Як створюються, тестуються та контролюються моделі машинного навчання у реальних проектах. Розглянемо автоматизацію трансформації даних за допомогою TFX.
Різниця між продуктовим та науковим підходом у ML
(І чому на Kaggle не завжди хороші рішення)
Будь - який алгоритм машинного навчання чи нейромережа залежні від даних, на яких навчаються. У сучасному світі тенденція даних може змінюватися кожну годину, кожен день, тощо, в залежності від області. Від цих змін і залежить якість моделей: зміна середнього значення, розподілу, тощо - призведуть до неможлиості використання моделі, якщо модель не перенавчати кожен раз, як відбувається зміна у даних. MLPOps (ML + DevOps) - це область, яка адаптує DevOps практики для створення, розгортання та підтримки моделей, здатних адаптуватися до змін.
В чому різниця між MLOps рішеннями та тим, що можна побачити на Kaggle або у наукових есе? Відповідь - статичність даних. Що на Kaggle, що при розробці нових моделей вчені та інженери використовують статичний датасет, для обслуговування якого не треба розробляти окрему інфраструктуру і який достатньо обробити (очистити) один раз. У таких задачах нестатичний датасет і непотрібний, бо мета - це розробка високоякісної моделі, яку можна використовувати в подальшому.
MLOps якраз і допомагає це зробити - створити “цикл”, завдяки якому можна постійно контролювати якість та стан самої моделі, так і даних, і якщо дані змінилися, модель перенавчається на оновленому датасеті.
Kaggle хоч і є найбільшою платформою для ML інженерів та аналітиків, але рішення, навіть якщо вони виставляються у змаганнях та посідають перші місця, можуть бути не оптимізовані або навіть не пристосовані для автоматизації.
Pipeline та основні етапи розробки у MLOps
Pipeline - це спосіб автоматизації всіх процесів (стадій) розробки ML моделей. Тобто, замість інженера кожну ячейку кода (кожен файл), запускає оркестратор. Умовно стадії розробки моделі можна розділити на 4 категорії:
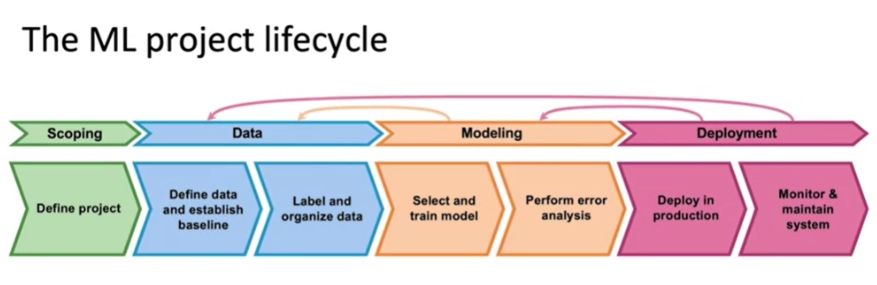
Scoping - визначення потреб та цілей проєкта. Наприклад: потрібно розробити модель для передбачення ціни на нерухомість. Виходячи з цього, модель повинна вирішувати задачу регресії, а активаційна функція повинна бути лінійною. На цьому ж етапі визначаються з технічними характеристиками проекту: тип бази даних, hardware, тощо. Вибір бази даних залежить від часу, за який потрібно отримати передбачення моделі.
Data - все про дані. Статистичні показники, відбір потрібних ознак, лейблування, трансформація. На цьому етапі формується розуміння “слабких сторін” даних - статистичних або інших особливостей, що можуть призвести до низької якості моделі. Baseline - це ті показники, які модель може мати (показники якості та помилок). Найчастіше використовується HLP (Human Level Performance - людський показник), який показує наскільки точно людина може виконати поставлену задачу. Наприклад, якщо розробляється модель для детекції раку на знімках, як HLP візьметься точність, з якою лікар може визначити, чи є пухлина. Визначити baseline дуже важливо для розуміння продуктивності моделі.
Modelling - розробка моделі/моделей, тюнінг, тестування: чи є перенавчання або недонавчання, яка якість на різних класах (для класифікації), тощо.
Deployment - деплой моделі та створення системи для постійного моніторингу. Моніторинг дає змогу одразу визначити проблеми та зміни у даних , моделя - Drift та Skew.
Pipeline складається з трьох останній стадій: Data, Modelling, Deployment.
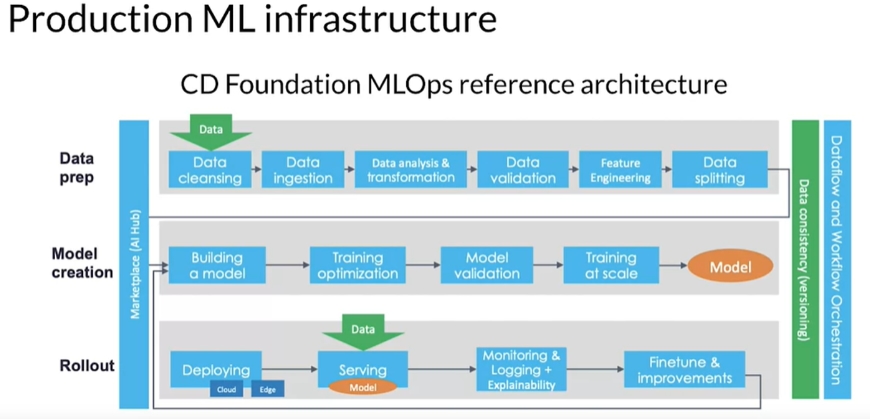
Pipeline є циклічним, Modelling та Deployment повторюють постійно, поки якість моделі не досягне потрібного значення при тестуванні та поки модель обслуговується (коли модель вже використовується користувачами). Результатом виконання кожної стадії є артефакти, які генеруються під час виконання компонентів pipeline та охоплюють усе, створене конвеєром, включаючи дані на різних етапах перетворення, схеми, показники та моделі. Метадані - це дані про інші дані, характеристики, властивості та зв’язки між наборами даних, моделей та інших елементів. Метадані допомагають зрозуміти життєвий цикл даних і керувати ним, відстежувати зміни, виправляти проблеми, забезпечувати відтворюваність і дотримуватись правових і нормативних вимог. Містять таку інформацію, як джерело даних, дата створення, авторство, перетворення даних, параметри навчання моделі тощо. Метадані відіграють вирішальну роль в управлінні даними та сприянні співпраці між науковцями та зацікавленими сторонами.
