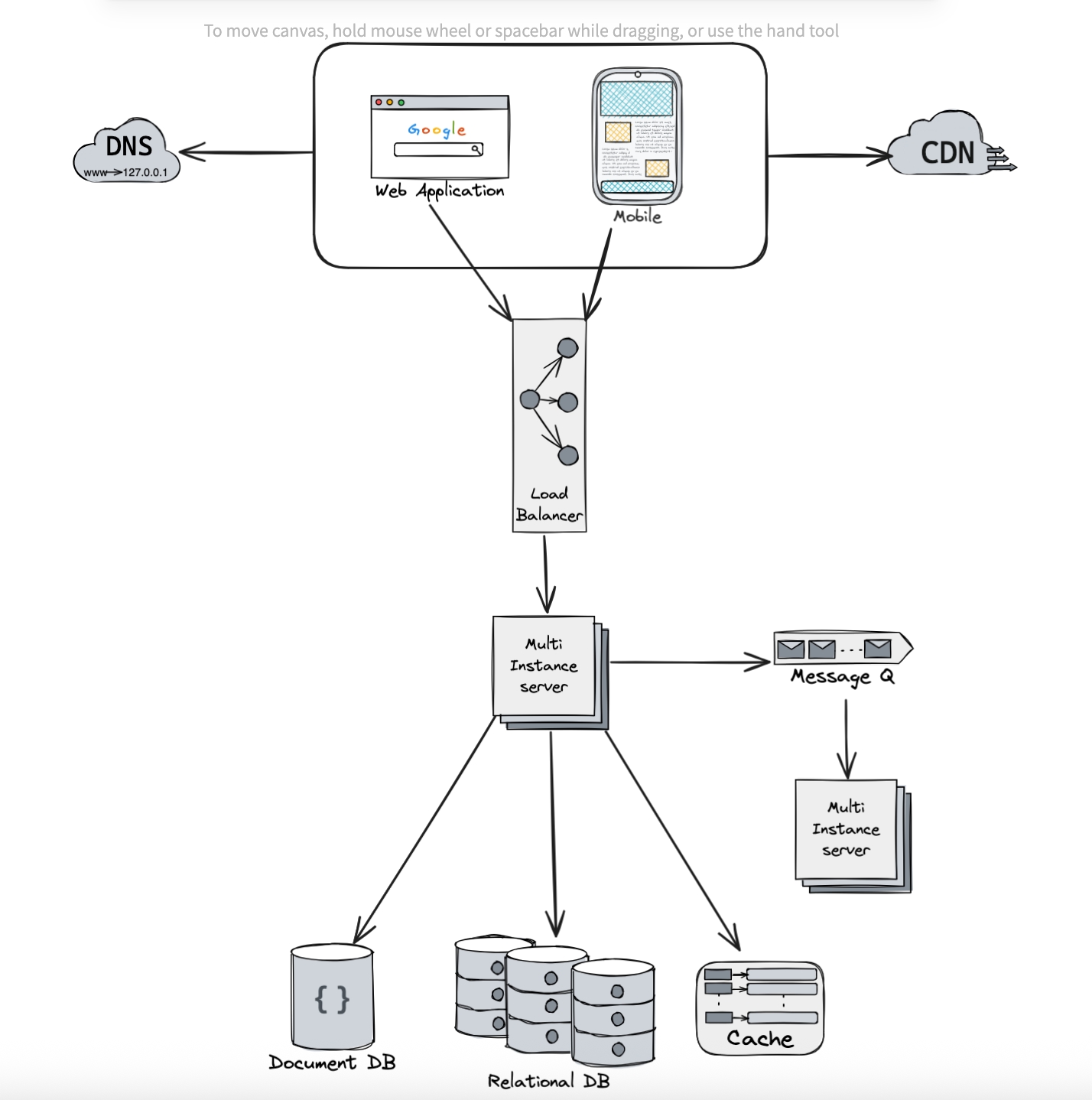
У цій частині я коротко розповім про найважливіше, що треба знати перед проходженням інтерв’ю з системного дизайну.
