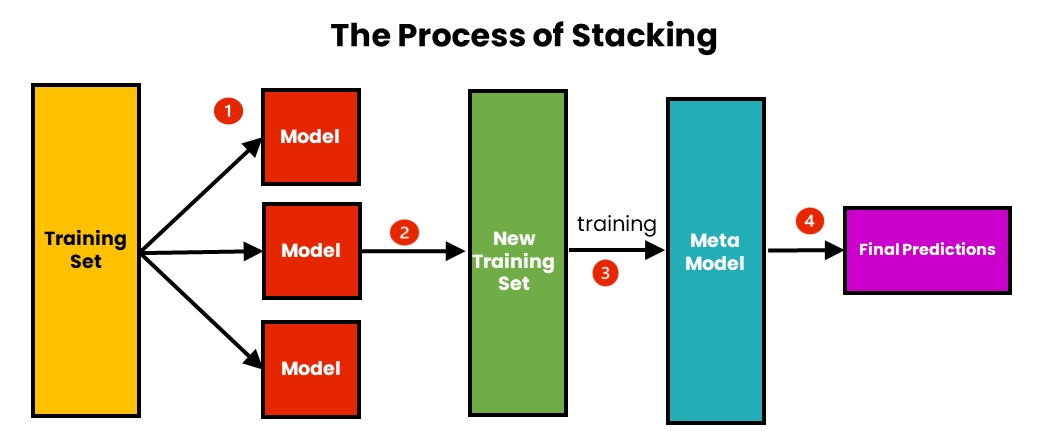
Важливим моментом ансамблювання є те, що вибір моделей повинен узгоджуватися зі способом поєднання цих моделей. Якщо обираються базові моделі з низьким bias, але високою variance, то це має бути метод ансамблювання, який має тенденцію до зменшення дисперсії (variance), тоді як якщо обираються моделі з низькою дисперсією, але високим зміщенням (bias), то це має бути метод ансамблювання, який має тенденцію до зменшення bias. Алгоритми машинного навчання з низькою дисперсією включають лінійну регресію, логістичну регресію та лінійний дискримінантний аналіз (LDA). До алгоритмів з високою дисперсією відносяться Random Forest, SVM і KNN.
Незбалансовані класи
Незбалансовані датасети мають нерівну кількість елементів у класах і без належної обробки (або використання методів, які можуть оброблювати незбалансовані класи - Random Forest) можуть призвести до перенавчання або недонавчання.
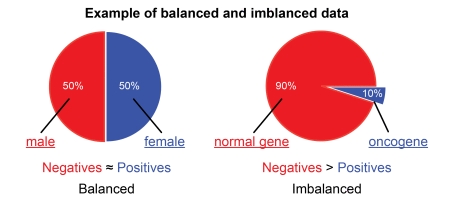
Уявімо, що маємо незбалансований датасет, на якому потрібно навчити класифікатор для розпізнавання пухлини. Датасет містить 90% фотографій пацієнтів без пухлина та 10% з пухлиною. При використання оригінального датасету для навчання модель, скоріше за все, буде класифікувати, а точніше просто виводити результат “пухлини немає“, без обробки паттернів у даних. Грубо кажучи, замість нейромережі отримаємо програму, яка буде виводити в консоль “пухлини немає“.
Для навчання робастного класифікатора найбільш популярними методами є методи додавання даних до малих класів (OverSampling) або зниження кількості елементів всіх класів до кількості елементів найменшого класу (Undersampling).
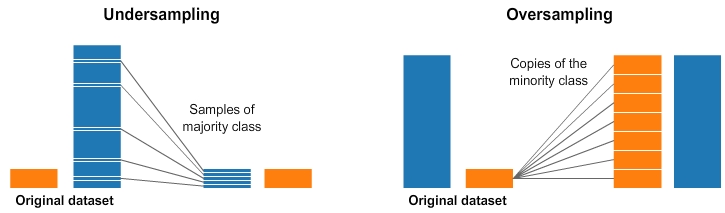
Вибір який з методів використовувати залежить від конкретної ситуації, але в більшості випадків Undersampling не обирають, бо він приводить до втрати даних.
Steel Plate Defect Prediction Competition
Мій повний код можете знаходиться тут.