Data preparation. Input: дані з бази даних або data lake, output: трансформовані дані (артефакти) та метадата, які завантажуються в окрему базу даних.
Model Creation. Input: дані та метадата з попереднього кроку, output: модель (артефакт) та метадата.
Rollout. Input: артефакти з попередніх стадій, output: показники, що відслідковуються (якість, помилки) та метадані.
Кожний етап пайплайну необхідний та важливий. Не можна забувати також і про важливість моніторингу, який може запобігти “взлому“ моделі. Методи хакінгу моделі можуть здатися, на перший погляд, не дуже елегантними та складними, але вони дієві. Наприклад, якщо додати шум на фотографію кішки та надіслати у класифікатор, точність передбачення або дуже сильно впаде, або передбачення буде зовсім некоректним: фотографію кішки позначить як клас “собака“.
Виявлення та моніторинг помилок (Drift та Skew)
Колись настане момент, де зміна у даних може призвести до поганих або навіть катастрофічних наслідків. Уявіть, що ви розробляєте модель для аналізу кількості та типів взуття, яке потрібно закупити магазину. У перший рік ваша модель працює дуже добре, магазин закупає рівно стільки взуття, скільки може продати. У наступному році тренд змінюється, покупці хочуть придбати інші моделі взуття, але у магазині їх немає, бо модель не змогла проаналізувати новий тренд. Існує два типи таких помилок (data issue):
Drift (Data drift, Concept drift) - це зміна у даних з часом, через яку точність моделі падає (Model Decay). Data drift сигналізує про зміну даних у часі: користувач почав надсилати більше повідомлень, але система фіксує це як спам.
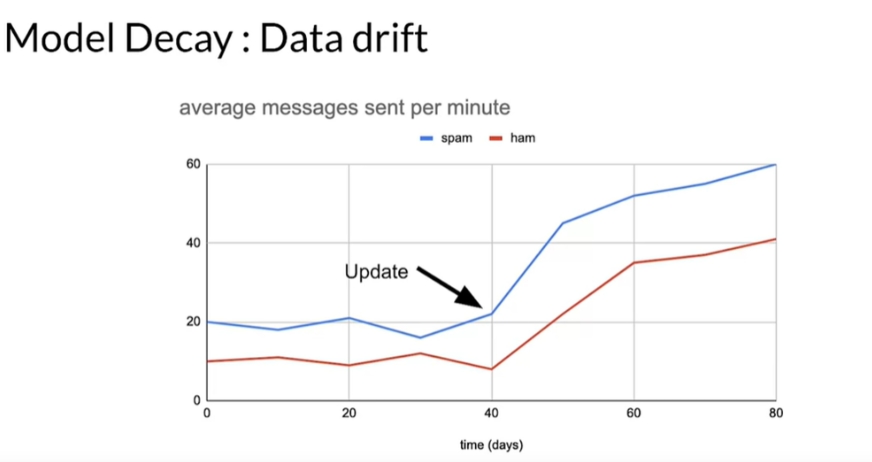
Зміна кількості повідомлень впливає на неправильну класифікацію повідомлень Concept drift сигналізує про зміну паттернів та зв’язків даних. Прикладом є зміна патерну між тренувальними та тестувальними даними (зміна ознак).
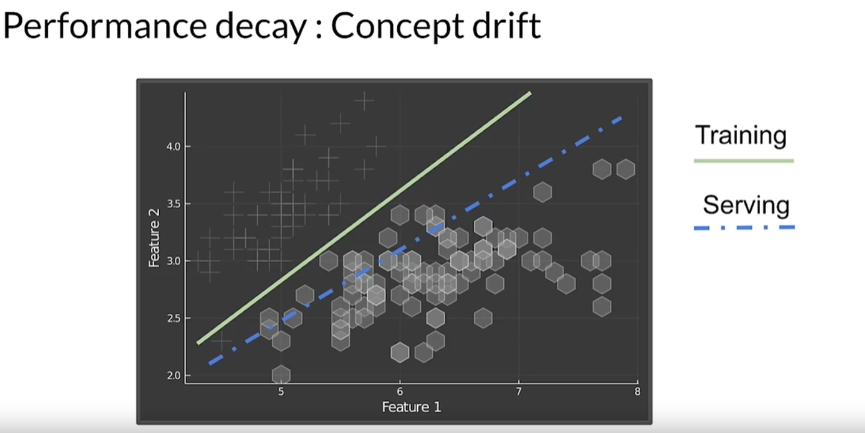
Skew (Schema skew, Distribution skew) - це різниця між джерелами даних, наприклад, тренувальний та валідаційний набори мають різний розподіл або тип ознак відрізняється (ознака у одному наборі має тип Int, у іншому тип Float). Для різних skew існують різні методи виявлення. Наприклад, для Schema skew (різниця між наборами даних) потрібно порівняти статистичні показники всіх наборів даних.
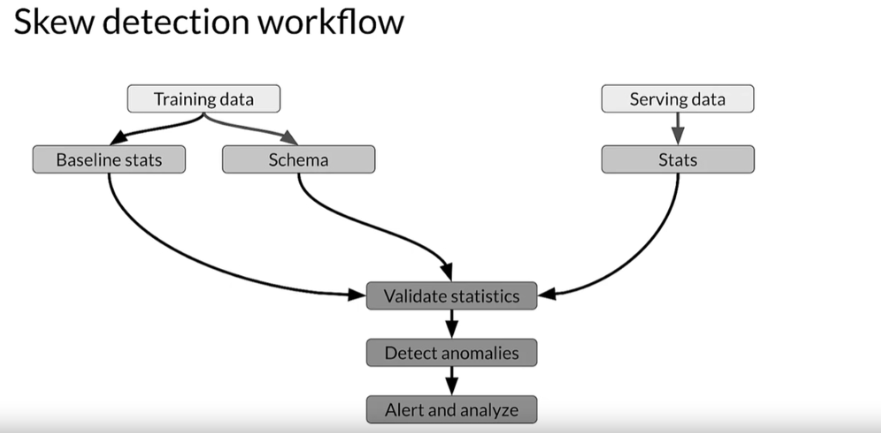
Алгоритм виявлення skew Distribution skew розділяють на 3 підвиди:
Covariate Shift: зміни в розподілі вхідних змінних, на яких навчається модель. - Це відбувається, коли граничний (marginal) розподіл ознак (вхідних змінних) відрізняється між навчальним і валідаційним наборами даних, тоді як умовний (conditional) розподіл залишається незмінним. Наприклад, якщо статистичні властивості ознак змінюються у одному з наборів.
