Я повертаюсь з серією статей про MLOps, що будуть включати DevOps, DataOps та платформи, які потрібні для оркестрації. Ця стаття, перша з циклу, є прикладом побудови RAG та оптимізації пайплайнів на дуже обмежених ресурсів, та без платних LLM

Як Японія побудувала DevOps
Дуже далеко від України розташована країна інновацій, технічного прогресу та педантичності. З давніх давен педантичність японців вшоновувалась та допомагала робити неможливі речі - можливими: ідеальні тротуари, традиційна архітектура, на основі якої будуються сучасні будинки, здатні витримувати сильні землетруси, та уважність до, здавалось, незначних деталей.

Це все уособлює слово Kaizen: постійне вдосконалення замість радикальної миттєвої зміни. Мені імпонує це як і філософія життя, але з нею виросло те, що сьогодні відомо як CI/CD/CO - continuous integration, delivery, operation. Три кити, на яких будується кожна стійка система.
CI (Continuous Integration):Ресторани з зіркою Мішлен мають неймовірну якість та швидкість. Як цього можна досягти в кулінарії, де на готову страву впливають мільйони чинників? Делегація обов’язків. Саме вона дозволяє зрозуміти межі обов’язків кожного кухаря. Перший може займатись тістом, другий соусами, третій підготовкою продуктів. Кожен з них підлаштовується під те, що готує інший, щоб в кінці отримати ідеальний баланс - вони інтегруються в роботу один одного, щоб при помилці не подати страву з занадто водянистим соусом, але при цьому вони і не перетинають межі роботи один одного - в цьому є основна ідея CI.
В розробці автоматизація відповідає за впровадження змін кожен раз при push чи pull request. CI не зупиняється ні на мить, як безкінечний цикл.
Типовий CI виглядає десь так:
Push/ Pull запускають
Git Actions, який запускає тестовий скрипт, що
створює артефакти (результати тестування, бінарні файли або docker image
CD (Continuous Delivery): Страва готова, її можна передати офіціанту, який донесе страву до клієнта, але тільки після перевірки. Офіціант буде повертатись на кухню кожен раз, коли потрібно буде нести перевірену страву до клієнта, це - CD. Якщо CI пройшов успішно, на стадії CD зміни інтегруються у продакшен версію коду.
CO (Continuous Operation): В ресторані зламалась плита, замість повного закриття кухарі швидко замінять її на іншу, можливо портативну, клієнти навіть не будуть знати, що сталось. Новий продакшн код працює, але про застосунок дізнались дуже дуже багато людей і контейнер, в якому працював застосунок з грохотом рухнув, користувачі більше не мають доступ і компанія за хвилини втрачає тисячі. Або ж, компанія може зробити декілька реплік застосунку: якщо один контейнер падає, створюється інший, або якщо великий наплив користувачів - розгортаються одразу 3 контейнера у різних зонах.
Ці три елементи не дають миттєвого результату, але вони дають стабільність: виправляти маленькі баги легше зараз, та і вони, скоріш за все, не зруйнують всю систему.
Як працює RAG
Я не буду вдаватись у подробиці того, як працюють трансформери та attention моделі, які є в основі LLM, тут я розповім саме про RAG та його підводні камені.
Більшість компаній мають гігабайти документації (яку мало хто читає) і ось, в один прекрасний день, вам треба знайти, що ж це за RobustScrinningFromThatOneMethod(). Назва неймовірно описова, одразу викликає головний біль та передчуття риття в документації та пальці, зажаті на CTRL + F. За цим незрозумілим методом тягнеться десятки інших, які потрібно прочитати. А що, якщо б LLM могла дати розгорнуту відповідь та ще й включити всі пов’язані методи, але так, щоб секрети компанії залишались недоступними для не сторонніх? Це і є RAG - система з LLM, яка має базу даних, але яка є локальною та захищеною, дуже грубо кажучи - це дуже швидкий пошук та суммаризація документів.
В основі RAG є 3 основних компонента: векторне сховище, де зберігаються дані, метод знаходження потрібних даних та сама LLM.
Навіщо потрібне векторне сховище та чому не можна використовувати звичайну бд.
Всі моделі машинного навчання, будь то LLM або моделі для передбачення цін на акції, працюють на математиці - вони не можуть розуміти людський побут та мову так, як розуміє людина. Моделі можуть тільки імітувати результат через вірогідність. Тому, щоб LLM працювала, потрібно дати закодовані документи, оскільки LLM мають в основі трансфоромери або attention моделі, кодування - це вектори. Чому саме вектори, бо вектори дають величезний спектр методів для роботи та обробки текстів, окрім того, що такі мови як Python оптимізовані для дій з векторами та матрицями.
Короткий екскурс у прекрасний світ векторів
Які є способи, щоб перевести текст у числову послідовність? Можливо кожне слово - це порядковий номер, або закодувати в бінарний код? З цього і починалась обробка тексту ще в 1970х, але семантичної користі доволі мало. То як же навчити модель “розуміти”, що яблуко та людина мають мало що схоже? На цьому етапі і зародилась ідея vector embeddings - nD матриць, в яких схожі слова розташовані близько. Але як порахувати схожість слів, тим паче, що чим більше вимірність, тим швидше постукає прокляття багатовимірності, коли дистанцію між словами неможливо порахувати - вона стає однаковою. Один зі способів знайти відстань, методи як cosine similarity - знаходження найменшої дистанції між словами через косинус.
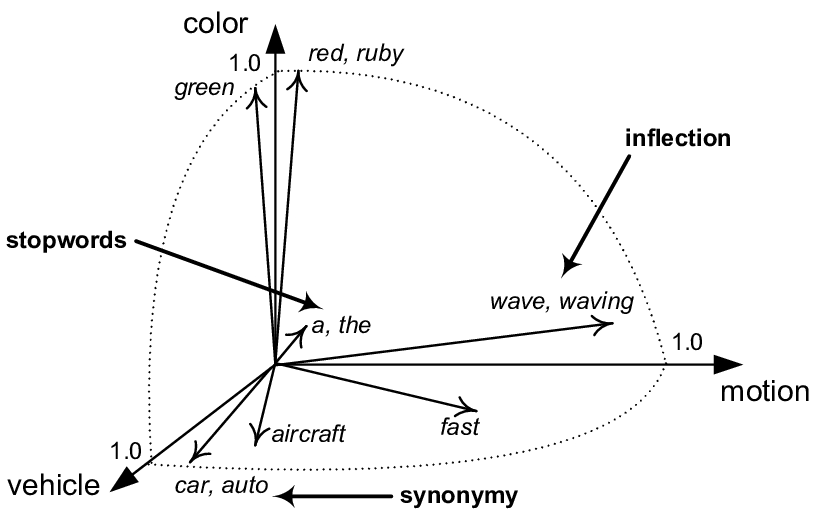
Чим менша відстань між словами, тим вони ближче семантично. Ембеддінги не створюються вручну, а навчаються на терабайтах даних, які можуть бути неетичними, сесксистськими, тощо. Виправлення ембеддінгів є також дуже важливою частиною, яку не можна пропускати, та намагатись через промпти виправити не дані, а модель.
Multimodal RAG
Стандартний RAG працює тільки з текстовими даними, плюс такої системи в швидкості і дешевізні: для текстового або ж звичайного RAG можна використовувати моделі з меншою кількістю параметрів, які використовують менше токенів та не потребують потужної VM. Але тільки текст часто недостатній, потрібно бачити інструкцію або архітектуру (медіафайли). Мультимодальні системи можуть обробляти як медіа, так і текст, вони більш дорогі та потребують набагато потужнішої VM та більше токенів, але як і звичайний RAG їх можна оптимізувати.
Три священні кити RAG
RAG складається з 3 частин: LLM, retriever (vector db), reranker. Найпростіше принцип роботи можна пояснити на прикладі бібліотеки (дуже умовної): retriever - автоматичний пошук книг за словами та термінами, бібліотекар (reranker) обирає книги, які найбільш семантично підходять за запитом, LLM робить короткий опис вмісту всіх знайдених бібліотекарем книжок. Золотим стандартом у побудові RAG є використання Two-Stage Retrieval pattern: retriever+reranker, для спрощення можна використовувати і тільки retriever, якість системи може бути хорошою тільки якщо працює з дуже чіткою документацією, де пошук за словами достатній, без семантичного навантаження.
Retriever - грубо кажучи, пошук за словами. Запит від користувача векторизується та порівнюється з вже наявними векторами у базі (документацією наприклад). Найчастіше використовують cosine similarity для знаходження відстані між словами - їх схожості.
Плюси: retriever дуже швидкий, в його основі cosine similarity, не дуже складна математична операція, яка не потребує багато ресурсів.
Мінуси: пошук за словами може знаходити синоніми слів, але не самі слова - терміни часто губляться, результат погано відповідає на питання користувача. Пошук за термінами через спарс - вектори (BM25) робить пошук більш точним, але retriever все ще не має основного - семантичного сенсу.
Reranker - семантичний сенс через cross - encoders (BERT). Retriever знаходить n- кількість векторів, reranker обирає з них ті, що “відповідають” на питання. Такі системи набагато повільніші, але прибирають непотрібне сміття, яке дає retriever.
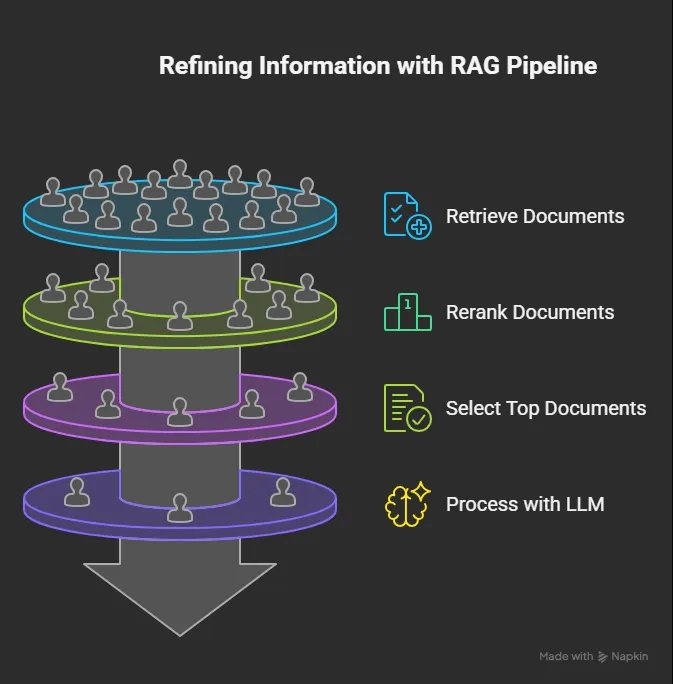
Архітектура RAG
Як будувала Multimodal RAG
Цей проект є фінальним проектом курсу від Softserve, який дуже раджу. Я розбила проект на 6 основних частини: data scrapping, RAG engine, monitoring, dashboard, Qdrant, API. Модальність коду як свята святих - кожен модуль фізично не залежить від іншого: помилка одного модулю не має ламати всю систему. Це виглядає не дуже важливим на етапі проектування, але стає головною біллю на продакшені.
Що повинен повертати RAG:
суммаризацію знайдених статей
релевантні медіа та фільтрація лого - вони несуть 0 сенс і тільки перевантажують систему
посилання на статті, які використані для суммаризації
Я покладаюсь на data - driven підхід: якість даних важливіша за якість моделі, навіть GPT 4 буде погано працювати на поганих даних.
Коротко про кожен модуль:
Data scrapping (data_processing/mapping.py) - pain in the a**, збирання та обробка даних. Скраппінг через теги в <div>: текст та медіа зі статті. У створеній у Qdrant колекції завантажуються векторизовані артефакти статті, всі зображення зменшуються для оптимізації пайплайнів. Це один з важливіших пунктів для оптимізації, тому про нього розповім детальніше нижче.