Обробка даних
Мета змагання - розробити класифікатор для класифікації подряпин по 7 класам. Оригінальний датасет має 34 ознаки, це не 200, але і не 3, необхідно спробувати зменшити кількість ознак.
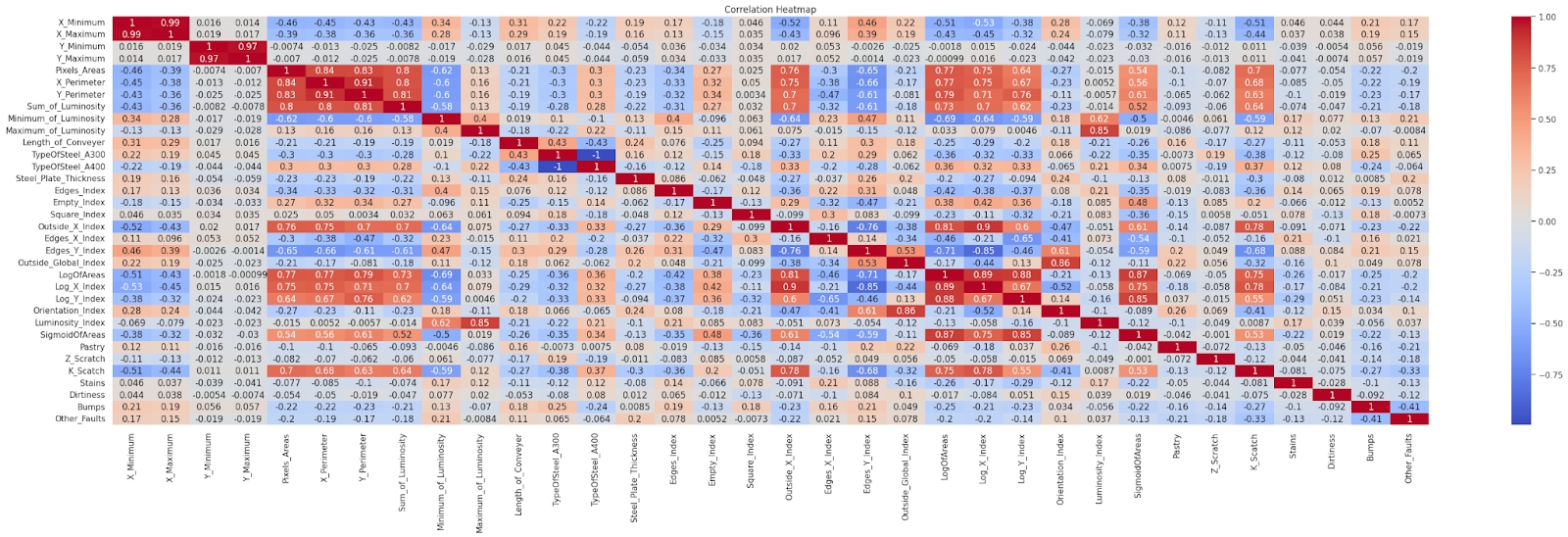
Кореляція
Деякі ознаки мають високу кореляцію - одну ознаку можна виразити через іншу. Кореляція не дає змогу зрозуміти, наскільки важливі ознаки, тим самим зменшуючи інтерпретованість моделі - розробнику складно зрозуміти, через які ознаки модель має низьку точність та як можна покращити. Інтерпретованість неймовірна важлива та цікава тема, про яку розповім в наступних довгочитах, присвячених вже MLOps.
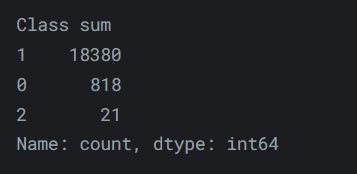
Деякі семпли (одиниці даних датасету) мають одразу декілька міток класів, а деякі не мають міток взагалі, що фактично робить з багатокласової класифікації multilabel класифікацію. Деякі розробники вирішили будувати саме multilabel модель, але я вирішила залишитися у багатокласовій класифікації.