Concept Shift: зміна між вхідними та вихідними даними. Відбувається, коли умовний (conditional) розподіл міток (лейблів класів) не є однаковим між навчальним та валідаційним наборами, тоді як граничний розподіл залишається незмінним.
Dataset Shift: зміна статистичних властивостей даних. Це включає зміну середовище, де збираються дані, та методів збору.

Математичне визначення
Database, Data Warehouse, Data Lake та Feature Store
Що перше приходить на думку, коли уявляєте базу даних? Скоріше за все, віртуальне сховище даних. Але яке саме? Чи можуть там зберігатися дані за якийсь час, або тільки у real - time? Чи ці дані структуровані, чи розташовані у якомусь порядку. Всі ці питання характеризують 4 види місць, що зберігають інформацію (я спеціально не написала баз даних, щоб не ввести у плутанину)
Бази даних (Database) - це сховище даних, яке зберігає поточну інформацію, яка доступна в real - time. Максимальний розмір - n гігабіт. Запити прості та виконуються теж в real - time. Для ефективності таблиці треба нормалізують.
Data Warehouse - об’єктно - орієнтовані, розроблені для зберігання терабайтів даних та версій даних з часовими мітками. На відміну від баз даних, аналізують та збирають дані з багатьох джерел, але не підтримують запити в real - time, запити мають більш складну будову та виконуються довше, але оптимізовані для читання. Нормалізація не потрібна. Зберігають тільки структуровані дані.
Data Lake - використовуються саме для аналізу даних, зберігають як структуровані, та і не структуровані (зображення, музика тощо) дані у raw форматі (необроблені) з декількох джерел. Як і бази даних, можуть зберігати гігабайти даних.
Feature Store - центральний репозиторій даних конкретно для ML завдань, є приватними, компанія зазвичай розробляє власний feature store. Якщо коротко описати, то feature store виконує роль репозиторія даних. Доступ до таких сховищ контролюється та може розділятися між командами.. Дозволяють трансформувати дані, видаляють дублікати.
Такі сховища можуть бути як онлайн, так і офлайн. Офлайн зберігає вже оброблені дані, тоді як для обробки даних онлайн потрібно використовувати батчі.
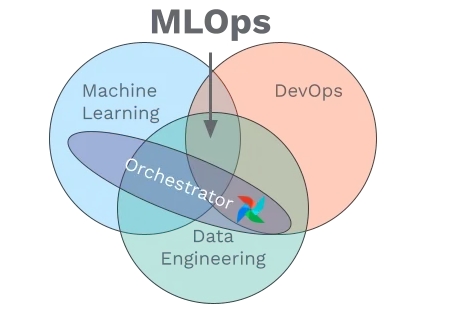
Оркестратори
Коли я тільки починала вивчати MLOps та побачила слово оркестратор, моя перша думка була: “це ж як дирижер“. І частково, так і є: як і дирижер, оркестратор слідкує за виконанням кожного етапу у чітко визначеній послідовності. Робота оркестратора - це автоматизація пайплайнів та контроль над величезними потоками даних, які надходять у модель, він запускає кожний елемент пайплайну у потрібній послідовності у потрібний час.
На щастя, кількість оркестраторів все збільшується, і навіть якщо проект працює у маловідомому домені, можна знайти підходящий оркестратор.
Оркестратор є важливим компонентом у будь-якому стеку MLOps, оскільки він відповідає за роботу пайплайнів. Для цього оркестратор забезпечує середовище, налаштоване для виконання кроків вашого пайплайну. Він також гарантує, що кроки вашого пайплайну виконуються лише тоді, коли всі їхні вхідні дані (які є виходами попередніх кроків вашого пайплайну) доступні.
Найпопулярнішими оркестраторами є Airflow та Kuberflow. У цій вводній статті я не буду зосереджувати увагу на них, оскільки планує приділити багато часу у наступних.
А зараз давайте поговоримо про те, як запустити пайплайн без оркестратора. Так, це можливо, але тільки на локальному комп’ютері. Бібліотека TFX, яку буду використовувати, має:
Середовище Context, де можна запустити окремі елементи пайплайну (про них у наступному розділі). При використанні Context інженеру потрібно самостійно запускати пайплайн, тобто автоматизації немає.
LocalDagRunner, ваш власний оркестратор, автоматизує пайплайн, але тільки на локальному комп’ютері.
Для демонстрації буду використовувати і той, і той метод.
MLOps бібліотеки
Найвідоміші та найбільш використовувані бібліотеки - це TFX (Tensorflow), Kuberflow Pipeline (Kuberflow) та MLFlow (Databricks). Коротке порівняння TFX та MLFlow:
Моніторинг: MLflow частіше використовують для моніторингу через зручніше систему, тоді як у TFX використовуються метадані, які можна вивести у TensorBoard.
Моделі: MLFlow є більш гнучкою, дозволяючи використовувати різні типи моделей, на відміну від TFX, що працює з моделями, створених за допомогою Tensorflow.
Компоненти Pipeline: TFX працює тільки з елементами TensorFlow, тоді як MLflow є більш гнучким і може працювати з різними фреймворками ML.
Портативність: моделі MLflow можна легко переносити в різні середовища завдяки формату MLmodel. Конвеєри TFX тісніше пов’язані з TensorFlow, їх може бути складніше перенести у потрібне середовище.
Відмінність Kuberflow Pipeline від попередніх бібліотек у способі побудови пайплайну, а саме у вигляді графів, використовуючи інші бібліотеки. Kuberflow Pipeline найчастіше використовують як оркестратор в інших бібліотеках, а не як засіб для створення pipeline, оскільки для кожного компонента пайплайну потрібно створювати .yaml файл.
У цій статті я буду використовувати TFX бібліотеку, як на мене, вона більш легка у розумінні.
TFX�
Як говорила раніше, результатом виконання кожного елемента у TFX є артефакти та метадані. Для кожної задачі є окремий компонент:
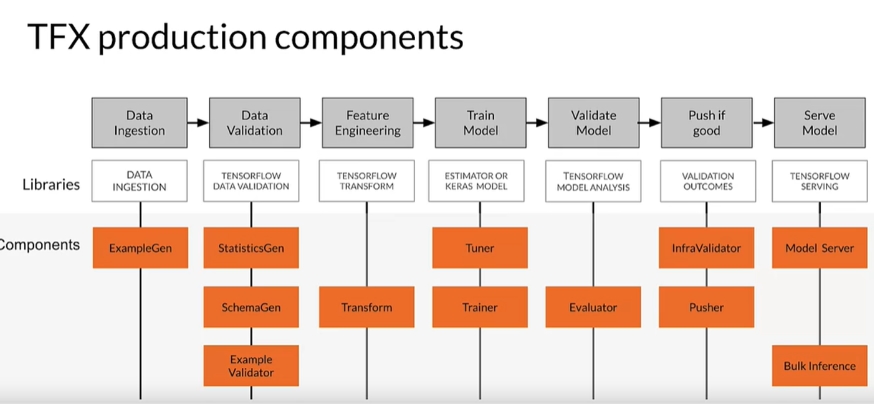
1. ExampleGen: завантажує та обробляє необроблені дані, перетворюючи їх у формат, придатний для наступних компонентів. Також розділяє на тренувальний та тестувальні ні нібори.
2. StatisticsGen: обчислює підсумкову статистику набору даних, наприклад середнє значення, медіану, стандартне відхилення та гістограми ознак. Ці статистичні дані мають вирішальне значення для розуміння характеристики даних.
3. SchemaGen: генерує схему для набору даних на основі обчисленої статистики з StatisticsGen. Схема зберігає очікувані типи даних, діапазони та інші обмеження для кожної ознаки.
4. ExampleValidator: перевіряє набір даних на аномалії через SchemaGen та StatisticsGen. У випадку, якщо у наборі даних ознака має інший тип даних, інший діапазон даних, ExampleValidator це реєструє.
5. Transform: перетворення, масштабування, групування, виконує всі перетворення, що потрібні під конкретну задачу.
6. Tuner: компонент для тюнінгу моделі, має схожу з Trainer структуру. Для тюнінгу можуть використовувати алгоритми, не тільки присутні у Tensorflow.
7. Trainer: тут відбувається навчання моделі. Якщо гіперпараметри моделі попередньо отримані у Tuner, буде використовувати саме їх.
8. Evaluator: оцінює продуктивність навчених моделей, використовуючи різні показники. Порівнює продуктивність різних моделей і допомагає визначити найефективнішу для деплою.
9. InfraValidator: перевіряє проблеми сумісності, обмеження ресурсів та інші проблеми, пов’язані з деплоєм.
10. Pusher: відповідає за деплой моделі, якщо вона проходить перевірку та відповідає необхідним критеріям якості, інтегрується з такими платформами, як TensorFlow Serving, TensorFlow Lite, TensorFlow.js і TensorFlow Hub.
TFDV є окремою бібліотекою, але частиною TFX, яку також використовують самостійно для попереднього аналізу даних, а також для зміни схеми. Не потребує оркестратора для роботи. У багатьох туторіалах використовують TFDV як заміну TFX, але безпосередньо для пайплайнів вона вже не підходить, окрім зміни схем.
Data Transform via TFX
Повний код: https://www.kaggle.com/code/annack/data-transformation-and-eda-with-tfx?scriptVersionId=180667855
Датасет складається з 16 ознак, які формують ціну автомобіля, ключову ознаку.
Перш за все, потрібно визначити звідки та куди будуть йти дані та артефакти, метадані зберігаються окремо.
# location of the pipeline metadata store
_pipeline_root = 'kaggle/working/pipeline/'
# directory of the raw data files
_data_root = '/kaggle/input/car-price-prediction-challenge'Далі, в залежності від виду середовища, визначити його. Спочатку хочу показати за допомогою Context.
#create context aka local env in TFX
context = InteractiveContext(pipeline_root=_pipeline_root)ExampleGen
Перетворення raw даних у формат, який може обробляти елементи TFX та розділення на тренувальний та тестовий набори.
#transform raw data in required format for next stages
example_gen=CsvExampleGen(input_base=_data_root)
context.run(example_gen)Після успішного виконання можна передивитися інформацію про створений артефакт.
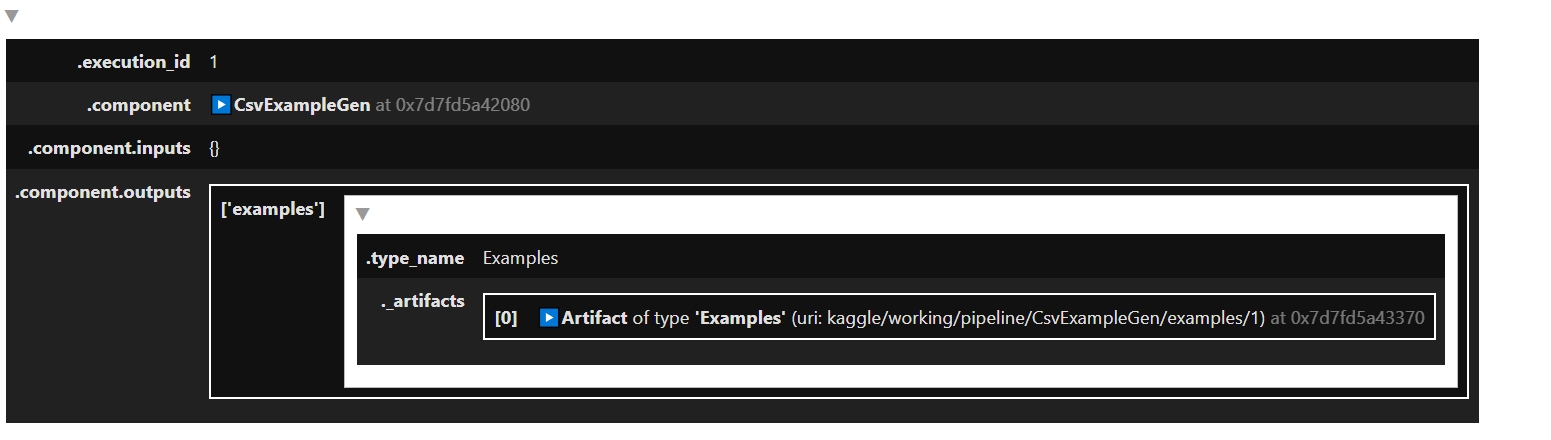
Створений артефакт та метадаys зберігаються у окремих папках, що створюються за вказаною адресою (_pipeline_root).