1. Числа та терміни
Почнемо з основного які числа треба знати (̶о̶ ̶н̶і̶ ̶з̶н̶о̶в̶у̶ ̶м̶а̶т̶а̶н̶)̶
📏 Одиниці виміру даних
Назва | Скорочення | Формула | У байтах |
|---|---|---|---|
Байт | B | – | 1 B |
Кілобайт | KB | 1 KB = 1024 B | 1,024 B |
Мегабайт | MB | 1 MB = 1024 KB | 1,048,576 B |
Гігабайт | GB | 1 GB = 1024 MB | 1,073,741,824 B |
Терабайт | TB | 1 TB = 1024 GB | 1,099,511,627,776 B |
⏱ Latency Numbers
Операція | Приблизна затримка |
|---|---|
🧮 CPU L1 cache access | 0.5 ns |
🧮 CPU L2 cache access | 7 ns |
🧠 Main memory (RAM) access | 100 ns |
🔁 Mutex lock/unlock (в одному треді) | 25 ns – 1 µs |
📦 SSD I/O (NVMe, local) | 10–100 µs |
🧳 SSD I/O (SATA) | 100–500 µs |
💽 HDD I/O (seek) | ~10 ms |
🔌 Network: 1 Gbps (loopback) | ~0.5 ms |
🌐 Data center to same-region server (ping) | 0.5–1 ms |
🌍 Data center to another region (US–EU) | 70–150 ms |
✈️ Transcontinental RTT | ~150–250 ms |
☁️ Lambda cold start | ~100 ms – few sec |
⏱ Context switch (kernel ↔ user) | ~1 µs – 5 µs |
💬 Redis read (local network) | ~1 ms |
💾 DB query (simple SELECT, indexed) | ~1–10 ms |
📤 Kafka publish (no replication, async) | ~1 ms |
💡 Висновки:
Пам’ять — дуже швидка, диск — дуже повільний.
Уникай доступів до диска без потреби.
Стискай дані перед передачею.
Міжрегіональна передача — дорога по часу.
✅ Таблиця доступності (SLA)
SLA (доступність) | Дозволений час простою на рік | На місяць | На тиждень | На день |
|---|---|---|---|---|
90.0% ("одна дев’ятка") | ~36.5 днів | ~72 год | ~16.8 год | ~2.4 год |
99.0% | ~3.65 днів | ~7.2 год | ~1.68 год | ~14.4 хв |
99.9% ("три дев’ятки") | ~8.76 год | ~43.8 хв | ~10.1 хв | ~1.44 хв |
99.99% ("чотири дев’ятки") | ~52.6 хв | ~4.4 хв | ~1 хв | ~8.6 сек |
99.999% ("п’ять дев’яток") | ~5.26 хв | ~26.3 сек | ~6 сек | ~0.86 сек |
99.9999% ("шість дев’яток") | ~31.5 сек | ~2.6 сек | ~0.6 сек | ~0.086 сек |
SLA до 99.0%
(до ~3.5 днів простою на рік)
Підійде для внутрішніх систем, MVP або некритичних сервісів.
Один інстанс сервісу
Проста БД без реплікації
Резервне копіювання (раз на добу або тиждень)
Мінімальний моніторинг (health-check)
SLA 99.9% (три дев’ятки)
(~9 год на рік простою)
Підходить для SaaS, мобільних застосунків, бізнес-критичних API.
Горизонтальне масштабування (щонайменше 2 інстанси)
Load Balancer (наприклад, NGINX, ALB)
Високодоступна БД: реплікація, автоматичне відновлення (RDS Multi-AZ, Mongo ReplicaSet)
Моніторинг та алертинг (Prometheus, Grafana, PagerDuty)
Zero-downtime деплой (blue/green, canary)
SLA 99.99% і вище
(<1 год простою на рік)
Вимагається у банківських, медичних системах, хмарних платформах, біржах.
Мультирегіональна розгорнута інфраструктура
Автоматичне виявлення збоїв + самовідновлення
Розподілені черги (Kafka, SQS) + ретраї
DB Failover + шардінг
Кешування для захисту від “thundering herd” (Redis, CDN)
Chaos Engineering: імітація відмов для тестування стійкості (Netflix's Simian Army)
Бізнес-логіка, що вміє "гречно падати" (graceful degradation)
SLO/SLA дашборди + регулярний аудит доступності
🔤 Популярні терміни
QPS — queries per second
DAU — daily active users
SLA — service level agreement
RPS — requests per second
2. Інструменти для малювання архітектури
Де б̶л̶*̶ть̶ малювати? 👀
Excalidraw — рекомендую. Простий, з готовими бібліотеками (System Design Components → Browse Libraries. Або просто пере ходиш за цим посиланням 🙂).
3. Етапи інтерв’ю
📋 Знайомство з задачею
🔍 Збір вимог (функціональні й нефункціональні)
🧱 Високорівневе проєктування
🔬 Занурення у складні компоненти
📑 Перевірка сценаріїв
❓ Q&A по схемі
✅ Фіналізація
Зазвичай інтерв’ювер дає якесь абстрактне завдання наприклад імплементуй твітер. Твоє завдання на цьому етапі це зібрати функціональні та нефункціональні вимоги.