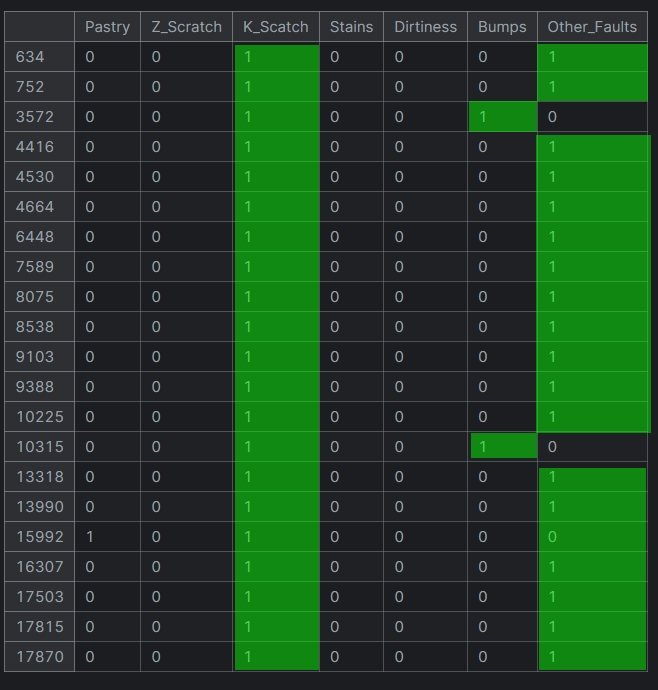
Для вирішення цієї проблеми зробила наступне:
Залишити тільки одну мітку - Other_faults у семплів, що мають декілька лейблів.
Семпли, які не мають подряпин видалила. Можна припустити, що вони потрапили у датасет помилково.
Feature Engineering
Датасет має 13 ознак, перетворивши які можна зменшити розмірність даних. Наприклад, віднявши від X_maximun Y_minimum знаходиться ранжування, тобто, з двох ознак створюється спільна, тим самим позбавляючи кореляції.
def calculate_coordinate_range_features():
data['X_Range'] = (data['X_Maximum'] - data['X_Minimum'])
data['Y_Range'] =( data['Y_Maximum'] - data['Y_Minimum'])
data.drop(["X_Maximum","Y_Minimum","X_Minimum","Y_Maximum"], axis=1, inplace=True)Функція def feature_engineering(data) є прикладом nested функції.
Після застосування залишилося 22 ознаки.
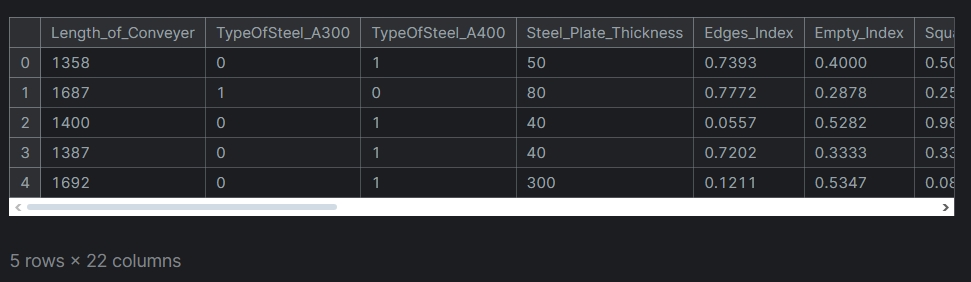
Привидення ознак до одного діапазону (scaling) є необхідною процедурою для деяких алгоритмів, але майже завжди не є зайвою, оскільки допомагає пришвидшити навчання. Робила за допомогою RobustScaler, окремо для тестової та тренувальної вибірки.
from sklearn.preprocessing import RobustScaler
train = train_x_featENG.astype(np.float64)
test = test.astype(np.float64)
test=feature_engineering(test)
scaler = RobustScaler()
train_scaling = scaler.fit_transform(train)
test_scaling = scaler.transform(test)Вибір саме такого скейлера обумовлений тим, що дані мають викиди.