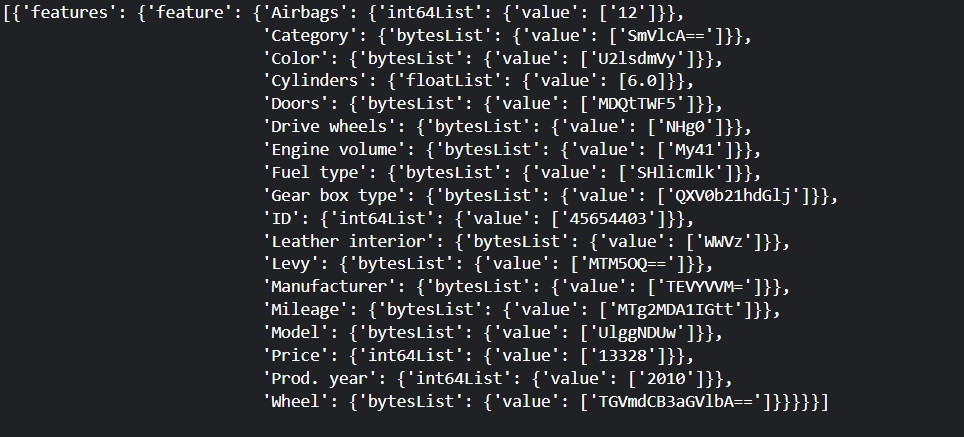
Індивідуальні екземпляри не можна взяти безпосередньо з компонента, потрібно писати допоміжну функцію, у мене це def get_records(dataset, num_records), що повертає лист.
StatisticsGen
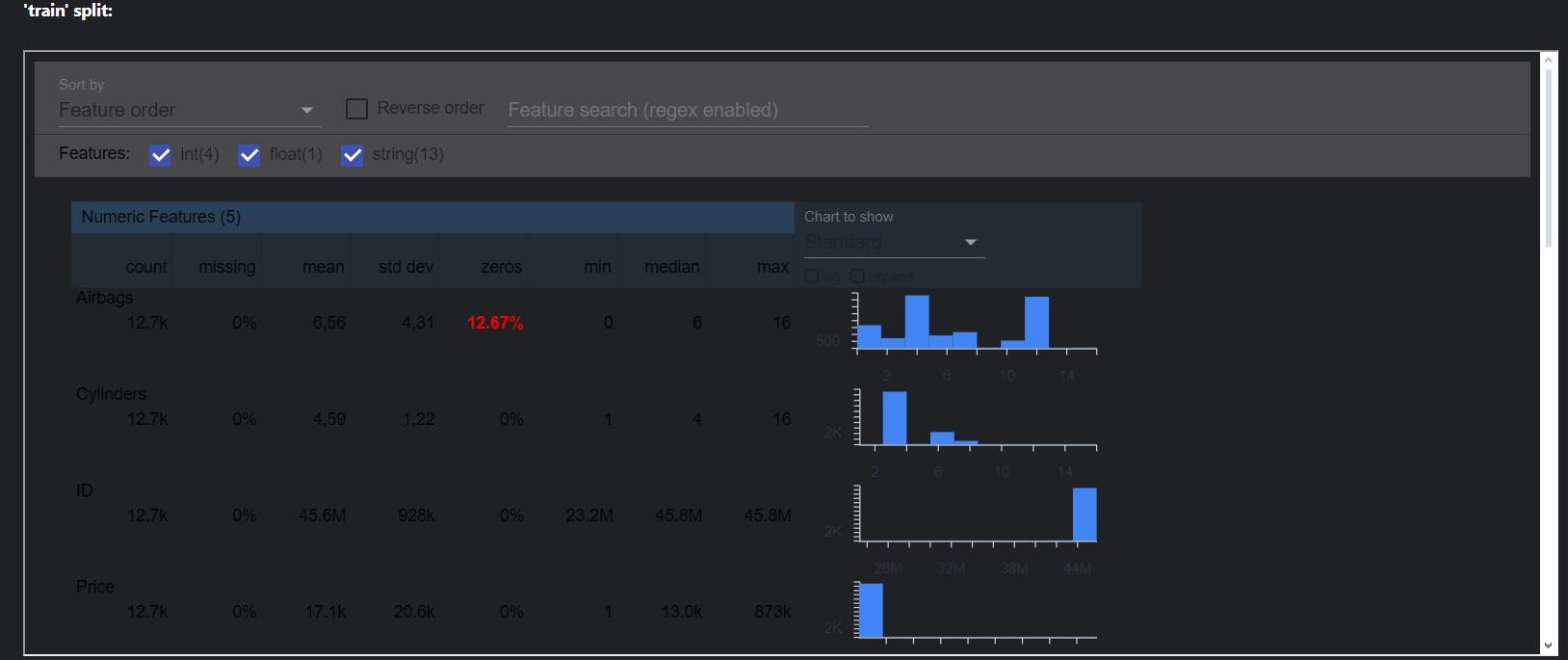
Генерація статистики для всіх наборів даних, в цьому випадку - для тренувального та тестового наборів.