RAG engine(src/engine/rag_engine.py) - мозок системи, тут живе LLM (LLAMA 4 via Groq), Retriever(Qdrant), reranker (Cross - encoder).
API (api.py) via FastApi - з’єднує RAG, моніторінг та БД з оцінками попередніх промптів . Як і RAG, api також асинхронне, оскільки мені потрібно мати основний (виклик RAG_engine для генерації) та бекграунд (audit для оцінки генерації) процеси.
Dashboard(dashboard.py). UI трекер метрик, зроблений через Streamlit.
Monitoring(metrics.py). Перевіряє якість генерації одразу. Значення метрик записують у БД, до якої має доступ dashboard.
Повну діаграму можна подивитись тут.
Щоб розсередити навантаження використовую 2 моделі:
LLAMA 4 - це мультимодальна модель, генерує сумаризацію на основі промпту та опис зображень. Запускати таку модель локально було б невдячною справою, тому використовую токени від Groq, це безкоштовний аналог GPT, але підходить тільки для проектів без великого навантаження.
qwen2.5:1.5b - це текстова генераційна модель, також від Ollama. Маленька, але швидка та якісна, ідеально підходить для генерації варіацій промпту користувача. Завантажувала локально та запускала через ollama serve. Це не дуже хороший підхід для великих систем, але з обмеженими ресурсами, як в мене, працює дуже добре.
Воркфлоу виглядає так:
class MultimodalRAG - тут живе мозок, спочатку перевіряється, чи було є в кеші такий самий промпт (методи async def _ensure_cache_exist() та async def get_semantic_cache()), якщо так, то повертається вже згенерована раніше відповідь з колекції llm_cache, якщо ж ні, то починається повний цикл генераціЇ:
vector_results = await asyncio.gather(*[self.get_all_vecs(q) for q in queries]) генерується 3 схожих питання до питання користувача - query expansion на локальній моделі qwen.
Retriever results = await self.client.query_points шукає 20 векторів з qdrant колекції
Reranker “оцінює” знайдені вектори: scores = await asyncio.to_thread(self.reranker.predict, pairs)
В parents_results фетчиться id знайдених векторів з payload (це heavy lifter, де знаходяться всі артефакти статті) parent_results = await asyncio.gather(*fetch_tasks)
Далі parents_results розділяється на: parent_doc (текст статті, посилання та тайтл), images_and_descriptions - згенерований опис до медіа та саме медіа, тут же фільтрується від логотипів.
Далі йдуть два кола до LLM: базова генерація на основі комбінованого тексту з parent_doc та медіа з images_and_descriptions - ця генерація може бути неточною або містити непотрібну інформацію, тому вона є основою для judge генерація, яка є фінальною генерація.
Повторне генерування, якщо метрики погані - refine_answer(). Користувач отримує перший результат(final result), запускається процес перевірки якості через стандартні LLM метрики (AnswerRelevancy,ContextUtilization, Faithfulness), якщо Faithfulness менше заданої норми, результат регенерується.
Повну діаграму можна подивитись тут.
Проблема потоків та Semaphore
Як і з RAG виникає проблема перерваних потоків, щоб їх не було використовую @asynccontextmanager разом з global gpu_semaphore як lifespan:
app = FastAPI(title="Oracle RAG WebSocket API", lifespan=lifespan)async def audit_and_push_correction(question, initial_result, websocket) запускає Evaluator з metrics.py для оцінки генерації. Цей процес на бекграунді, тобто користувач отримує згенеровану відповідь, після чого запускається її оцінка. Я перевіряю тільки faithfulness - це хороша метрика, вона одна не є дуже показовою, якщо RAG повинен згенерувати відповідь з технічно конкретною, наприклад медичною інформацією, але для малих систем її достатньо. Якщо faithfulness <0.7 викликається refine_answer() з RAG_engine для повторної генерації. Для judge обрала локальний qwen, той самий, що генерує варіації промпту.
async def websocket_endpoint(websocket: WebSocket) - головний процес, викликає await engine.run_hybrid_rag(). Я приділила велику увагу для перевірки результату, отриманого від RAG, користувачу потрібно розуміти, що система працює, навіть якщо тимчасово стався збій:
Якщо результат пустий або містить ⚠️ : "System is currently overloaded. Please try a shorter question.". Користувач розуміє, що система не працює зараз, але можна ввести новий промпт через якийсь час.
Якщо confidence_score <0.2: reranker не знайшов підходящі вектори, тобто Qdrant не має векторів по темі: "answer": "I cannot answer this. It seems outside my current knowledge base." Користувач скоріш за все перефразує промпт, а не піде.
Також, по класиці, якщо користувач ввів просто привітання, можливо помилково натисну ввід без повного промпту, API не викликає генерацію і просто вітається.
System monitoring
Monitoring(src/monitoring/metrics.py)
Як і в кожній системі, оцінка результативності займає далеко не останнє місце. Діаграму можна подивитись тут.
Основні труднощі для мене - це знайти метрики, які не використовують GPT як judge моделі, оскільки для цього потрібен токен, та, звичайно, швидкість оцінки. Основні метрики: AnswerRelevancy, ContextUtilization, Faithfulness з Ragas, одна з найкращих бібліотек по кількості метрик.
Деякі метрики, як ContextPrecision потребують референсного значення, з якими порівнюється згенерована відповідь, гарна метрика для тестування, але не для продакшену - генерувати це референсне значення було б занадто затратно, тому використовую її різновид, який не потребує референса - ContextUtilization.
1.RAGAS
Faithfulness: лакмусовий папірець галюцинацій. Порівнює відповідь із контекстом і визначає, чи всі твердження у відповіді підкріплені джерелами. (Низький бал = галюцинації).
Answer Relevancy: релевантність. Визначає, наскільки точно відповідь стосується промпту. Ігнорує джерела і фокусується лише на тому, чи отримав користувач те, що запитав.
Context Utilization: Оцінює якість пошуку (retrieval). Показує, наскільки ефективно модель використала знайдену інформацію для формування відповіді.
2. Лінгвістичні та NER метрики (NLP & InterpretEval)
Математичний аналіз тексту та перевірка іменованих сутностей (імена, дати). У деяких бібліотеках ці метрики використовують разом з GPT, тому для них потрібен токен.
BLEU Score: класична метрика, що вимірює текстову схожість між контекстом та відповіддю. Чим більше однакових послідовностей слів, тим вищий бал.
ROUGE-L: оцінює найдовшу спільну послідовність слів. Корисна для перевірки того, чи зберегла модель структуру та головну думку з context.
NER Coverage: відсоток важливих назв, дат та цифр із контексту, які потрапили у відповідь. (Високий бал = висока деталізація).
NER Hallucination: виявляє "вигадані" власні назви або цифри, яких не було в оригінальному тексті.
NER Density: співвідношення кількості фактів (сутностей) до загальної кількості слів. Показує, наскільки "насиченою" фактами є відповідь.
3. Логічна відповідність (FactCC)
Salesforce використовує GPT для аналізу послідовності відповідей, тому я зробила аналог цієї метрики, але з локлальною qwen моделлю.
FactCC Consistency: перевірка на критичні помилки:
Підміна об'єктів (наприклад, переплутані назви компаній).
Числові помилки (неправильні ціни чи дати).
Помилки заперечення (коли джерело каже "так", а модель - "ні").
4. Безпека та етика (RAI Harm)
Метрики відповідального ШІ (Microsoft RAI). Для якого проекту не потрібен був би RAG, хоч для пошуку товарів на сайті, сумаризації документації для холодильників - не можна забувати, що LLM вчиться на величезному об’ємі даних, частина яких може бути небезпечною для людини, безпека користувача не повинна бути як додатковий бонус.
Harm Score: оцінка генерації від 0 до 1, де 0 — безпечно, а 1 — небезпечно. ШІ аналізує текст на наявність:
Мови ворожнечі (Hate Speech).
Пропаганди насильства (Violence).
Схиляння до самокаліцтва (Self-harm).
Harm Category: вказує конкретну категорію порушення, якщо harm_score високий.
Всі метрики записуються до БД evaluation_logs (src/monitoring_db)
Розгортання RAG та Vector Storage
Тепер перейду до більш конкретних деталей, я буду використовувати MultimodalRAG проект як основний та NotionRAG як фан - проект. В цій статті не буду конкретно розповідати про Docker, скажу тільки, що скоро буде стаття його повного розбору.
Існує багато векторних сховищ та двигунів, найбільш мені особисто подобається Qdrant: легко розгортається, є веб інтерфейс, можна аналізувати та перевіряти вектори. У багатьох початкових туторіалах замість Qdrant локальне сховище FAISS, але воно повільніше та не має всього того, що має Qdrant, але обидва повністю безкоштовні.
Qdrant є мультимодальним сховищем, може зберігати текст та медіафайли. У фан проекті я векторизувала власні Notion помітки у локальний Qdrant, це хороший спосіб розпочати вивчення векторних сховищ з малими даними. Професійний підхід - це розгортання сховища на контейнері як сервіс, який потім можна оркеструвати або розгорнути через aws чи gcp.
Я розгортала qdrant на докер контейнері, але допустила неприємну помилку. Під час тестування створила створила окремий контейнер, а не compose stuck, через що довелося імпортувати вектори до qdrant контейнера вже в compose stuck, це можна зробити через
curl -X POST "http://localhost:6333/collections/{collection_name}/snapshots/recover" \
-H "Content-Type: application/json" \
--data '{"location": "http://url-to-your-snapshot-file"}'В залежності від розміру даних та типу диску може зайняти дуже багато часу.
ETL: обробка та підготовка даних
Способів безліч і вони в більшості залежать від платформи, наприклад у Notion є api, яке дає стороннім сервісам доступ до вибраних файлів, хадкорний метод - це data scrapping, що я і робила.
Scrape. Для RAG потрібно зібрати: основний текст статті, заголовок, медіа та її опис. У Batch доволі складна верстка: 9 категорій статей з різною системою побудову, багато медіа не має опису, тому його потрібно генерувати також.
Extract. BeautifulSoup та Regex для збирання та очистки від метаданих (get_content(), get_article_links()).