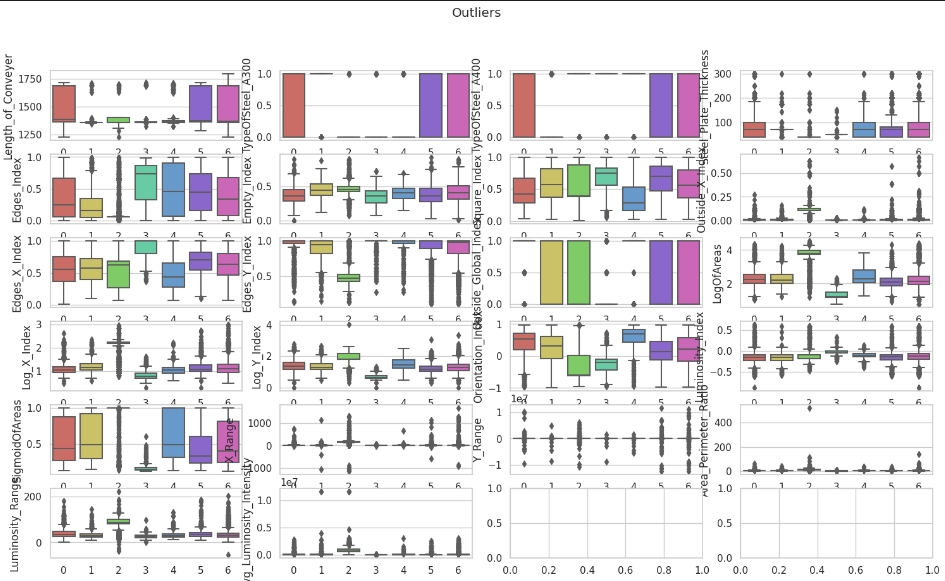
Незбалансовані класи
Для балансування класів обрала техніку збільшення малих класів - OverSample, оскільки кількість даних і так невелика, щоб додатково зменшувати через UnderSample.
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(sampling_strategy='auto', random_state=42)
sampling_y=train_y.to_numpy()
X_res, y_res = ros.fit_resample(train_scaling, sampling_y)
Візуалізація та зменшення розмірності
Hypertools - бібліотека для геометричної візуалізації багатовимірних даних, на відміну від PCA, що є технікою Зменшення розмірності. Що перший, що других алгоритм показують, що розділювальну площину буде побудувати не так вже й просто.
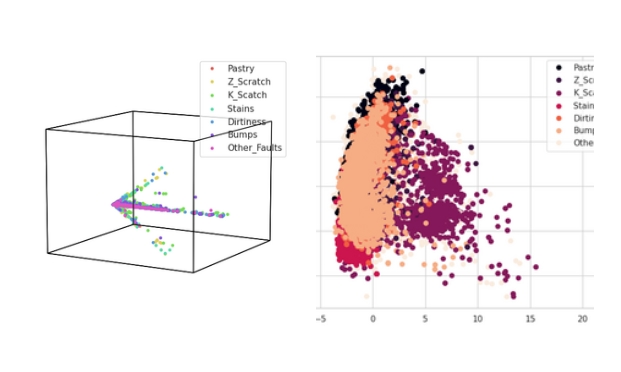
Вирішила не використовувати дані, на яких будувала PCA задля чистоти експерименту ансамблювання.
Ансамблювання
Я зробила для варіанти ансамблювання:
Зведення результатів двох boosting методів, XGBoost та LightGBM за допомогою VotingClassifier, що є майже bagging методом
Weighted Average ансамблювання двох нейромереж за допомогою мета - моделі, спрощений Stacking, бо я люблю експерементувати.
VotingClassifier
Для цієї реалізації попередньо зробила тюнінг XGBoost моделі, проте LightGBM модель залишила з мануальними параметрами (для LightGBM тюнінг не робила, оскільки всі можливі GPU в Кегглі вже використала, без них тюнінг неймовірно довгий).