statistics_gen=StatisticsGen(examples=example_gen.outputs["examples"])
context.run(statistics_gen)Аналогічно з ExampleGen, після виконання з’являється інформація про створені артефакти. Для візуалізації створеного артефакта існує наступна команда:
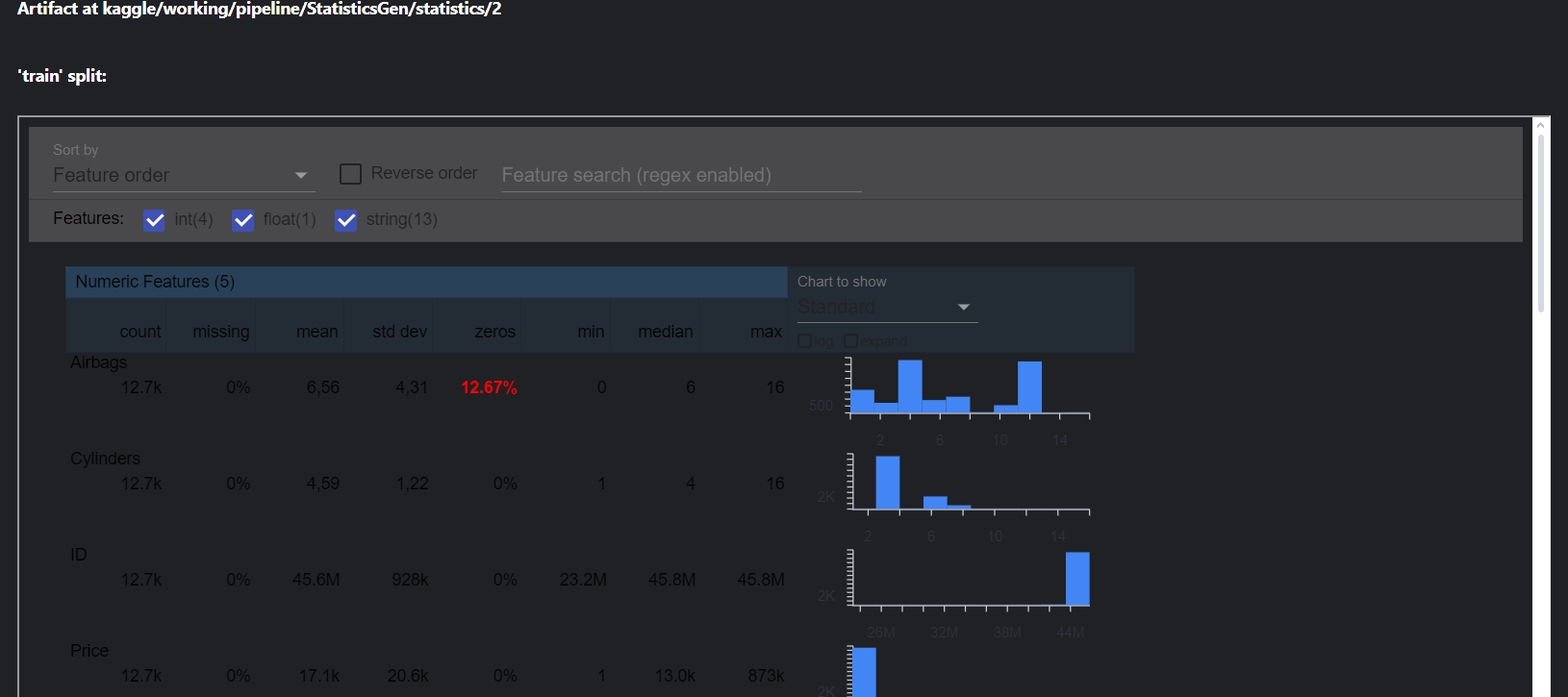
context.show(statistics_gen.outputs["statistics"])Зверніть увагу, що артефакти знаходяться у outputs.
У вікні візуалізації можна подивитися розподіл, середнє, чи є пропущені дані або знайти інформації щодо конкретної ознаки.
�SchemaGen
Створює схему (таблицю) з типом, доменами та можливими значеннями/діапазонами ознак.
schema_gen=SchemaGen(statistics=statistics_gen.outputs["statistics"],infer_feature_shape=True)
context.run(schema_gen)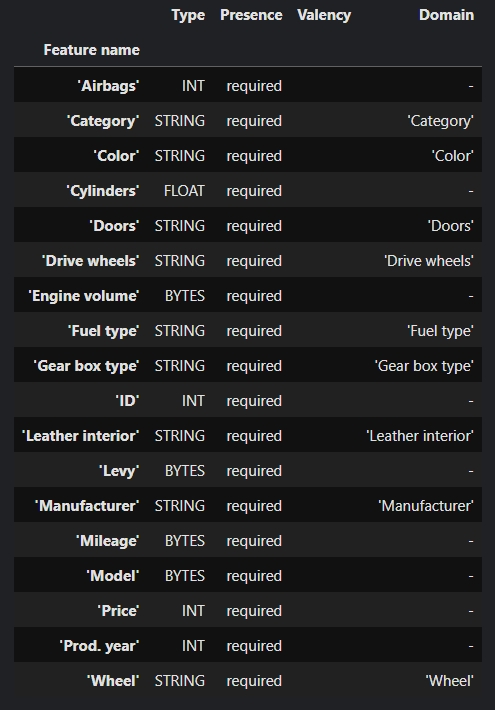
Завдяки схемі відстежуються drift та skew у даних. Стовбець “Presence“ відповідає за перевірку наявності ознак, якщо у ознаки є мітка “required“, то ознака повинна бути в усіх наборах даних, а у випадку, якщо ознака відсутня, при перевірці з ExsmpleValidator буде помилка.
Виникає резонне питання: скільки схем повинно бути всього, чи потрібно створювати окремо схему для кожного набору даних? Це залежить від задачі. Для supervised навчання зазвичай створюється одна схема для всіх наборів даних, щоб не пропустити drift чи skew. Тоді виникає наступне питання, що робити з target ознакою (Y матриця, яка містить цільову ознаку у тренувальному наборі), оскільки що в тестувальному та валідаційному, що в даних, отриманих від користувача, цільової ознаки не буде? Треба дати “зрозуміти“ пайплайну, що відсутність цільової ознаки не є помилкою, тобто, зміни мітку з “required“ на “optional“. Скажу чесно, я доволі довго шукала, як це зробити, бо гайдів дуже мало. Ось спосіб, що знайшла:
Отримати розташування згенерованої схеми
schema_path = os.path.join(schema_gen.outputs["schema"].get()[0].uri, 'schema.pbtxt') #only showing training as an exampleЗавантажити за допомогою TFDV.
Це самий той випадок, до використання TFDV безпосередньо в пайплайні є доцільним.
import tensorflow_data_validation as tfdv schema=tfdv.load_schema_text(schema_path)Створити папку для оновленої схеми
_updated_schema_dir = "/kaggle/working/kaggle/working/pipeline/UpdatedSchema" # Create the new directory for updated schema !mkdir -p {_updated_schema_dir}Змінити min_fraction та зберегти
min_fraction відповідає за “кількість“ ознаки у даних, якщо потрібно менше 100% (1) ознаки, то вона вважається опціональною.