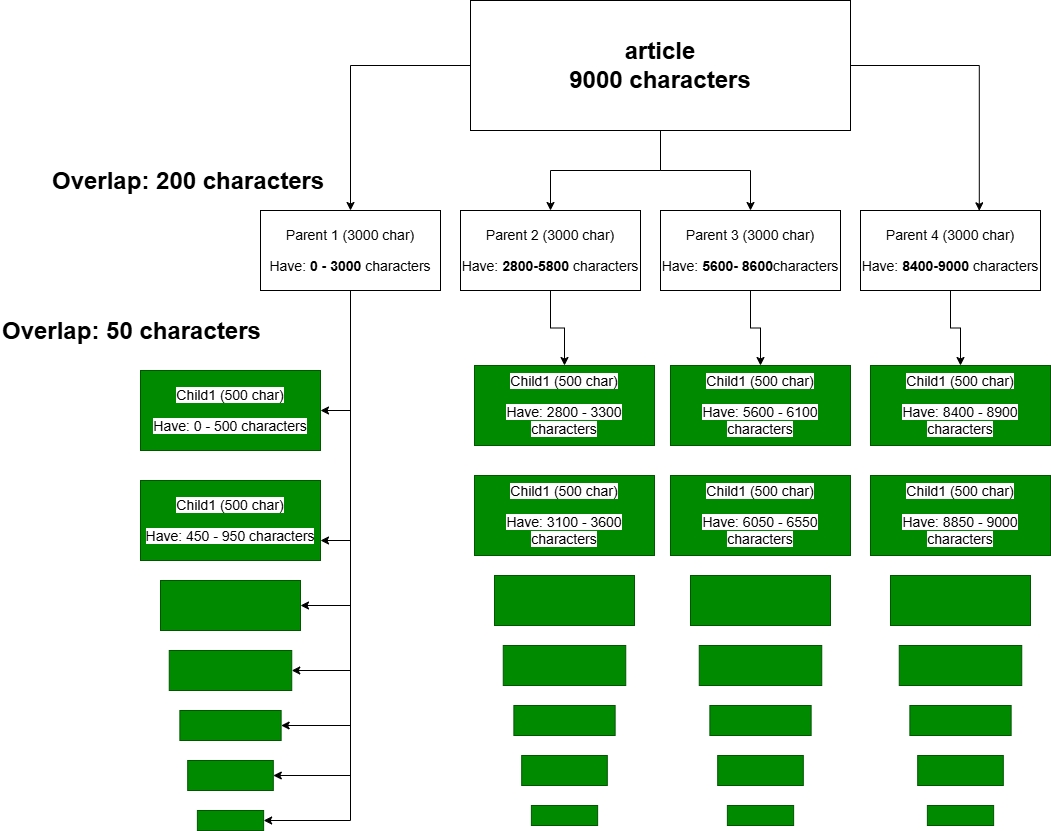
Splitting через RecursiveCharacterTextSplitter. Розділення на child та parent колекції має три підводних каменя: чи розділяти текст, як розділяти, скільки перекриття (overlap).
Це є вибором між ефективністю та контекстом: одна стаття розділена на великі шматки (parent), які розділені на менші шматочки (child) - оптимізований пошук, але потрібно очищати від дублікатів, або parent буде цілою статтею, яка розділена на маленькі (child) шматки для пошуку, це дасть більший контекст для LLM, але повільну та дорогу систему. Я обрала перший підхід, оскільки контекст можна зберегти через overlap батьківських шматків, разом з тим зберегти і швидкість. Тепер детальніше про overlap. Розділення тексту за кількістю символів призводить до втрату сенсу речення, тобто LLM може помилитись. Щоб уникнути такого використовують overlap - буферний текст, кінець одного шматка тексту - це початок іншого. Дах, який складається з накладених плит міцніший за той, де плит покладені поряд.
Весь код для scrapping можна розділити на 4 частини:
Scrapping. Пошук потрібних статей
Resize. Зменшення зображення щоб зекономити токени та пам’ять.
Embed. Векторизація тексту та зображення.
Upsert. Завантаження до відповідної колекції Qdrant.
Data engineering
Small-to-Big (Child-to-Parent)
Якщо уявити дані у вигляді датасету, то це буде один стовпець з 5 артефактами для кожної статті:
payload={
"full_text": p_text,
"image_b64": img_b64,
"headline": headline,
"url": article_url,
"type": name
}По такому стовбцю важко буде шукати, тим паче робити це швидко. Вихід - розділити стовпець на 5 окремих. Основна проблема: пошук по всьому тексту довгий - залишається. Логічно було б припустити, що якщо розділити full_text на частинки по 100 символів, пошук пришвидшиться - це Small-to-Big expansion.
Small (також називають child) містить id big (parent) елементу та частинку full_text. Пошук векторів ведеться саме по small колекції, а як content до LLM потрапляє вже big (parent) колекція.
Наприклад:
Parent Chunk 1 (Chars 0-3000): ID: AAA. Всі діти зсилаються на ААА.
Parent Chunk 2 (Chars 2800-5800): ID: BBB. Всі діти зсилаються на BBB.
Parent Chunk 3 (Chars 5600-8600): ID: CCC. Всі діти зсилаються на CCC.
Parent Chunk 4 (Chars 8600 - 9000): ID: DDD. Всі діти зсилаються на DDD.
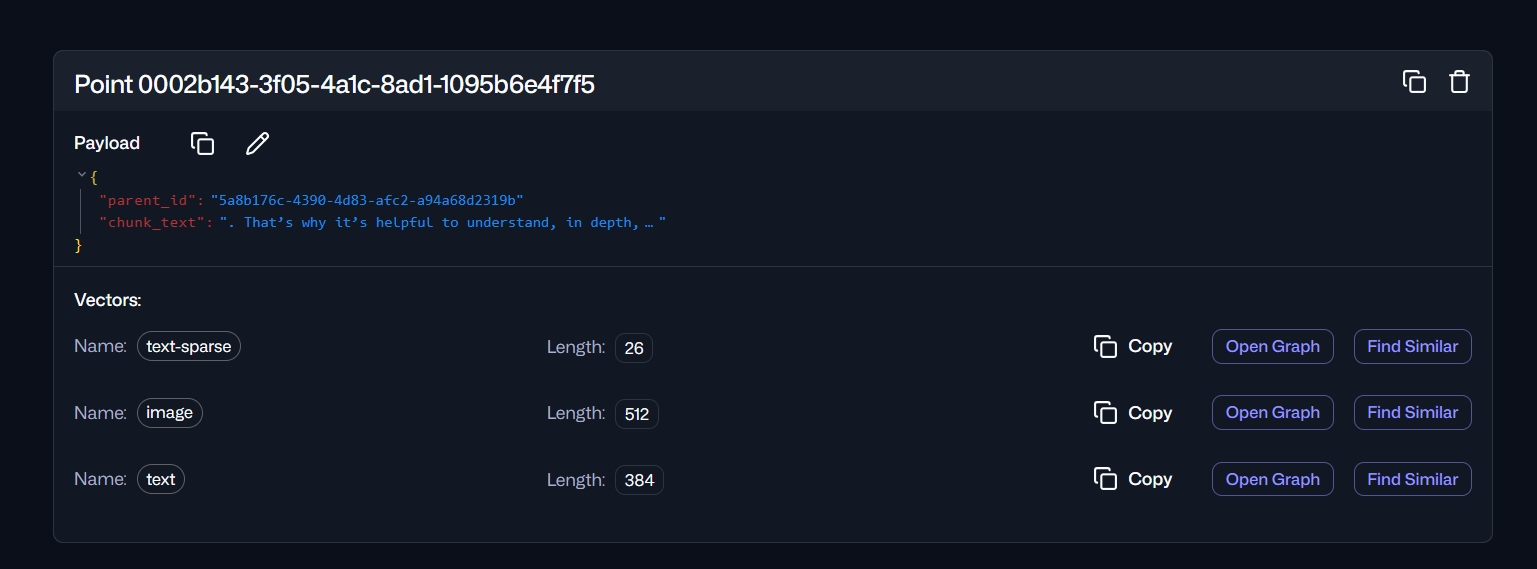
Зменшення та векторизація зображення
LLM не потрібне високоякісне зображення, але високоякісне зображення може займати 50к токенів, що дуже сильно впливає на час обробки промпту. У _process_and_resize_image() зменшую до 128х128 та створюю два різних типа зображень:
v_image векторизоване через self.vision_model.encode. Це зображення подається як частина context для моделі, також Qdrant може математично зрозуміти, що на зображенні та використовувати для пошуку.
img_b64 - це зображення, яке конвертоване у string для оптимізації, оскільки якщо векторизувати, то повернути назад у звичну для людини форму вже не вийде. Саме це зображення бачить користувач.
Prompt Engineering - як підняти якість моделі
Без правильної команди жодна техніка не буде працювати, для LLM такі команди - це промпти. Якщо LLM буде отримувати промпти напряму від користувача, відповідь може буде згенерована, але без важливих уточнень.
Prompt engineering піднімає якість генерації через:
Детермінізм (Reliability): моделі за своєю природою стохастичні. Prompt engineering (через техніки Few-Shot або Chain-of-Thought) мінімізує дисперсію відповідей.
Вартість та Latency (Efficiency): чим краще спроектований промпт, тим менше токенів витрачається на спробу “вгадати”, що хоче користувач. Це напряму впливає на кількість витрачених токенів.
Безпека (Prompt Injection): правильно побудований системний промпт — це перший рівень захисту від спроб користувача змусити модель ігнорувати інструкції: злити API або особисту інформацію.
Системний промпт, тобто доповнений промпт від користувача, який подається на моделі має таку архітектуру:
"system", "Roles of LLM and rules of generation"
{context} #from vector DB
[USER REQUEST]: {question}
[USER REQUEST]: {question}
Кожна LLM має Context Window - “пам’ять“ про діалог, дуже часто це вікно урізає промпт від користувача, через що результат генерації поганий. Я використовую Prompt Repetition методику, яка в цьому дослідженні показала хороші результати.
Надважливо не передавати до системного промпту зайву інформації:
Не передавати медіафайли.
Не передавати повну history, тільки останні n токенів, наприклад 1000.
Оскільки використовую подвійну генерацію, мені потрібно два промпти: перший для першої, базової генерації, другий для judge:
base_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are an expert AI Researcher. Use the provided context to answer the question. If the context contains multiple viewpoints or multifaceted information, synthesize them into a single coherent answer. Do not contradict previous statements within the same response. If information is missing, state what is known and what is not .
STRICT OPERATING RULES:
1. NO REDUNDANCY: Do not create separate 'Summary' and 'Details' sections. Merge all information into one unified list.
2. TOTAL COVERAGE: You must briefly address EVERY news item found in the context (including editorial notes or milestones mentioned).
3. ZERO FILLER: Start immediately with facts. Do not say "The articles discuss..."
4. NO HALLUCINATION: If a detail isn't in the context, do not mention it.
5. NO DISCLAIMERS: Do not end with apologies or statements about missing info.
6. NO SEPARATORS: dont add * as separator.
7. NO WRAP-UP: Do not conclude with 'Overall...' or 'In summary...'
""",
),
MessagesPlaceholder(variable_name="history"),
(
"human",
"""[NEWS SEGMENTS]:
---
{context}
---
[USER REQUEST]: {question}
[USER REQUEST]: {question}
Provide the report in bullet points below:""",
),
],
)
critique_chain = ChatPromptTemplate.from_template("""
### ROLE: Expert Technical Editor & Verifier. Your goal is to analyse {answer}.
If the provided context does not contain a direct answer, use the most relevant milestones or news items provided to give a high-level update instead of stating you don't have the info. Do not contradict previous statements within the same response. If information is missing, state what is known and what is not. If the provided context does not contain the answer to the question, state clearly that you do not have that information. Do not mention other unrelated topics from the context unless they directly answer the user's query.
### STRICT INSTRUCTIONS:
1. NO INTROS/OUTROS: Start directly with the first bullet point. Remove "Here is the report," "The articles discuss," and "Note:".
2. ATOMIC SYNTHESIS: Merge identical news items. If two bullets discuss the same startup or model, combine them into one dense sentence.
3. THE GROUNDING RULE: For every statement in the 'Proposed Summary', verify it against the 'Context'.
- If a detail is NOT in the context, DELETE it immediately.
- Do not use outside knowledge (e.g., don't add info about GPT-5 if it's not in the text).
4. DENSITY: Use Bold Headers followed by one clear sentence.
5. NO REPETITION: Ensure no two bullets say the same thing using different words.
6. NO SEPARATORS: dont add * as separator.
7. NO WRAP-UP: Do not conclude with 'Overall...' or 'In summary...'
Context: {context}
Original Question: {question}
Original Question: {question}
Proposed Summary: {answer}
### FINAL DENSE REPORT (NO ASTERISKS):
""")Docker containers
Один контейнер для всього застосунку, або окремий контейнер для кожного модуля, де зробити entrypoint, один dockerfile для всіх контейнерів, чи окремий для кожного, slim або distroless? Docker є базою, трьома китами, коректне використання дає портативність, некоректне - нічний кошмар.
Перш за все, основа основ - dockerfile, інструкція для побудови кожного контейнера. Two stage building є золотим стандартом хорошого dockerfile: легкі, захищені та ефективні docker image через розділення environment та runtime environment
1 стадія (heavy lifter): завантаження самих важких бібліотек, requirements.
2 стадія (light): копіює 1 стадію, завантажує легші бібліотеки та створює entrypoint.
# --- STAGE 1: Builder ---
FROM python:3.11-slim as builder
LABEL authors="AnnacKK"
WORKDIR /app
ENV PATH="/root/.local/bin:${PATH}"
# Install build essentials for heavy ML libraries like sentence-transformers
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
gcc \
libmagic1 \
&& rm -rf /var/lib/apt/lists/*
#copy requirements
COPY requirements.txt .
RUN pip install --user --no-cache-dir \
--default-timeout=100 \
--retries 5 \
-r requirements.txt
# --- STAGE 2: Final Image ---
FROM python:3.11-slim
LABEL authors="AnnacKK"
WORKDIR /app
# Install system dependencies for OpenCV and Vision tasks (required by Moondream/Llama logic)
RUN apt-get update && apt-get install -y --no-install-recommends \
libgl1 \
libglib2.0-0 \
libmagic1 \
&& rm -rf /var/lib/apt/lists/*
# Copy installed libraries
COPY --from=builder /root/.local /root/.local
RUN mkdir -p /app/entrypoint
COPY entrypoint/entrypoint.sh /app/entrypoint/entrypoint.sh
RUN chmod +x /app/entrypoint/entrypoint.sh
# Copy project structure
COPY . .
# Environment setup
ENV PATH=/root/.local/bin:$PATH
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONPATH=/app
ENV OLLAMA_BASE_URL="http://host.docker.internal:11434"
#base port
EXPOSE 8000
#way to reparate one dockertfile for each containers
ENTRYPOINT ["/bin/bash", "/app/entrypoint/entrypoint.sh"]
#this will work only for API, but not Dashboard
#CMD ["uvicorn", "api:app", "--host", "0.0.0.0", "--port", "8000", "--workers", "1"]Кількість dockerfile є частою причиною суперечок. Немає універсальної таблиці, туторіалу, розуміння як краще приходить вже на етапі тестування.
1. Один Dockerfile (Monolithic / Multi-stage)
Плюси:
Простота управління: один файл — одна логіка оновлення залежностей.
Multi-stage Efficiency: можна зібрати додаток в одному image, а потім скопіювати лише готовий бінарний файл у мінімальний образ (Alpine), що робить фінальний результат дуже легким, різниця може бути у десятках ГБ.
Мінуси:
Довга збірка: якщо потрібно змінити лише одну частину коду, Docker може почати перезбирати завеликі частини кешу, який потрібно видаляти або prune.
Складність: один файл на 200+ рядків стає важко читати.
Непотрібність бібліотек: API image може мати непотрібні для нього бібліотеки для RAG, і навпаки.
2. Багато Dockerfiles (Microservices / Component-based)
Кожен сервіс (API, Worker, Frontend, DB) має власний Dockerfile, зазвичай у своїй підпапці.
Плюси:
Швидкість: кожен сервіс збирається незалежно. зміна в одному сервісі не чіпає інший.
Ізоляція: можна використовувати різні базові образи (наприклад, Python 3.12 для ML та Node 20 для UI).
Масштабованість: ідеально для Kubernetes або Docker Swarm, де кожен контейнер має виконувати лише одне завдання.
Мінуси:
Дублювання: доведеться копіювати схожі команди (встановлення, оновлення пакетів) у кожен файл.
Я обрала один dockerfile з 2 entrypoint: для dashboard та api, оскільки в мене dashboard як окремий сервіс, команди для api, наприклад:
CMD ["uvicorn", "api:app", "--host", "0.0.0.0", "--port", "8000", "--workers", "1"]будуть просто класти його і доведеться прописувати окремі входи вже у файлах кластеру, що не дуже хороша практика.
Всі контейнери зв’язані у compose stuck, з яким легше працювати: редагувати, запускати, зупиняти.
Оптимізація image
Чим більше image, тим більшим буде контейнер, тим потужніше VM треба. Оптимізація може звучати як щось складне, але насправді зводиться до одного: додавати до dockerfile тільки те, що необхідне для функціонування контейнера. На практиці це означає створити .dockerignore та внести у нього все, що не повинна бути у контейнері. В моєму випадку це виглядає ось так:
.venv/
__pycache__
.env
src/monitoring_DB/*.db
*.pyc
.git/
.idea/
.vscode/
.documentation/
.tests/
qdrant_storage/Тести, гіт, БД для метрик та qdrant storage, де знаходиться копія векторів будуть “впаюватись“ y docker image та збільшувати розмір, якщо не внести у .dockerignore.
Docker-compose.yml та Docker Watch
Для налаштування кожного контейнера окремо використовується маніфест .yml файл, де задаються параметри кожного контейнера: порти, healtcheck, volumes та залежності. Для стабільної роботи контейнери залежать один від одного, тому дуже важливо налаштувати test - команду для перевірки стану сервісу.
Під час тестування хочеться бачити, як зміни застосовуються одразу, а не перезапускати контейнери. Є багато бібліотек, які можуть відслідковувати зміни в коді, але для докера самим простим та ефективним є Docker Watch, його єдина складність - це налаштування volumes контейнерів так, щоб файли, за якими треба слідкувати були у volumes, але при тому не стали blind. Наприклад, код БД знаходиться у monitoring_db/, там же, де і сама БД, яка мені не потрібна, але при тому мені потрібно бачити зміни у коді одразу. Оскільки .dockerignore працює лише під час збірки образу (docker build), він не має впливу на під час docker run / docker-compose up, а ось volumes якраз мають, на цьому будується overriding.
Феномен overriding volumes
Це не є універсальним костилем для всіх архітектур, але часто працює є необхідним костилем: - /app/.venv (без крапки попереду!!!!), створює Anonymous Volume.Docker монтує поточну папку . у /app. Це зазвичай перекриває все, що було всередині /app в image.
Проблема: якщо є папка .venv, вона "залетить" у контейнер і зламає все, бо бінарні файли Python у віртуальному середовищі не сумісні між Linux та Windows.
Рішення: запис - /app/.venv каже docker: "Візьми папку .venv, яка була створена всередині образу під час pip install, і сховай її від локальної папки розробника". Це захищає внутрішні залежності контейнера від затирання вашими локальними файлами.
Distroless vs slim
Образ (python:3.11-slim) також дуже сильно впливає на розмір image, але також і на захист системи.
Slim - це легкий образ, частіше з Debian або Alpine, має shell та package manager, що дуже зручно, адже через shell можна редагувати, однак редагувати можете не тільки ви.
Більше інструментів входу: образи slim містять apt, sh, bash та curl. Якщо зловмисник проникає в контейнер, ці інструменти допомагають переглядати файлову систему, підвищувати привілеї або завантажувати вірус.
Більше вразливостей (CVE): образи slim містять більше бібліотек та пакетів ОС, вони за своєю суттю мають більше потенційних вразливостей безпеки (CVE) порівняно з мінімальною природою distroless.
Менеджери пакетів: наявність apt або apk в образах slim дозволяє отримати доступ, встановлювати шкідливі пакети для підтримки персистентності.
ІДебаггінг: це зручно для розробки, але наявність оболонок (sh, bash) та інструментів користувача в образах slim порушує принцип найменших привілеїв, тоді як distroless повністю видаляє їх для безпеки.
Тобто, потрібно обирати між високим рівнем безпеки та зручністю.
Компіляція image
Через docker compose up –build запускаєnmcz локальне збирання compose stuck. Як же docker знає, що потрібно зібрати?
Команда: docker compose (compose stuck) vs docker build (один контейнер)
Одне ім’я: docker compose up обирає ім’я папки, якщо вона не задана.
Залежності: depends on вказують, що контейнери пов’язані між собою.
Одна мережа: при збиранні кожного контейнера окремо вони будуть мати власні окремі мережі, тоді як у compose stuck кожен контейнер має спальну мережу.
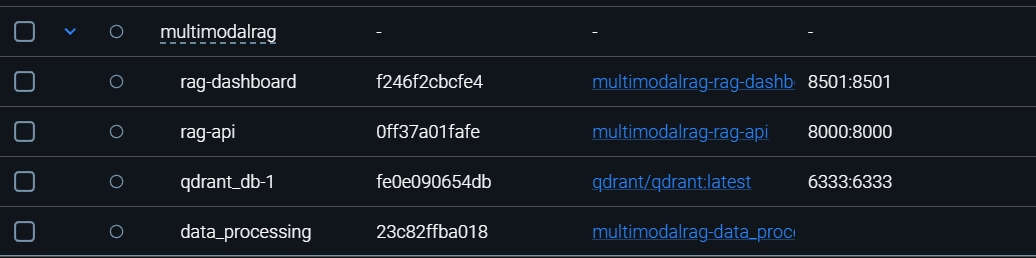
Ось як виглядає мій стек:
K8s або сказання про великого мага
При локальному оркеструванні ви робите всі дії з контейнерами: старт, стоп, рестарт - самі, один контейнер впав, його треба підіймати, що не дуже зручно. K8S (Kubernetes) - це один з найвідоміших оркестраторів, бо краще мати дирижера, ніж грати на всіх інструментах самому одночасно. Звичайно, є випадки коли можна обійтись і без оркестратора, але для мене зручніше продумати архітектуру та зібрати все в одному місці, ніж кастувати мільйон костилів.
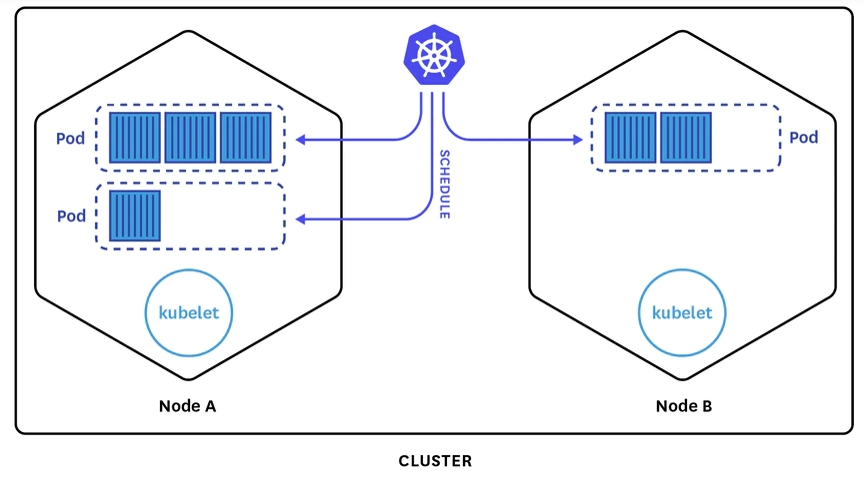
K8S справді доволі складний, якщо вдаватись в подробиці, правильне налаштування покладається на десятки маленьких та, на перший погляд, не дуже потрібних налаштувань.
Швиденько про архітектуру:
Pods: найменші будівні блоки. Кожен контейнер знаходиться у власному поді.
Nodes: керують подами. K8S не є легкою архітектурою і керування всіма подами на одній ноді банально призведе до хаосу, треба розподіляти ресурси в залежності від ролей:
control plane: “мозок”, що управляє подами - регулює стан кластера, розкладом (коли зупинити, тощо) та запитами. Багато пам’яті не потрібно.
workers: там, де все “живе”. Кількість робітників дуже сильно залежить від вимог до застосунку та від VM, бо саме на них хоститься все.
Clusters: кожна окрема нода розташовано у власній VM, кластери “з’єднують” ноду єдину мережу, грубо кажучи, схоже на compose stuck. Кластери управляють load balancing - коли треба створити більше нод, щоб витримати навантаження, або коли можна зменшити їх кількість.
Docker має K8s як у самому застосунку, так і як CLI. Як саме управляти кластерами залежить від вас, але мені зручніше через CLI. Увімикнути можна у застосунку: налаштування - Kubernetes. Docker дає по дефолту 2 види кластерів: kind (кластер може мати декілька нод) та kubeadm (single node).
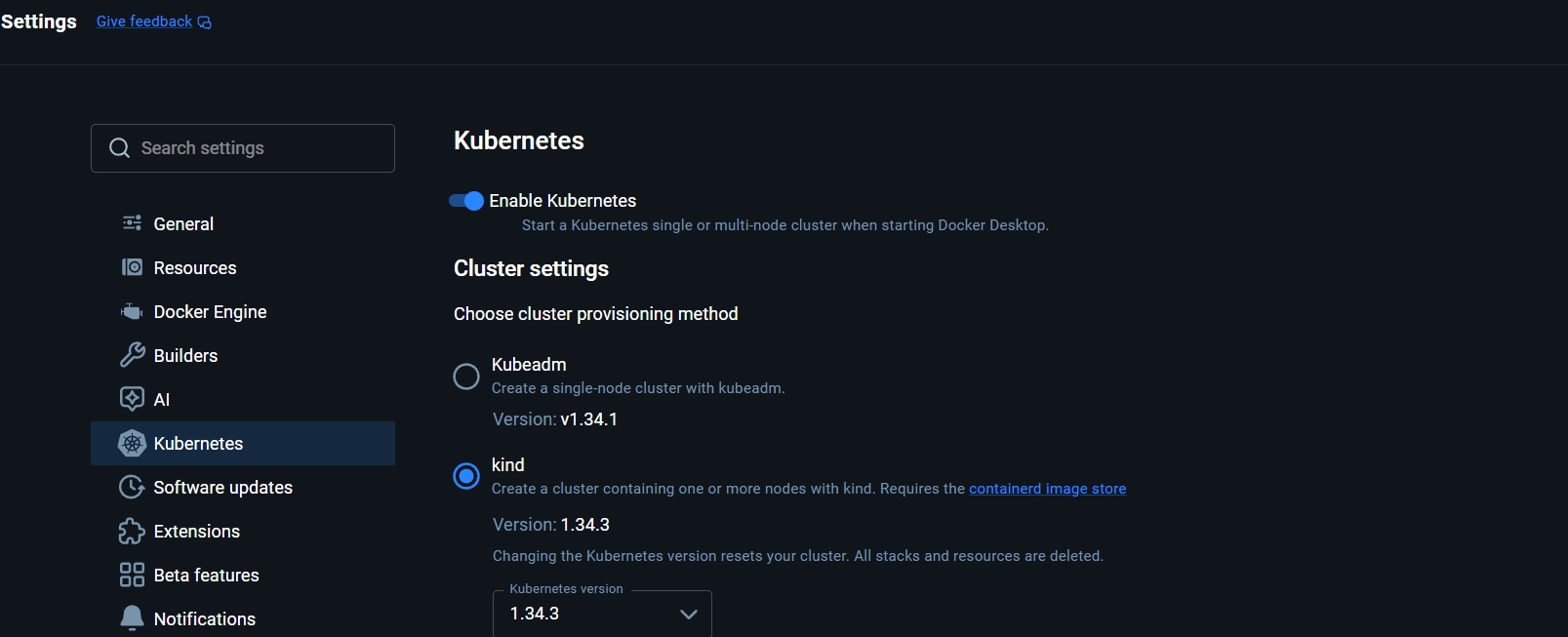
Окрім kind для локального оркестрування також є minikube, він є більш простим для першого знайомства з кластерами, але не дає тої свободи, що дає kind. особливо з CI/CD, тому я буду використовувати саме kind.
Я не буду зупинятись у цей раз на інших видах кластерів, але маю дуже хорошу статтю на цю тему.
Побудова pods: jobs vs service
Контейнер data_processing обробляє дату та завантажує у Qdrant, це не відбувається постійно, бо і не є потрібним, але колекції у Qdrant треба оновлювати, щоб на голову різко не звалилось data drift і RAG не почав розказувати казки. Потрібно знайти часовий проміжок, коли дані, якщо і змінюються, то не сильно. Оскільки контексом для моделі є журнал, який оновлюється пару разів на тиждень, я можу оновлювати колекції один раз на тиждень. Якщо зробити у вигляді сервісу, він буде займати місце і окремою біллю буде його оркеструвати. Саме для таких випадків є jobs - те, що виконується один раз за тригером. Такий підхід називають Scheduled - простий у побудові, але може витрачати ресурси в пусту, якщо дані за тиждень не змінились. Робастним є гібридний підхід: виконання job і по розкладу, і по тригеру. Звичайна job не може виконуватись по розкладу, а от її різновид - cronjob, якраз для цього і створений.
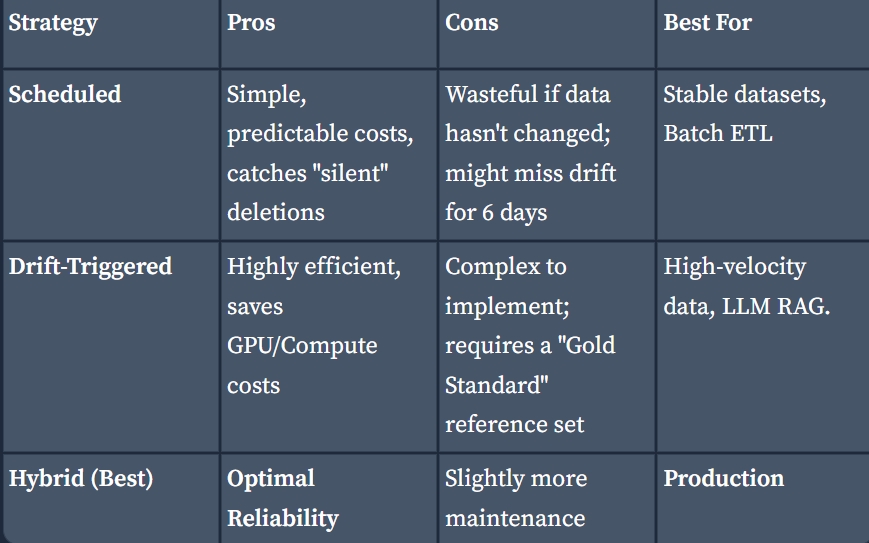
Я обрала наступний підхід:
CronJob (1): запуск data_processing один раз на тиждень по дефолту.
CronJob (2): перевірка на data drift кожен день.
Job: запуск data_processing, якщо помічен data drift, тригером є CronJob (2).
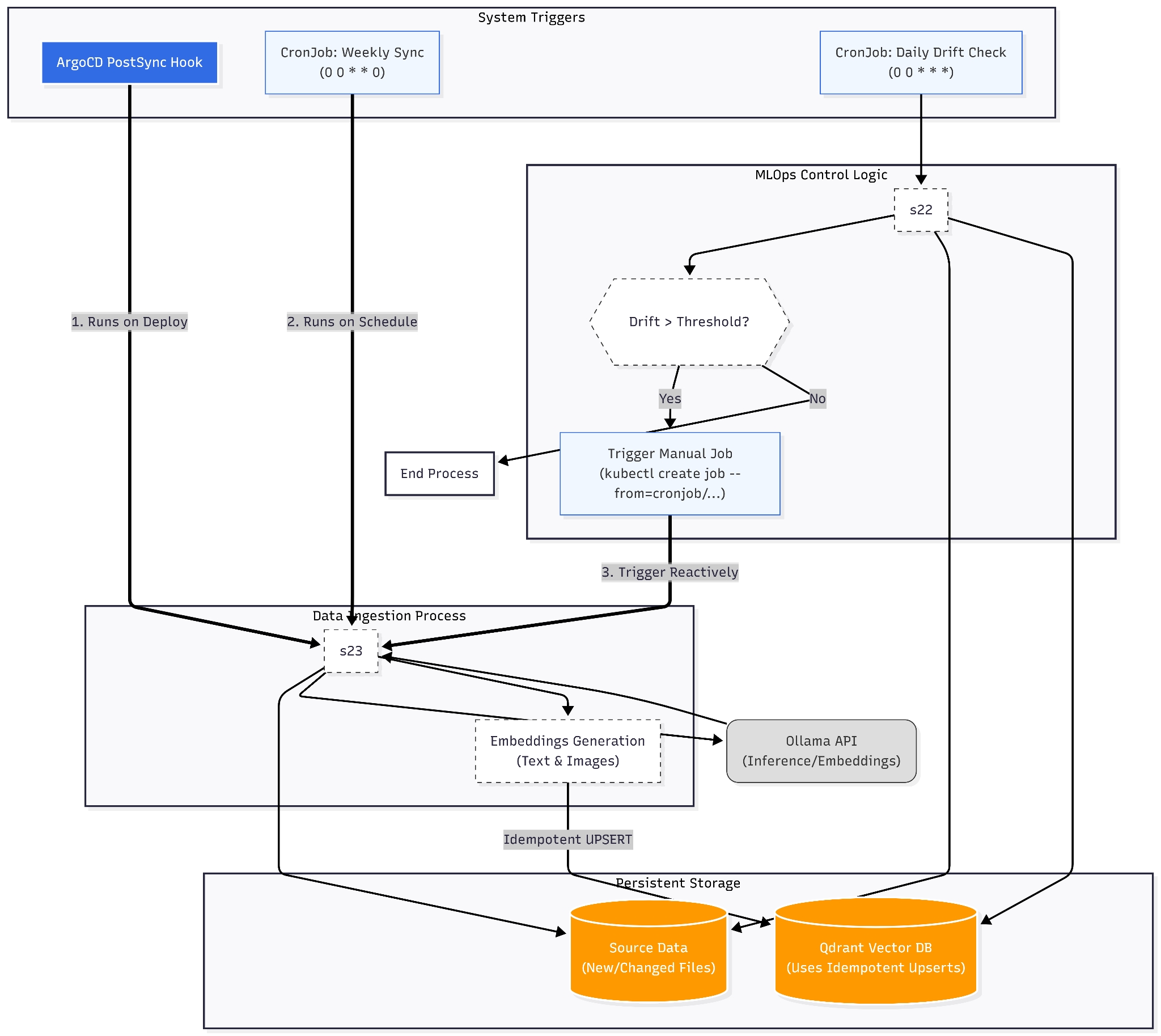
Три основних контейнера: api, dashboard, qdrant - залежать один від одного та повинні бути доступними завжди, тобто, вони повинні бути сервісами. Сервіси можуть знаходить в різних нодах, залежить від того, що вони повинні робити та скільки ресурсів на це треба, якщо у .yml не зазначене це, кластер сам обирає де буде кожен сервіс.