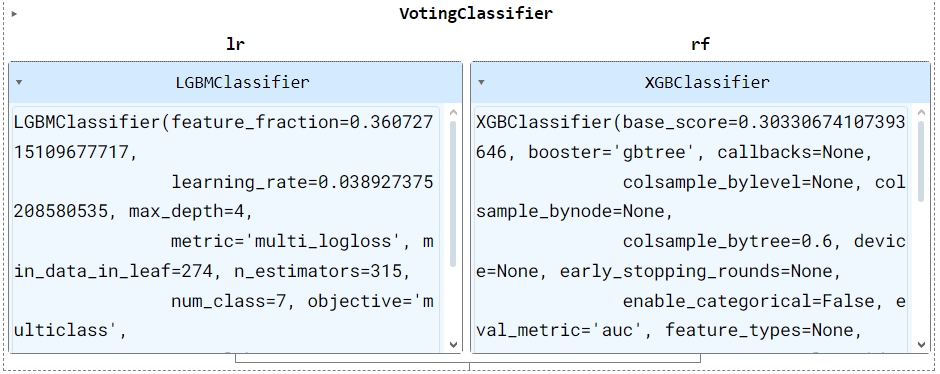
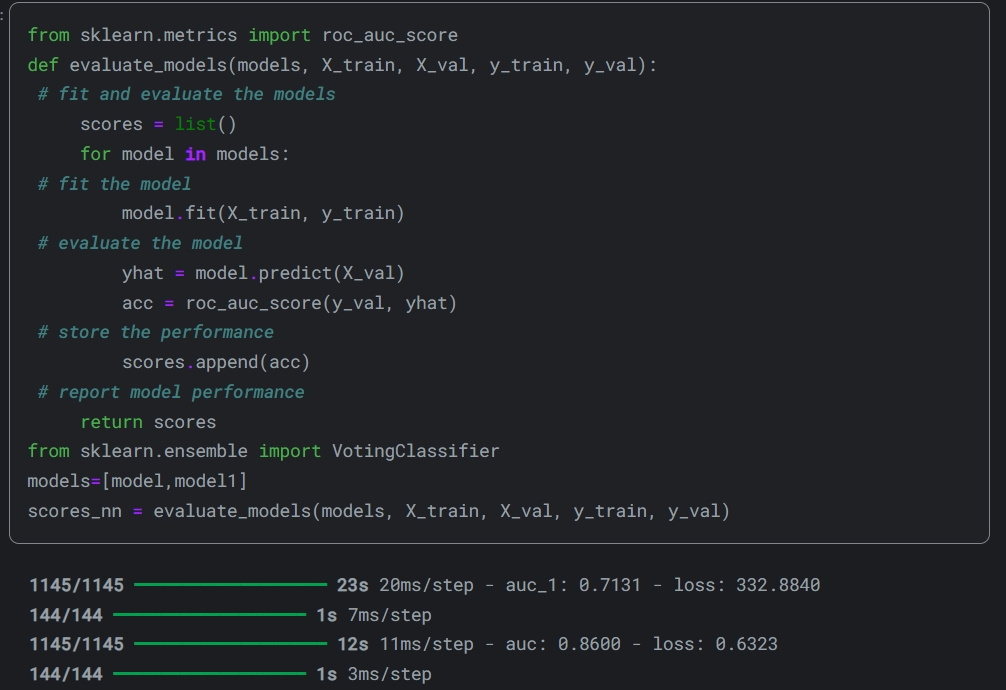
Для VotingClassifier необхідним параметром є ваги, які в моєму випадку є ROC-AUC оцінкою двох моделей: чим нижче точність моделі, тим менший її вплив на передбачення.
def evaluate_models(models, X_train, X_val, y_train, y_val):
# fit and evaluate the models
scores = list()
for model in models:
# fit the model
model.fit(X_train, y_train)
# evaluate the model
yhat = model.predict_proba(X_val)
acc = roc_auc_score(y_val, yhat)
# store the performance
scores.append(acc)
# report model performance
return scores
from sklearn.ensemble import VotingClassifier
models=[LGBMClassifier(**parameters_dict),XGBClassifier(**c)]
scores = evaluate_models(models, X_train, X_test, y_train, y_test)
# create the ensemble
ensemble = VotingClassifier(estimators=[('lr', LGBMClassifier(**parameters_dict)), ('rf', XGBClassifier(**c))], voting='soft', weights=scores)Обрала soft - voting, оскільки ансемблюю тільки дві моделі. Точність на тестувальному наборі довольна висока, точність на валідаційному, по якому оцінюються учасники змагання, нижча.


WeightedAverage Ensembling + skip - connections NN
WeightedAverage є простим методом ансамблювання.