#get target feature price_feature = tfdv.get_feature(schema, 'Price') price_feature.ClearField('shape') #change target presence to 0.5 - change field to "optional" price_feature.presence.min_fraction= 0.5 tfdv.display_schema(schema) #write new schema tfdv.write_schema_text(schema, os.path.join("/kaggle/working/kaggle/working/pipeline/UpdatedSchema", 'schema.pbtxt'))

Якщо не видалити розмірність ознаки, під час трансформації буде наступна помилка:
price_feature.ClearField('shape')
Помилка, якщо розмірність не видалити Додати оновлену схему до метаданих
Щоб використовувати будь - які імпортовані компоненти, вони повинні бути в сховищі метаданих. Цей пункт вкрай важливий, але мало де можна знайти його використання.
# Use an ImporterNode to put the curated schema to ML Metadata from tfx.v1.dsl import Importer from tfx.types import standard_artifacts user_schema_importer = Importer( source_uri="/kaggle/working/kaggle/working/pipeline/UpdatedSchema", artifact_type=standard_artifacts.Schema) # Run the component context.run(user_schema_importer, enable_cache=False)user_schema_importer має всі ті є властивості, що і стандартна схема:
Інформація про утворені артефакти
ExampleValidator
Перевірка на drift та skew за допомогою створеною схеми.
example_validator=ExampleValidator(statistics=statistics_gen.outputs["statistics"],schema=user_schema_importer.outputs['result'])
context.run(example_validator)Тут на вхід подається артефакти одразу двох компонентів: статистика та схема.
context.show(example_validator.outputs["anomalies"])
Жодних аномалій не знайдено, оскільки датасет був цілісний, а не розділений не різні набори одразу.
Transform
Тут відбуваються всі перетворення даних: нормалізація, feature cross, тощо. Щоб спростити, числові ознаки та цільову ознаку (Price) нормалізую, а категоріальні закодую через аналог one - hot encodding. Цей компонент, як і подальші, використовують користувацькі інструкції - окремий файл, в якому знаходиться весь код для обробки даних.
Спершу потрібно створити файл, де ознаки будуть розділені по групам. Для більшою гнучкості ознаки та трансформація розділені по різним файлах
# Set the constants module filename
transformation_file_constant = 'user_tranformation_constant_.py'%%writefile {transformation_file_constant}
categorical_features=["Category","Color","Doors","Drive wheels","Engine volume","Fuel type","Gear box type","Leather interior","Levy","Manufacturer","Mileage","Model","Wheel"]
numerical_features=["Airbags","Cylinders","ID","Prod. year"]
# Feature that the model will predict
label_key = 'Price'
# Utility function for renaming the feature
def transformed_name(key):
return key + '_xf'Перевіримо, чи коректні ознаки у числовій групі
import user_tranformation_constant_
user_tranformation_constant_.numerical_features
Далі, створюємо сам файл для обробки.
# Set the transform module filename
_transformation_module_file = 'user_tranformation_module.py'%%writefile {_transformation_module_file}
import tensorflow as tf
import tensorflow_transform as tft
import pandas as pd
import user_tranformation_constant_
# Unpack the contents of the constants module
_NUMERIC_FEATURE_KEYS = user_tranformation_constant_.numerical_features
_CATEGORICAL_FEATURE_KEYS = user_tranformation_constant_.categorical_features
#_FLOAT_INT_FEATURE_KEYS = User_tranformation_constant.numerical_features
_LABEL_KEY = user_tranformation_constant_.label_key
_transformed_name = user_tranformation_constant_.transformed_name
# Define the transformations
def preprocessing_fn(inputs):
"""tf.transform's callback function for preprocessing inputs.
Args:
inputs: map from feature keys to raw not-yet-transformed features.
Returns:
Map from string feature key to transformed feature operations.
"""
outputs = {}
# Scale these features to the range [0,1]
for key in _NUMERIC_FEATURE_KEYS:
outputs[_transformed_name(key)] = tft.scale_to_0_1(
inputs[key])
outputs[_transformed_name(_LABEL_KEY)]=tft.scale_to_0_1(inputs[_LABEL_KEY])
for key in _CATEGORICAL_FEATURE_KEYS:
# Ensure the feature is treated as a string
string_feature = tf.strings.as_string(inputs[key])
#tf.print("Processing feature:", key, "with shape:", tf.shape(string_feature))
# Reshape the tensor to remove the extra dimension if necessary
string_feature_flat = tf.squeeze(string_feature, axis=-1)
#tf.print("Flattened feature shape:", tf.shape(string_feature_flat))
# Apply vocabulary transformation
transformed_feature = tft.compute_and_apply_vocabulary(
string_feature_flat,
default_value=-1, # Specify a default value for out-of-vocabulary tokens
num_oov_buckets=1 # Specify the number of out-of-vocabulary buckets
)
outputs[_transformed_name(key)] = transformed_feature
#tf.print("Transformed feature:", key, "with shape:", tf.shape(transformed_feature))
return outputsПри енкодування категоріальних ознак обов’язково треба прибирати зайві розмірності:
string_feature_flat = tf.squeeze(string_feature, axis=-1)Аналогічно з попередніми компронентами, Transform запускається через context. На вхід подаються самі дані з ExampleGen, схема та файл трансформацій.
tf.get_logger().setLevel("ERROR")
transform = Transform(
examples=example_gen.outputs['examples'],
schema=user_schema_importer.outputs['result'],
module_file=os.path.abspath(_transformation_module_file))
context.run(transform)Артефактів з цього компонента набагато більше, ніж з попередніх.