Наприклад
Функціональні вимоги:
Постити твіти
Читати твіти
На цьому функціональні вимоги не закінчуються потрібно дізнатися скільки постів буде робити людина в день, яка кількість активних користувачів, який розмір твіта, як довго потрібно зберігати твіти?
Нефукціональні вимоги:
Доступність або консистентність? Я думаю ти здогадався що в цьому випадку краще мати високу доступність а ніж консистентність. Нічого страшного якщо Іван отримає твіт через 5 хвилин а Сергій через 5 секунд.
Продуктивність - яка має бути API latency?
Масштабованість - скількох активних юзерів має підтримувати система?
Надійність - тут можна запитати про репліку, підтримка failover короче наш SLA
Коли ти це все зібрав можна зробити оцінку та почати малювати схему.
4. Типові помилки на інтерв’ю
1. ⚠️ Зібрав вимоги — і забув про них
Кандидати часто задають правильні питання: про навантаження, обсяг даних, SLA. Але після цього — жодного використання зібраної інформації.
Наприклад: кандидат питає, скільки буде RPS на читання і на запис. Якщо відповідь: читання — 10k RPS, запис — 100 RPS, то логічно проєктувати окремі entry points, кешування на читання, пріоритетність ресурсів, можливо навіть відмовитися від синхронного запису. Якщо ж ці цифри не використовуються — питання було даремним.
Навіть запит типу: «Який час життя даних?» може дати багато: якщо дані можна видаляти через 30 днів — це знімає частину обов’язків зі зберігання. Якщо можна втрачати дані — можлива агресивніша оптимізація. Ігнорування таких відповідей призводить до архітектури, що не відповідає задачі.
2. 🤯 Намагання зробити все і одразу
Стрибки від теми до теми, надмірне говоріння, відсутність структури. Без чіткого плану кандидат "захлинається" в деталях. Тож дотримуйся структури інтерв’ю.
3. 🚀 Розширення меж системи без потреби
Іноді кандидат вирішує: "О, я знаю як зробити ще краще!" — і починає проектувати фічі, про які не йшлося у вимогах. Це розфокусовує. Краще зосередитися на вирішенні поточної задачі, а додаткові ідеї — записати в окремий список «на потім». Це дозволяє показати широту мислення без шкоди глибині рішення.
4. 🚫 2 RPS
Бізнес не завжди потребує гугл-архітектури. Часто — це MVP або модульний моноліт, що росте поступово. Якщо проектувати систему одразу як "мільярдний" продукт — це показує нерозуміння еволюційної природи систем.
5. 🤔 Цитування книжок без розуміння
Фрази типу: "використаємо консистентне хешування" — але без здатності пояснити, як воно працює. Оперуй знаннями якими володієш.
6. ❌ Втрата даних між системами
Якщо сервіси спілкуються напряму або черги додані без гарантій — є ризик втратити події. Варто одразу продумати ідентіфікатори, ідемпотентність, логування, підтвердження доставки.
7. 📃 Довгострокове зберігання
Через роки система буде містити архіви, логи, старі записи. Без плану архівації, розділення гарячих/холодних даних — система перестане масштабуватись. Шардування, cold storage, lifecycle policy — необхідні речі.
8. 📁 База даних — для всього
PostgreSQL не має зберігати зображення, обробляти повнотекстовий пошук і ще бути основною OLTP системою. Кожен інструмент має своє призначення. Наприклад: зображення краще зберігати через CDN (S3 + CloudFront), для пошуку використати Elasticsearch або OpenSearch, для черг — Kafka або RabbitMQ. Не зловживати універсальністю — обирайте інструмент за потребою.
9. ⚖️ Абстрактні компоненти
Система наче складається з "сервісів", але де вони будуть запущені? У хмарі? У Kubernetes? Bare metal? Який CI/CD, як деплоїти, які залежності? Інтерв'юер хоче бачити реалізовувану архітектуру.
10. ❗️Тільки технічний моніторинг
Моніторити CPU — це добре. Але користувачу байдуже. Треба бачити кількість твіти, які не дійшли, або час реакції на натискання кнопки. Важливі метрики — продуктові.
11. 🔢 Рішення у лоб
"Так, тут Redis, тут Kafka, тут Postgres, і все працює" — ок. А чому Redis, а не Memcached? Чому Kafka, а не SQS? Відсутність порівнянь і trade-offs — це мінус. Очікується аналітичне мислення, оцінка варіантів.
Підписуйся на мене і ми разом пройдемо еволюцію від цього:
До цього: