Ця стаття є перекладом https://xata.io/blog/serverless-postgres-platform
Починаючи з сьогоднішнього дня, проєкт Xata працює у форматі serverless бази даних Postgres. Це означає, що ви можете підключатися до них за допомогою будь-якого клієнта для бази даних Postgres і використовувати їх так, як будь-яку іншу базу даних Postgres, при цьому залишаючи все, що вам подобається у Xata: миттєве створення БД/гілок, відсутність "холодного" старту, відсутність призупинення/сплячки при відсутності активності, full-text пошук, вкладення файлів та багато іншого. І так, безкоштовний тариф Xata також застосовується до баз даних Postgres, що робить його одним з найбільш щедрих безкоштовних тарифів для Postgres в галузі.
Зробити це можливим було цікавим технічним викликом і є результатом кількох проєктів, пов'язаних з Postgres. Докладніше ми розглянемо у цій статті.
Нові бази даних з підтримкою Postgres перебувають у відкритій беті, і є доступними для тестування, використовуючи інструкції нижче.
Створіть підключення до Postgres
Xata тепер дозволяє прямі підключення до Postgres. Щоб ввімкнути це, слідуйте цим крокам:
1. Увімкніть Postgres у налаштуваннях вашого робочого простору.
2. Створіть нову Postgres базу даних.
3. Використовуйте @next версію наших API в своєму проєкті.
npm install -g @xata.io/cli@next
npm install @xata.io/client@next
У випадку помилок - зверніться до документації.
Хто ми?
Якщо ви ще не чули про Xata раніше, давайте почнемо з кількох введень. У листопаді 2022 року ми запустили сервіс баз даних Xata з продуктом, який мав на меті надати найкращий можливий досвід розробника для бази даних. Ми вважали, що бази даних тоді трошки відстали від сучасних робочих процесів розробника, API та загального досвіду. Тож ми переосмислили все з нуля, не прив'язуючись до будь-якої існуючої технології баз даних.
Ми уявляли наш продукт як компроміс між Airtable та традиційними базами даних, і ми вважаємо, що нам досить добре вдалося дотриматися цієї візії. Як і в Airtable, "xatabases" стартують миттєво, мають багато типів, не мають "холодного" старту і ніколи не призупиняються через відсутність активності. Як у традиційних базах даних, вони мають ACID-транзакції, та не мають обмежень на кількість рядків, структурну цілісність та продуктивність.
З того часу десятки тисяч розробників відкрили для себе Xata, активно використовуючи його в своїх додатках і надаючи нам дуже цінний зворотний зв'язок. Розробники у нашій спільноті цінують те, наскільки легко почати працювати з Xata, швидко ітерувати і відчувати, що це більше схоже на SaaS продукт, аніж ще один DBaaS.
Протягом останнього року ми продовжували випускати функції, від нового робочого процесу розробника на основі git для внесення змін у схему з нашою функціональністю гілок, до вкладень файлів, які спрощують роботу з файлами та зображеннями як стовпцями у вашій базі даних. Ці функції викликали багато захоплення.
Не останнім є відкриття pgroll, інструмента, який надає zero-downtime міграції для будь-якої бази даних PostgreSQL. Це також викликало досить великий інтерес від широкої спільноти Postgres. Пізніше цього тижня ми анонсуємо ще один проєкт з відкритим кодом, який, на нашу думку, вам сподобається 🦎.
Serverless Postgres сервіс
Це приводить нас до сьогоднішнього запуску: нового сервісу безсерверного Postgres в центрі платформи Xata. Подивившись на сервіс Postgres ізольовано (ігноруючи все інше на платформі Xata), він виглядає досить добре:
розділення обчислення та зберігання, забезпечуючи безмежне зберігання.
опціональне автоматичне масштабування вгору і вниз в залежності від навантаження.
висока доступність за допомогою реплік для читання в кількох зонах доступності та автоматичного відновлення.
підтримка як нативного протоколу зв'язку Postgres, так і SQL через HTTP (для зручного доступу з edge функцій).
підтримка найпоширеніших розширень Postgres.
можливість масштабуватися до 1 ТБ RAM та 128 vCPU.
Ми розробили сервіс Postgres з метою оптимізації надійності, масштабованості та ефективності витрат.
Надійність
Сервіс Postgres Xata використовує під капотом AWS Aurora, перевірений багатьох боях сервіс. Ми використовуємо AWS Aurora з моменту запуску Xata, і у нас є сторінка для відстеження надійності, на який ми пишаємося. А також у нас також є офіційний SLA.