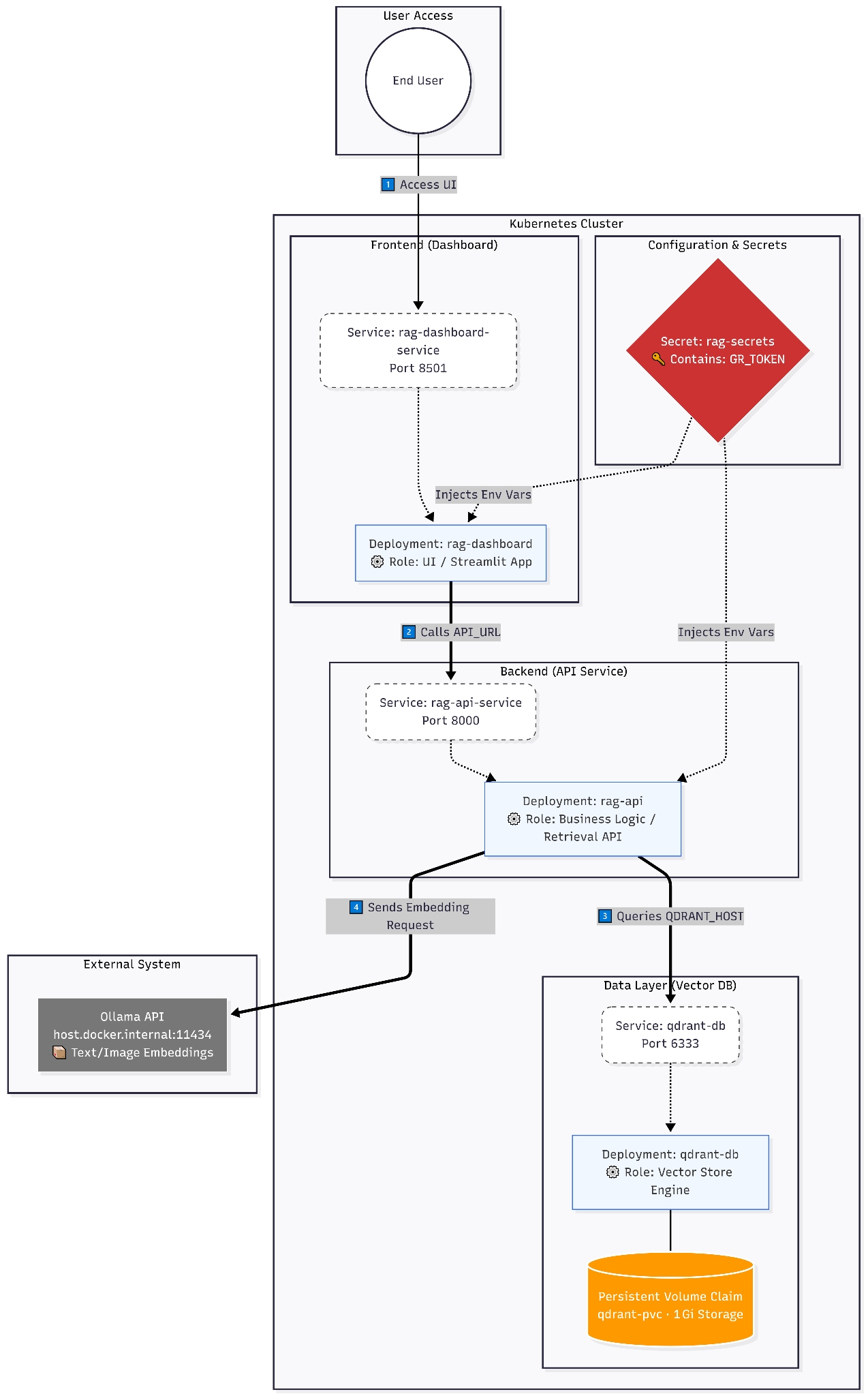
Цей YAML-маніфест описує трикомпонентну архітектуру (Database, API, Dashboard) для розгортання Multimodal RAG системи в Kubernetes. Нижче наведено детальний опис кожної секції та команди українською мовою для вашої документації. Для швидкості я маю по одній репліці на кожен сервіс, але якби розгортала для широкого користування, поставила мінімум 5.
Коротко про кожен сервіс:
Qdrant
kind: Deployment: вид пода (оновлення, масштабування).
strategy: type: Recreate: стратегія оновлення, при якій стара версія Pod видаляється перед створенням нової. Це необхідно для баз даних з одним диском (ReadWriteOnce), щоб уникнути конфлікту доступу до даних.
replicas: 1: Кількість копій бази даних (одна для стабільності транзакцій).
selector / matchLabels: вказує Kubernetes, які саме Pod-и належать до цього розгортання (мітки app: qdrant).
image: qdrant/qdrant:latest: image Qdrant, яке потрібно використовувати.
ports: containerPort: 6333: порт 6333 всередині контейнера для API-запитів.
resources (requests/limits):
requests: мінімальні ресурси (250m CPU, 512Mi RAM), які контейнер може використати.
limits: максимальні ресурси (1Gi RAM).
volumeMounts: внутрішнє сховище.
volumes: зовнішнє сховище, яке посилається на PersistentVolumeClaim.
Service
kind: Service: стабільна внутрішня DNS-адресу (qdrant-db), щоб сервіси могли комунікувати.
PersistentVolumeClaim
kind: PersistentVolumeClaim: виділення постійного дискового простору (1Gi), який не зникне після перезавантаження Pod-а.
accessModes: ReadWriteOnce: диск може бути підключений лише до одного вузла кластера одночасно.
RAG API
Deployment
env:
QDRANT_URL / QDRANT_HOST: адреса Qdrant.
ROLE: "api"**: entrypoint, оскільки я використовую один dockerfile для всіх контейнерів мені потрібно дати роль та команду запуску окремо для api та dasnboard.
OLLAMA_BASE_URL: адреса локальної LLM моделі (Ollama).
envFrom / secretKeyRef: токени доступу.
livenessProbe: перевірка "живучості". Якщо порт 8000 не відповідає, перезапустить контейнер.
readinessProbe: перевірка "готовності". Трафік не піде на цей Pod, поки контейнер повністю не завантажиться.
Service
type: ClusterIP: API доступний лише всередині кластера для інших сервісів
Dashboard
Deployment
nodeSelector: kubernetes.io/hostname: kind-worker: примусовий запуск на конкретній ноді кластера (kind-worker).
env: ROLE: "dashboard": аналогічна ситуація як і з api: entrypoint для команди.
env: API_URL: адреса, за якою звертається до API.
resources: limits: жорстке обмеження ресурсів (512Mi).
Service
port: 8501: порт за замовчуванню для Streamlit-додатків.
Окремо про image та imagePullPolicy розкажу у наступній частині, оскільки як саме делегувати сильно залежить від стратегії CI/CD.
Створення nodes та podes
Вся архітектура йде від верху, найбільшої структури, - кластера, до найменшої - поду.
Створити кластер
kind create <NAME>Завантажити image
kind load docker-image docker.io/collection/<NAME>Завантажити маніфести
kubectl apply -f <MANIFEST>.ymlВідкрити порт
kubectl port-forward pod/<pod-name> 8080:8080- для локального тестування,
kubectl expose deployment <deployment-name> --port=8080 --target-port=8080 --name=my-service - для деплойменту.
Для перевірки нодів:
kubectl get nodesПовинні бути всі ноди, в моєму випадку два:
NAME STATUS ROLES AGE VERSION
kind-control-plane Ready control-plane 7d20h v1.34.0
kind-worker Ready <none> 7d20h v1.34.0
Для перевірки подів:
kubectl get podsПоди створені успішно тільки тоді, коли мають статус Running. Оскільки в мене контейнери залежать один від одного, то останнім запускається API:
NAME READY STATUS RESTARTS AGE
qdrant-db- <TAG> 1/1 Running 1 (23h ago) 5d18h
rag-api- <TAG> 1/1 Running 3 5d17h
rag-dashboard-<TAG> 1/1 Running 16 (23h ago) 5d18h
data_processing-<TAG> 1/1 Running 1(23h ago) 3d18h
Якщо ж замість Running - Unknown, можу бути тимчасова плутанина кластерів, може допомогти експорт налаштувань кластеру:
kind export kubeconfig --name <NAME>CI/CD: коли система сходить з розуму

Серед багатьох фреймворків, які забезпечують CI/CD я обрала стандартні: Github Actions для CI та ArgoCD для CD, Jenkins та інші не підходять, оскільки потрібно саме K8S - native.
GitHub Actions та unit test для LLM
Як і всі ml - based системи, RAG не можна тестувати стандартними Unit тестами - треба трекати не тільки зміни у коді та їх вплив, але і зміну даних.
CI - GitHub Actions
CD - ArgoCD
GitHub Actions виконує всі jobs, які прописані в маніфесті .yml. Я розділила на 4 частини, приклад маніфесту:
Job(1) - Linting and Formatting: форматування коду, щоб прибрати зайві if через ruff.
Job (2): Functional Testing and Judicial Audit: тестування системи по основним критеріям.
Job (3): Dockerize and Deploy: контейнеризація у єдиний image для спрощення та завантаження у реєстр контейнерів GHCR.
Job (4): Update ArgoCD Manifests: контроль за версіями контейнерів та оновлення.
name: Multimodal RAG CI/CD
on:
push:
branches: [ main, master ]
paths-ignore:
- 'documentation/**'
- 'manifest_examples/**'
pull_request:
branches: [ main ]
jobs:
# Job 1: Linting and Formatting
quality-check:
runs-on: ubuntu-latest
permissions:
contents: write
steps:
- name: Checkout Code
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.9'
- name: Run Ruff Auto-Fix
continue-on-error: true
run: |
pip install ruff
ruff check src/ --fix --unsafe-fixes
ruff format src/
- name: Commit and Push Fixes
uses: stefanzweifel/git-auto-commit-action@v5
with:
commit_message: "🤖 chore: automated ruff quality fixes"
branch: ${{ github.head_ref || github.ref_name }}
# Job 2: Functional Testing and Judicial Audit
test:
needs: [quality-check]
runs-on: ubuntu-latest
timeout-minutes: 60
services:
qdrant:
image: qdrant/qdrant:latest
ports:
- 6333:6333
steps:
- name: Checkout Code
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.9'
cache: 'pip'
- name: Install Dependencies
run: |
python -m pip install --upgrade pip
pip install --upgrade "giskard[llm]" litellm evaluate google-generativeai
pip install -r requirements.txt pytest pytest-asyncio
pip install flashrank
- name: Install & Background Ollama
run: |
curl -fsSL https://ollama.com/install.sh | sh
nohup ollama serve > ollama.log 2>&1 &
# Wait for the server to respond
until curl -s http://localhost:11434/api/tags > /dev/null; do sleep 2; done
ollama pull qwen2.5:1.5b
# Wait for the model to be actually pulled and loaded
sleep 30
- name: Sanitize Test Files
run: |
find src/tests/ -name "*.py" -exec sed -i 's/\x00//g' {} +
- name: Run Giskard & Judicial Tests
env:
QDRANT_URL: http://localhost:6333
OLLAMA_BASE_URL: http://localhost:11434
PYTHONPATH: ${{ github.workspace }}
GR_TOKEN: ${{ secrets.GR_TOKEN }}
GEMINI_API_KEY: ${{ secrets.GEMINI_API_KEY }}
run: pytest src/tests/test_rag.py
- name: Upload Giskard Report
if: always()
uses: actions/upload-artifact@v4
with:
name: giskard-report
path: giskard_report_*.html
- name: Upload Judge Results
if: always()
uses: actions/upload-artifact@v4
with:
name: judge-logs
path: judge_results_*.json
- name: Display Judge Results
if: always()
run: |
echo "### ⚖️ Judge JSON Output" >> $GITHUB_STEP_SUMMARY
echo "\`\`\`json" >> $GITHUB_STEP_SUMMARY
cat judge_results_*.json >> $GITHUB_STEP_SUMMARY
echo "\`\`\`" >> $GITHUB_STEP_SUMMARY
# Job 3: Dockerize and Deploy
build-and-push:
needs: [test]
runs-on: ubuntu-latest
if: github.event_name == 'push'
permissions:
contents: read
packages: write
steps:
- name: Checkout Code
uses: actions/checkout@v4
- name: Lowercase Repo Name
run: |
echo "IMAGE_NAME=$(echo ${{ github.repository }} | tr '[:upper:]' '[:lower:]')" >> $GITHUB_ENV
- name: Login to GHCR
uses: docker/login-action@v3
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build and Push RAG API
uses: docker/build-push-action@v5
with:
context: .
push: true
tags: |
ghcr.io/${{ env.IMAGE_NAME }}:latest
ghcr.io/${{ env.IMAGE_NAME }}:${{ github.sha }}
# Job 4: Update ArgoCD Manifests
deploy-gitops:
needs: [ build-and-push ]
runs-on: ubuntu-latest
if: github.event_name == 'push'
steps:
- name: Checkout Infra Repo
uses: actions/checkout@v4
with:
repository: AnnacKK/multimodal-rag-infra
token: ${{ secrets.GITOPS_TOKEN }}
path: infra
- name: Update K8s Manifest Tag
run: |
#
cd infra/base
kustomize edit set image ghcr.io/annackk/multimodalrag=ghcr.io/annackk/softserve_multimodal_rag:${{ github.sha }}
- name: Commit and Push
run: |
cd infra
git config user.name "github-actions[bot]"
git config user.email "github-actions[bot]@users.noreply.github.com"
git add .
git commit -m "🚀 deploy: multimodal-rag version ${{ github.sha }}"
git pushНалаштування Github Actions
Крок 1: Створення структури каталогів
GitHub шукає файли конфігурації у спеціальній папці.