Так, передбачаючі запитання, я додала вельми відомі skip - connections до однієї з двох ансамблевих нейромереж, такі зв’язки допомагають градієнту не затухати. Повна схема дуже велика, можете подивитися тут. Блок skip - connections виглядає наступним чином:
def skip_connection(previous_layer):
def skip():
start = layers.Dense(256, activation="leaky_relu")(previous_layer)
dense_0 = layers.Dense(256, activation="leaky_relu")(start)
dense_1 = layers.Dense(256, activation="leaky_relu")(dense_0)
dense_2 = layers.Dense(128, activation="leaky_relu")(dense_1)
dense_3 = layers.Dense(128, activation="leaky_relu")(dense_2)
batch_norm = layers.BatchNormalization()(dense_3)
dense_4 = layers.Dense(128, activation="leaky_relu")(batch_norm)
concat = keras.layers.Concatenate(axis=1)([start, dense_4])
#batch_norm_1 = layers.BatchNormalization()(concat)
outputs = layers.Dense(128, activation="leaky_relu")(concat)
return outputs
return skip()Повна структура першої нейромережі:
inputs = keras.Input(shape=(X.shape[1],))
dense_1=layers.Dense(256, activation="leaky_relu")(inputs)
dense_2=layers.Dense(512, activation="leaky_relu")(dense_1)
#batchNorm_1=layers.BatchNormalization()(dense_2)
s=skip_connection(dense_2)
dropout=tf.keras.layers.Dropout(0.2)(s)
s2=skip_connection(dropout)
dropout_2=tf.keras.layers.Dropout(0.3)(s2)
s3=skip_connection(dropout_2)
dropout_3=tf.keras.layers.Dropout(0.2)(s3)
#s4=skip_connection(dropout_3)
#dropout_4=tf.keras.layers.Dropout(0.3)(s4)
dense_3=layers.Dense(256, activation="leaky_relu")(dropout_3)
dense_3_1=layers.Dense(128, activation="leaky_relu")(dense_3)
dense_4=layers.Dense(7, activation="softmax")(dense_3_1)
model = keras.Model(inputs=inputs, outputs=dense_4,name="skip_conn_model")Задля швидшого навчання друга модель має дуже просту архітектуру, без skip - connections:
inputs = keras.Input(shape=(X.shape[1],))
dense_1=layers.Dense(256, activation="elu")(inputs)
dense_2=layers.Dense(512, activation="elu")(dense_1)
batchNorm_1=tf.keras.layers.Dropout(0.4)(dense_2)
#s=skip_connection(batchNorm_1)
#dropout_2=tf.keras.layers.Dropout(0.4)(s)
dense_3=layers.Dense(512, activation="elu")(batchNorm_1)
dense_3_1=layers.Dense(256, activation="elu")(dense_3)
dropout_2=tf.keras.layers.Dropout(0.2)(dense_3_1)
dense_3_2=layers.Dense(128, activation="elu")(dropout_2)
dense_4=layers.Dense(7, activation="softplus")(dense_3_2)
model1 = keras.Model(inputs=inputs, outputs=dense_4,name="light_model")Оптимайзер для обох моделей - Adam, метріка - AUC.
Перенавчання моделей, які довго вчиш дуже неприємна річ, тому найкращі ваги зберігаю за допомогою checkpoints у моделі після навчання. У деяких статтях можна побачити зберігання найкращих вагів через EarlyStopping, але це неправильно.
def checheckpoints(model):
path='/kaggle/working/Weights_'+model.name+'.weights.h5.keras'
checkpoint = tf.keras.callbacks.ModelCheckpoint(path,
monitor="val_loss", mode="min",
save_best_only=True, verbose=10)
return checkpoint,path
callback = tf.keras.callbacks.EarlyStopping(
monitor="val_loss",
patience=10
)Результати навчання
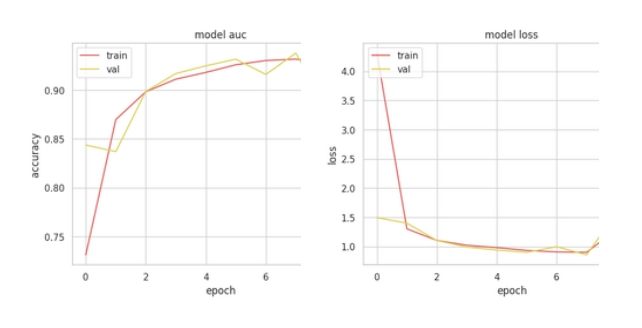
Друга, простіша модель, на моє здивування показала набагато кращі результати.