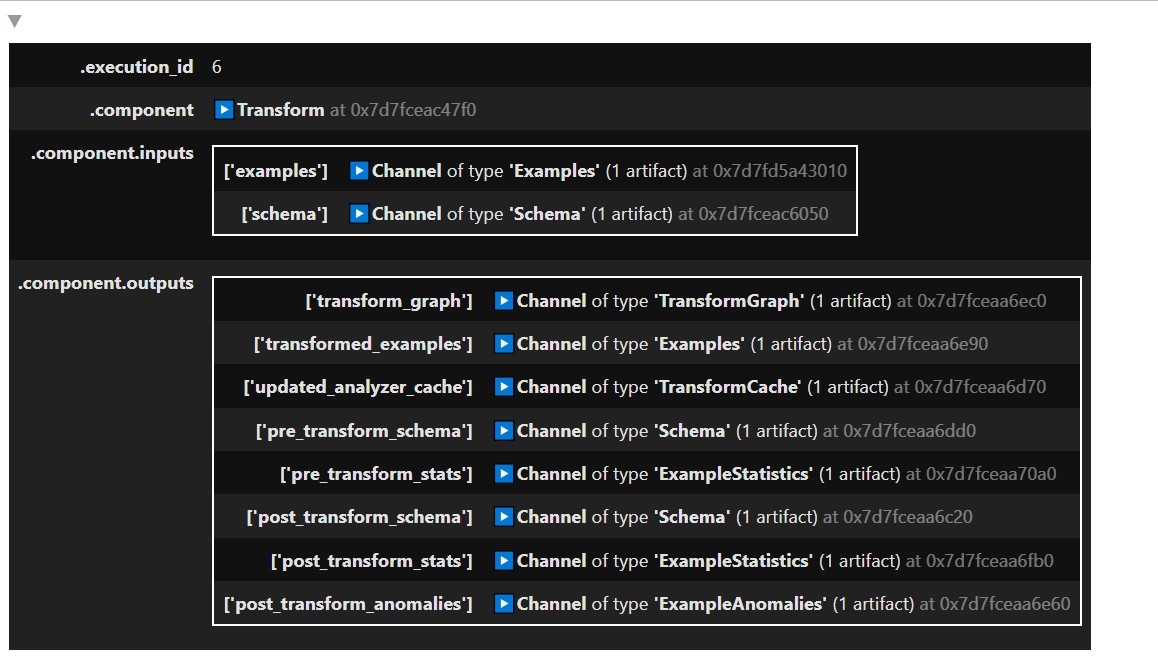
Видаляти цільову ознаку з тестувального набору буду під час тюнінгу у наступній статті.
Пайплайн на локальному оркестраторі LocalDagRunner()
LocalDagRunner() є “міні - версією“ оркестратора для локального комп’ютера.
Всі ті ж самі компонети, що і в попередньому розділі, але замість запуску кожного окремо, запускаються автоматизовано.
_metadata_path="/kaggle/working/kaggle/working/pipeline/metadata.sqlite"
_pipeline_name="car-price-pred-challenge"
_schema_path="/kaggle/working/kaggle/working/pipeline/UpdatedSchema"
def _create_pipeline(pipeline_name:str,pipeline_root: str, data_root: str,
metadata_path: str,schema_path:str) -> tfx.dsl.Pipeline:
example_gen = tfx.components.CsvExampleGen(input_base=data_root)
# Computes statistics over data for visualization and example validation.
statistics_gen = tfx.components.StatisticsGen(
examples=example_gen.outputs['examples'])
# import updated schema
schema_importer = Importer(
source_uri=schema_path,
artifact_type=standard_artifacts.Schema
)
example_validator = tfx.components.ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_importer.outputs['result'])
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_importer.outputs['result'],
module_file=os.path.abspath(_transformation_module_file))
components = [
example_gen,
statistics_gen,
schema_importer,
example_validator,
transform
]
return tfx.dsl.Pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
metadata_connection_config=tfx.orchestration.metadata
.sqlite_metadata_connection_config(metadata_path),
components=components)metadata_path_ автоматично створюється у коренній папці пайплайну.
Після визначення пайплайну запускаємо його через оркестратор:
tfx.orchestration.LocalDagRunner().run(
_create_pipeline(
pipeline_name=_pipeline_name,
pipeline_root=_pipeline_root,
data_root=_data_root,
metadata_path=_metadata_path,
schema_path=_schema_path))Для візуалізації окремого компоненту потрібно мати додаткову функцію:
from tfx.orchestration.portable.mlmd import execution_lib
def get_latest_artifacts(metadata, pipeline_name, component_id):
"""Output artifacts of the latest run of the component."""
context = metadata.store.get_context_by_type_and_name(
'node', f'{pipeline_name}.{component_id}')
executions = metadata.store.get_executions_by_context(context.id)
latest_execution = max(executions,
key=lambda e:e.last_update_time_since_epoch)
return execution_lib.get_output_artifacts(metadata, latest_execution.id)Вона завантажує результат виконання потрібного компонента з бібліотеки MLMD - бібліотеку метадати TFX. Далі, з’єднуємося з MLMD та визначаємо, який саме компонент потрібно отримати. Я хочу вивести результат StatisticsGen:
from tfx.orchestration.metadata import Metadata
from tfx.types import standard_component_specs
metadata_connection_config = tfx.orchestration.metadata.sqlite_metadata_connection_config(
_metadata_path)
with Metadata(metadata_connection_config) as metadata_handler:
ev_output = get_latest_artifacts(metadata_handler, _pipeline_name,
'StatisticsGen')
anomalies_artifacts = ev_output[standard_component_specs.STATISTICS_KEY]Змінна anomalies_artifacts містить всі дані про артефакт.
І для візуалізації створюю ще одну додаткову функцію:
# Non-public APIs, just for showcase.
from tfx.orchestration.experimental.interactive import visualizations
def visualize_artifacts(artifacts):
"""Visualizes artifacts using standard visualization modules."""
for artifact in artifacts:
visualization = visualizations.get_registry().get_visualization(
artifact.type_name)
if visualization:
visualization.display(artifact)
from tfx.orchestration.experimental.interactive import standard_visualizations
standard_visualizations.register_standard_visualizations()visualize_artifacts(anomalies_artifacts)Отримаю те ж саме віконечко з статистикою, що і при запуску на context.
Дякую, що прочитали! У наступній статті про тюнінг, тренування та валідацію моделі.
Джерела для подальшого вивчення
Machine Learning Orchestration vs MLOps
Feature Store vs Data Warehouse
The best orchestration tool for MLOps: a real story about difficult choices
SELECTING YOUR OPTIMAL MLOPS STACK: ADVANTAGES AND CHALLENGES
4 Challenges of Reproducibility in the Machine Learning Model Deployment
TensorFlow Extended 101: (literally) Everything you need to know
Курс та спеціалізація: https://www.deeplearning.ai/courses/machine-learning-in-production/