У корені вашого репозиторію створіть папку
.github.Всередині неї створіть підпапку
workflows.Створіть маніфест(наприклад,
mlops-ci.yml).
Крок 2: Визначення тригерів (Events)
Виберіть події, які запускатимуть пайплайн. Важливо використовувати paths-ignore, щоб не запускати важкі тести при зміні лише документації. На їх основі створіть потрібну структуру job.
on:
push:
branches: [ main, master ]
paths-ignore:
- 'documentation/**'
- 'manifest_examples/**'
pull_request:
branches: [ main ]Крок 3: Налаштування середовища (Runner)
Визначте ОС та версію Python, краще щоб збігалась з версією .dockerfile. Кожна job повинна мати власне середовище.
runs-on: ubuntu-latest
permissions:
contents: write
steps:
- name: Checkout Code
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'Крок 4: Налаштування steps
Кожен тест виконується покроково:
Наприклад, для тесту steps будуть наступними: налаштування Python, завантаження бібліотек та Ollama, запуск test.py, завантаження репортів Giskard та Judge LLM.
Повну діаграму можна подивитись тут.
Крок 5: Git push
Запуск тестів при комміті:
git add .
git commit -m "adding Action"
git push [BRANCH]Giskard
Звичайно писати тести з нуля це таке собі, тому я знайшла Giskard - фреймворк для тестування моделі, повний код тут. Для більшості тестів використовує GPT, замість якої використаю локальну qwen модель як judge.
Giskard тестує всю систему на різні слабкості: галюцинації, faitfulness, замість генерації десятків assert генерує складні промпти. Проблема в тому, що Giskard не розуміє семантики і не може визначити, чи згенерована відповідь дійсно коректна. Тому для перевірки семантики я використовую judge LLM, аналогічно до ragas у API.
Дано:
Датасет промптів
RAG
Context для RAG - Qdrant
Фреймворк тестування - Giskard
Маніфест для Github Actions
Потрібно: максимально покрити всі вразливі місця.
Проблема: розмір Qdrant перевищує тимчасове сховище, яке створюється при кожному push main:
on:
push:
branches: [ main, master ]
pull_request:
branches: [ main ]Для вирішення проблеми з завеликими розмірами Qdrant я створила меньші сніппети (scripts/) кожної з колекції на 300 векторів: така кількість займає небагато місця, але покриває достатню кількість статей для нормально тестування. Github Actions створює нову VM під час кожного push, тому я не можу мати доступ до колекцій Qdrant у докері, через що або створювати колекції з нуля, що я і обрала, або розгортати у хмарі.
get_context_from_qdrant()
Щоб пришвидшити тест я зробила дві версії векторів: перша для judge llm, для якої через reranker з json сніппетів знаходяться релевантні вектори, тоді як для Giskard створюю нову колекцію з нуля та завантажую туди сніппети.
Dense (текст та зображення): семантичний пошук.
Sparse (BM25): пошук за ключовими словами.
Fusion (RRF): об’єднання результатів.
FlashRank (Rerank): переранжування, щоб знайти 5 найбільш релевантних уривків для судді.
qwen_judge_relevance()
Локальна модель (Qwen 2.5) виступає в ролі експерта (Judge). Вона отримує промпт, відповідь системи та знайдений контекст, після чого виносить вердикт: PASS (відповідь релевантна) або FAIL (відповідь не по суті або ігнорує контекст).
recreate_qdrant()
Відтворювання всіх ориганільних колекцій з Qdrant (parent, child, cache).
test_batch_rag_evaluation()
Тестування Judge та Giskard.
model_predict: виклик RAG_engine.
giskard.scan: автоматично шукає вразливості системи (галюцинації, підлабузництво, вірність контексту).
run_judge: запускає семантичний тест з Judge.
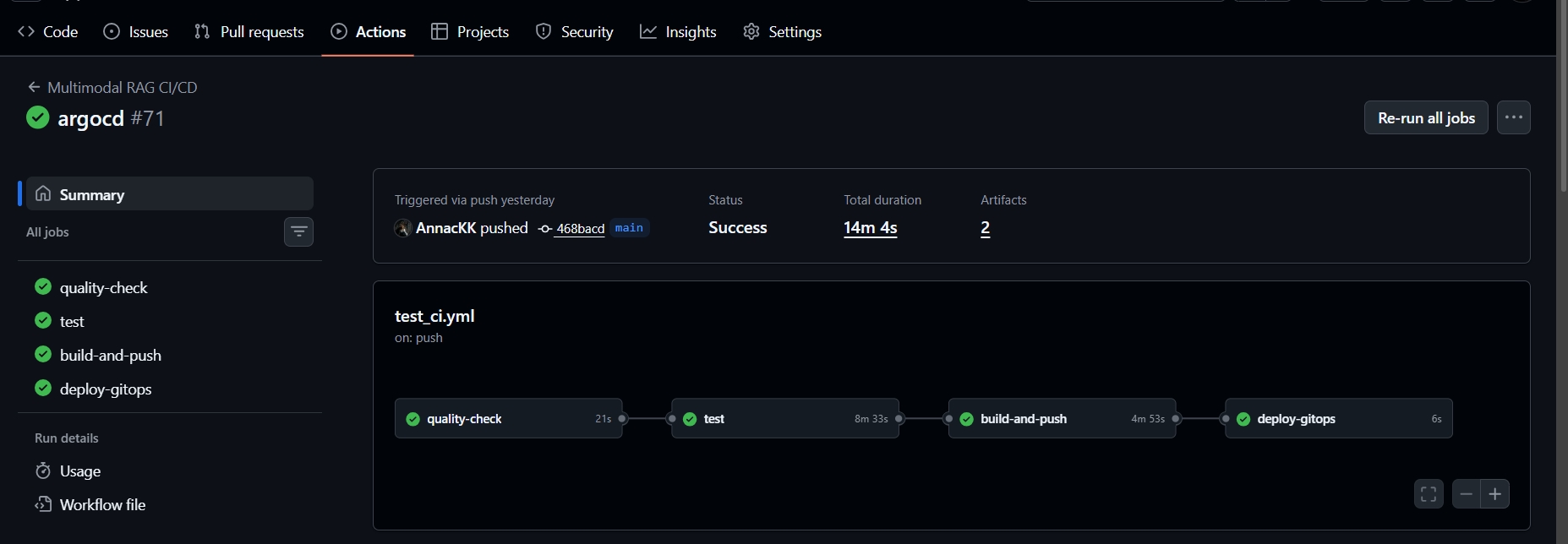
Якщо всі тести успішні, у реєстр контейнерів завантажується новий образ:
Агресивність Giskard та NaN
Giskard є дуже агресивним у тестуванні, і це добре, бо частково імітує реального користувача та краще знаходить прогалини системи, але у мене ця агресивність вилилась у смішну ситуацію. Giskard може змінювати назву стовпця, з якого бере тестові промпти, в мене це стовпець “questions“:
#тестовий датасет
test_samples = [
{"question": "How are AI monopolies affecting the market?", "category": "Business"},
{"question": "What is the latest in transformer world models?", "category": "ML Research"}]
#feature_names відповідають датасету
giskard_model=giskard.Model(
model=model_predict,
model_type="text_generation",
name="RAG_Batch_Evaluator",
description="A RAG engine that retrieves context from Qdrant and generates answers about AI research, business, culture news.",
feature_names=["question", "category"]
)
#передаю тестовий датасет
giskard_dataset=giskard.Dataset(df=test_df, name="The_Batch_Multimodal_Sample")
Здавалось, в чому може виникнути помилка?
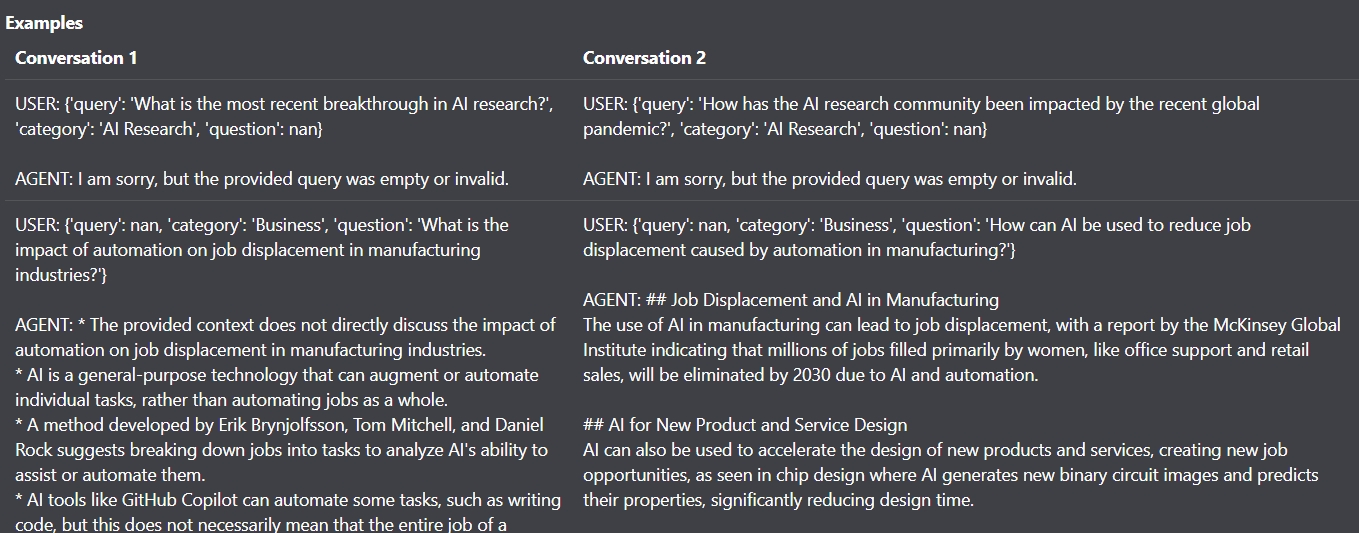
Якщо не додати перевірку на стовпець тестових промптів, RAG буде генерувати тільки коли query:nan.