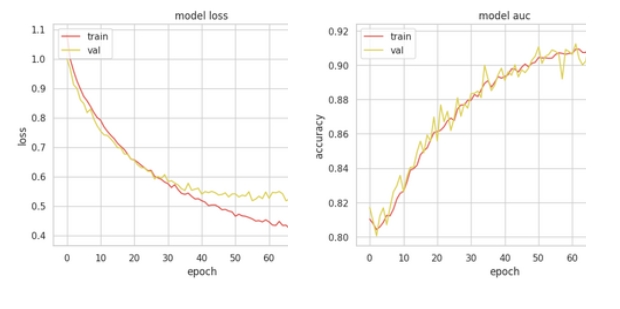
Перенавчання почалося на 40 епосі, до цього, функція помилки рівномірно спадала.
Такі результати добре показують, що першу модель треба спростити, або додати регуляризацію. В реальних проектах, моделі звичайно треба тюнінгувати. Аналогічно з першим варіантом, як ваги для ансамлювання використала ROC - AUC.
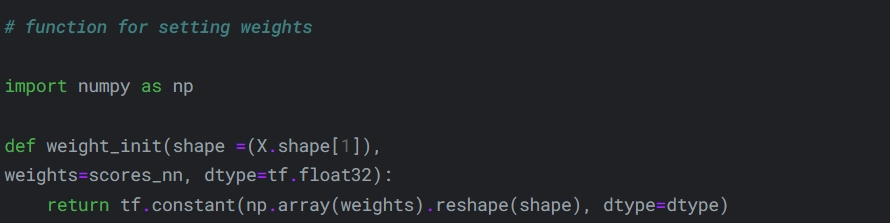
Блок усереднення передбачення двох моделей.
class WeightedAverage(Layer):
def __init__(self):
super(WeightedAverage, self).__init__()
def build(self, input_shape):
self.W = self.add_weight(
shape=(len(input_shape),),
initializer=weight_init,
dtype=tf.float32,
trainable=True)
def call(self, inputs):
inputs = [tf.expand_dims(i, -1) for i in inputs]
inputs = Concatenate(axis=-1)(inputs)
weights = tf.nn.softmax(self.W, axis=-1)
return tf.reduce_mean(weights*inputs, axis=-1)Мета модель має наступний вигляд:
inputs = Input(shape=(X.shape[1],), name='inputs') # input layer
# get output for each input model
outputs = [model(inputs) for model in models]
# take average of the outputs
x = WeightedAverage()(outputs)
x = layers.Dense(512, activation='leaky_relu')(x)
x = tf.keras.layers.Dropout(0.4)(x)
x = layers.Dense(256, activation='leaky_relu')(x)
x = layers.Dense(128, activation='leaky_relu')(x)
x = tf.keras.layers.Dropout(0.4)(x)
x = layers.Dense(128, activation='leaky_relu')(x)
x = layers.Dense(64, activation='leaky_relu')(x)
output = layers.Dense(7, activation='softmax', name='output')(x) # output layer
# create average ensembled model
avg_model = keras.Model(inputs, output)
Що ж, експеримент наразі є не дуже успішним, але я планую продовжити намагатися підвищити точність іншими методами.
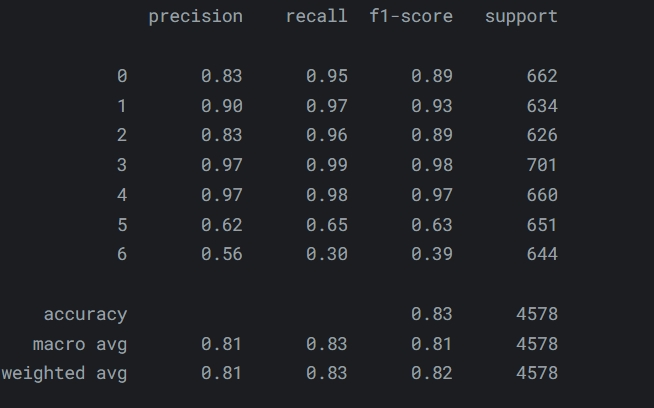
Можливе пояснення - це проблема в самому датасеті, тобто потрібно змінити тактику feature engineering, та спробувати синтетичні дані.
Дякую за прочитання! Буду дуже рада відповісти на всі запитання.