З перевіркою все працює добре, така помилка зокрема через те, що у Python NaN має числову величину, тому навіть якщо стовпець пустий, треба передавати пусту строку.
def model_predict(df: pd.DataFrame):
async def wrapped_predict(q_str):
async with test_sem:
try:
q = str(q_str) if pd.notna(q_str) else ""
if not q.strip() or q.lower() == 'nan':
return "I am sorry, but I do not have enough information to answer that question."
rag_engine.chat_history.clear()
res = await asyncio.wait_for(rag_engine.run_hybrid_rag(q), timeout=500.0)
if res is None:
return "Error: Engine returned None"
answer = res.get("answer", "")
if "I couldn't find any relevant snippets" in answer:
return "I am sorry, plese refrase so i can search again later."
return answer
except Exception as e:
return f"Error: {str(e)}"
async def run_batch():
results = []
for _, row in df.iterrows():
q_val = row.get('question')
query_val = row.get('query')
if pd.notna(q_val) and str(q_val).lower() != 'nan':
q = q_val
elif pd.notna(query_val) and str(query_val).lower() != 'nan':
q = query_val
else:
q = "" # Both were nan
results.append(await wrapped_predict(q))
await asyncio.sleep(0.2)
return results
future = asyncio.run_coroutine_threadsafe(run_batch(), test_loop)
return future.result()
Giskard також “дивиться“ на семантику error message, наприклад:
return {
"headline": "No Direct Match Found",
"answer": "I found some articles, but nothing specifically answering your question.",
"confidence_score": best_score,
"image_b64": "",
}може пройти перевірку Giskard, тоді як пряме повідомлення “Error“ точно не пройде:
return {
"headline": "Error",
"answer": "Error",
"confidence_score": best_score,
"image_b64": "",
}ArgoCD як інструмент GitOps
Основна концепція GitOps - це контроль за версіями, у призмі K8S - контроль за версіюванням контерів на заміна на найновіші версії. Наприклад, :latest модель з docker не завжди означає, що зараз система працює на оновленому контейнері, що може призвести до проблем з безпекою та ефективністю.
ArgoCD слідує принципам GitOps та використовує репозиторії як source of truth та є окремою нодою, яка буде змінювати версії у кластері.
Argo CD automates the deployment of the desired application states in the specified target environments. Application deployments can track updates to branches, tags, or be pinned to a specific version of manifests at a Git commit.
Перед створенням argo ноди всі ноди повинні бути в стані running. Я слідувала офіційній документації, яка пропонує створити репозиторій як source of truth з усіма маніфестами, які потрібні для деплою, без маніфестів для докера. Також потрібно створити окремий токен, що дає права змінювати маніфести.
ArgoCD змінює imageTag, який показує, який image треба використовувати:
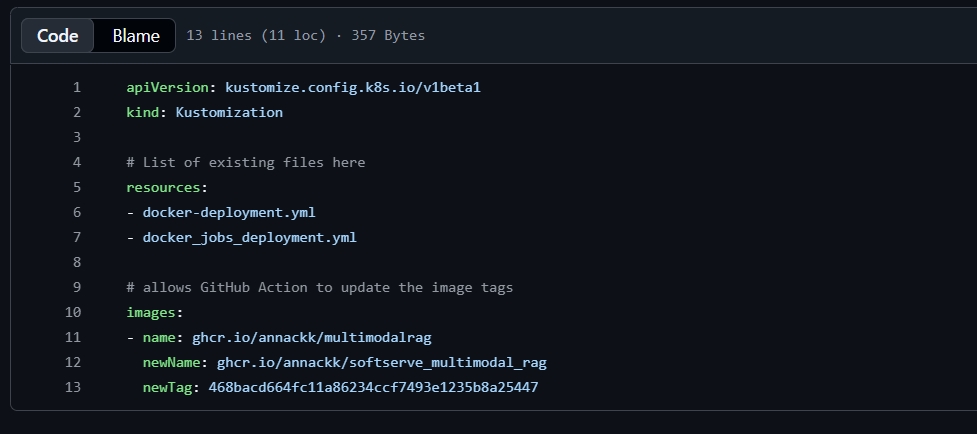
image та imagePullPolicy
docker-deployment.yml, docker_jobs_deployment.yml - маніфести, що відповідають за роботу кластера, тобто координають ноди та версію контейнерів. Контейнери не повинні оновлюватись кожен раз при запуску кластера, але повинні оновлюватись тільки якщо всі тести з GithubActions успішні, за це відповідає imagePullPolicy.
imagePullPolicy: Always. Kubelet запитує реєстр образів контейнера, щоб отримати реєстр образу (qdrant-db-5d6c8587fb-brs5j, після db- реєстр), коли контейнер запускається. Витягує образ, навіть якщо існує локально.
IfNotPresent: image оновлюється тільки якщо немає на ноді все ще.
Never: image ніколи не завантажується.
Оптимальним є imagePullPolicy: IfNotPresent.
Під час локальної оркестрації використовується image з локальної колекції докера image: docker.io/collections/multimodal-rag:latest, яке оновлюється тільки при docker compose, але ніяк не вписується у концепції CI/CD. Для завантаження оновленого image після push потрібно посилатись на реєстр контейнерів GHCR: image: ghcr.io/annackk/multimodalrag:latest.
Налаштування ArgoCD
Для налаштування потрібно рекомендується створити три маніфести: перший для конфігурації самої ноди (infra-repo-creds.yaml), другий для доступу до репозиторія(argo-app.yaml) та третій де AgroCD буде оновлювати тег image (kustomization.yaml). Приклади маніфестів у manifest_examples/.
Створення кластеру AgroCD аналогічно до кластеру для RAG:
Створення кластеру
kubectl create namespace argocdЗавантаження маніфестів
#образ
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
#маніфест Argo
kubectl apply -f multimodal-rag-infra/base/argo-app.yaml
#маніфест доступу
kubectl apply -f multimodal-rag-infra/base/infra-repo-creds.yamlПеревірка стану
kubectl get applications -n argocdГотовий кластер повинен статус Synced :
NAME SYNC STATUS HEALTH STATUS
multimodal-rag Synced Progressing
Якщо ж ви бачите статус Uknown, скоріш за все це показник недостатніх прав токена, або його відсутності, для перевірки:
#повна інформація про кластер
kubectl get app multimodal-rag -n argocd -o yaml kubectl get secret infra-repo-creds -n argocdпоказує статус секрету, тобто токену, якщо його немає, буде помилка:
Error from server (NotFound): secrets "infra-repo-creds" not found
Перевірка поточного image
kubectl get pod -l app=rag-api -o jsonpath='{.items[0].spec.containers[0].image}'Оновлення тегу у kustomization.yml не буде застосовано, якщо образ взятий не з реєстру, а, наприклад, з докеру:
docker.io/library/multimodalrag-rag-api:latest
Щоб все працювало, тег повинен бути ідентичним до нового image:
ghcr.io/annackk/softserve_multimodal_rag:468bacd664fc11a86234ccf7493e1235b8a25447

Оптимізація системи
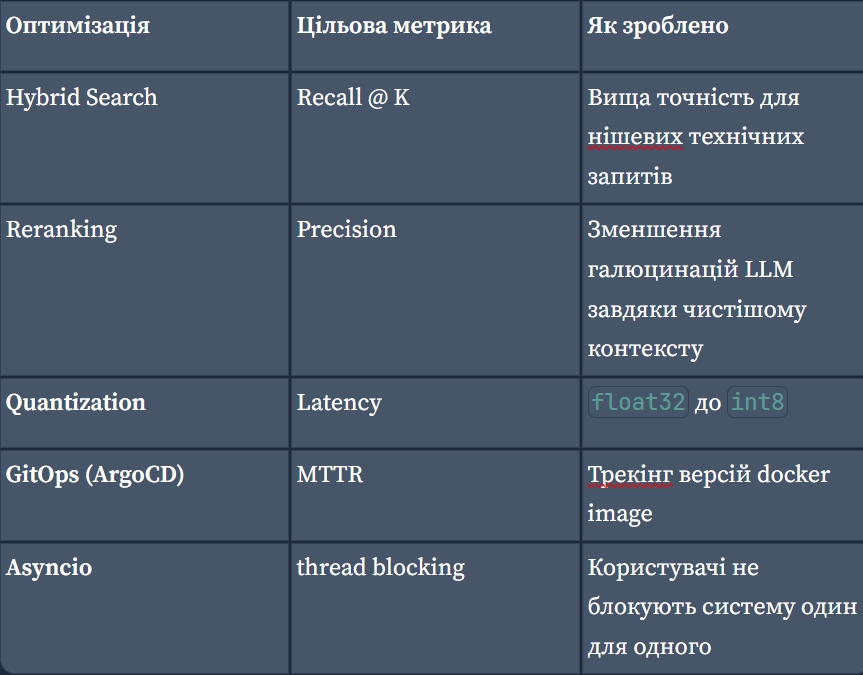
Recap всіх методів, завдяки яким система стала швидшою та надійнішою:
Як експерт із MLOps, я підготував повний список стратегій оптимізації, які ми впровадили та обговорили для вашого проекту Multimodal RAG. Ця документація охоплює весь життєвий цикл — від завантаження даних до судової оцінки (judicial evaluation), класифіковану за їхнім технічним впливом.
1. Пошук та векторна БД(Qdrant)
Hybrid Search: поєднання Dense (семантичних), Vision (на основі CLIP) та Sparse (BM25/SPLADE) векторів для пошуку по тегам, назвам та з семантичним змістом.
Reciprocal Rank Fusion (RRF): використання
models.FusionQueryдля оцінки знайдених векторів.Prefetching:
models.Prefetchдля кількох підзапитів за один цикл звернення Qdrant, що зменшує latency.Payload Indexing: індексація специфічних полів (наприклад,
categoryабоmetadata) у Qdrant для швидшої фільтрації.Quantization: зміна векторів з
float32доint8для економії до 75% оперативної пам'яті з мінімальною втратою точності.
2. Inference
Асинхронне виконання (asyncio): асинхронність для Qdrant та FastAPI для обробки одночасних запитів кількох користувачів без блокування основного потоку.
Thread Pooling: обмеження через
asyncio.to_thread, щоб запобігти заморожуванню циклу під час важких локальних обчислень ембеддінгів.Reranking через FlashRank: легкий крос-енкодера (
Ranker) після початкового пошуку для переупорядкування топ-15 результатів, щоб прибрати “сміття“ - вектори, що не сильно відносяться до промпту користувача.One model per One task: Qwen 2.5 (1.5B) через Ollama як Judge та OLLAMA 4 через Groq.
3. Пайплайн та архітектура (MLOps)
Idempotent Ingestion:
mapping.pyз UPSERT дозволяє перезапускати пайплайн без створення дублікатів Qdrant.Small - to - Big (Parent-Child): маленькі вектори для пошуку, великі вектори для зберігання.
Stateless Scaling: змінні оточення (
GR_TOKEN,QDRANT_HOST) та секрети для горизонтального масштабування.Container Healthcheck: трафік надходить до API лише після того, як контейнери готові.
4. Оцінка та контроль якості
Автоматичне сканування (Giskard): автоматичні тести для виявлення галюцинацій, проблем із вірністю контексту (faithfulness) та упередженості (sycophancy).
LLM-as-a-Judge: judge model для семантичної валідації генерацій.
Фільтрація шляхів у CI/CD: GitHub Actions із
paths-ignore, щоб не запускати тестів, коли змінюються неважливі для системи дані, наприклад документація.Drift Detection: CronJob для розрахунку data drif запускає data_processing лише при значній зміні розподілу даних.
5. Prompt Engineering
Self-Correction: base prompt та judge prompt.
Query Expansion: генерація 3 варіацій промпту користувача для покращення повноти (recall) векторного пошуку.
Конвертація Vision-у-Текст: генерація опису медіафайлів.
На цьому закінчую свою розповідь, якщо маєте питання або зауваження - з радістю чекаю у коментарях.
Що почитати далі
Evaluating Large Language Model (LLM) systems: Metrics, challenges, and best practices
Reranker vs. Retriever: Who Does What in RAG?
CI/CD 101: From Code Commit to Production
Switched to hardened distroless images thinking CVEs would stop being my problem, they didn't