Навіть на безкоштовному рівні ми пропонуємо високу доступність і резервне забезпечення, з репліками, які працюють в кількох зонах доступності. Автоматичне перехід від основного екземпляра до репліки є автоматичним і гарантовано не призводить до втрати даних. На рівні зберігання дані синхронно реплікуються на шість вузлів зберігання у трьох зонах доступності.
Масштабованість
Доступні типи екземплярів в Xata досягають 128 vCPU та 1 ТБ RAM. Зберігання може бути масштабовано до 128TiB на кластер. Це досить багато резервного простору для вертикального масштабування.
Щодо горизонтального масштабування, те, що ви можете миттєво створювати бази даних і гілки по всьому світу та переміщати їх між кластерами без даунтайму, відкриває кілька архітектурних можливостей. Наприклад, ви можете створити базу даних для кожного зі своїх клієнтів і розмістити їх у різних регіонах. Це можливо завдяки нашому глобальному управлінському рівню та логічним базам даних.
Ефективність витрат
Xata пропонує високий рівень опцій, що призводить до ефективності витрат для широкого спектру використання. Xata дозволяє дуже легко переходити від одного типу кластера до іншого, тому ви можете спробувати своє навантаження на різних типах кластерів, щоб визначити, який найкраще підходить з точки зору продуктивності та ефективності витрат.
На малому масштабі ми пропонуємо безкоштовний рівень, який включає високу доступність та репліки для читання, відсутність "холодного" старту і призупинення екземпляра після кількох днів. Ми можемо пропонувати це стабільно завдяки використанню спільних кластерів та автоматичному масштабуванню.
На великому масштабі, при використанні виділених кластерів (наразі у закритій альфа-версії) ви платите за використані ресурси і маєте високий рівень контролю. Наприклад, для передбачуваного навантаження ви можете налаштувати певний розмір екземпляра, тоді як для непередбачуваного навантаження автомасштабування може бути більш ефективним з точки зору витрат. Так само ви можете вибирати між стандартним сховищем і сховищем, оптимізованим для вводу/виводу, що є більш ефективним з точки зору витрат для навантаження з великою кількістю введення/виведення.
Безкоштовний рівень
Оскільки безкоштовні плани в галузі останнім часом мають тенденцію швидко припинятися, ви, можливо, дивитеся трохи сумнівно на наш безкоштовний рівень зберігання об’ємом 15 ГБ, високу доступність, відсутність "холодного" старту, звучить занадто круто, щоб бути безкоштовним. Ми розуміємо, що довіра виграється протягом багатьох років (і втрачається за хвилини), що ми - стартап, який робить стартапові речі, і що процентні ставки щось вартують, але ми думаємо, що є кілька речей, які варто сказати:
По-перше, архітектура Xata була спроектована з можливістю пропонувати безкоштовний рівень, завдяки використанню спільних кластерів та автоматичному масштабуванню. Наразі безкоштовна активна база даних з постійним трафіком у межах лімітів тарифів коштує нам менше 1,5 доларів на місяць. Це включає не тільки Postgres, але й Elasticsearch та реплікацію між ними, а також запуск двох реплік для високої доступності. Це можливо завдяки нашим загальним кластерам (див. реалізацію). Вартість кожної бази даних буде знижуватися, оскільки ми вимикаємо пошук та реплікацію, якщо вони не використовуються взагалі, перенаправляємо бази даних у холодне сховище, якщо вони неактивні протягом кількох місяців і так далі. Іншими словами, хоча активна безкоштовна база даних, яка використовує всі можливості, може коштувати нам кілька доларів на місяць, вартість майже неактивної безкоштовної бази даних буде близько нуля.
По-друге, безкоштовний рівень є важливим для нас через історію компанії. Ідея Xata виникла з некомерційного фонду, коли ми зрозуміли, що керування базами даних - це обмежувальний фактор для багатьох малих проєктів. Сьогодні я з гордістю можу сказати, що кілька неприбуткових організацій розробляються на основі Xata, і деякі з них на безкоштовному плані.
Платформа
Цілком можливо використовувати Xata як Postgres сервіс і нічого більше, і ми не могли бути б щасливіше, якщо ви просто це зробите. Однак ми мислимо про Xata не як про Postgres DBaaS, а як про платформу даних для PostgreSQL: кілька сервісів та інструментів, інтегрованих разом набагато тісніше, ніж у класичного постачальника хмарних послуг, щоб спростити спосіб, яким розробники будують додатки, орієнтовані на дані, та керують базами даних.
Так платформа Xata виглядає на високому рівні:
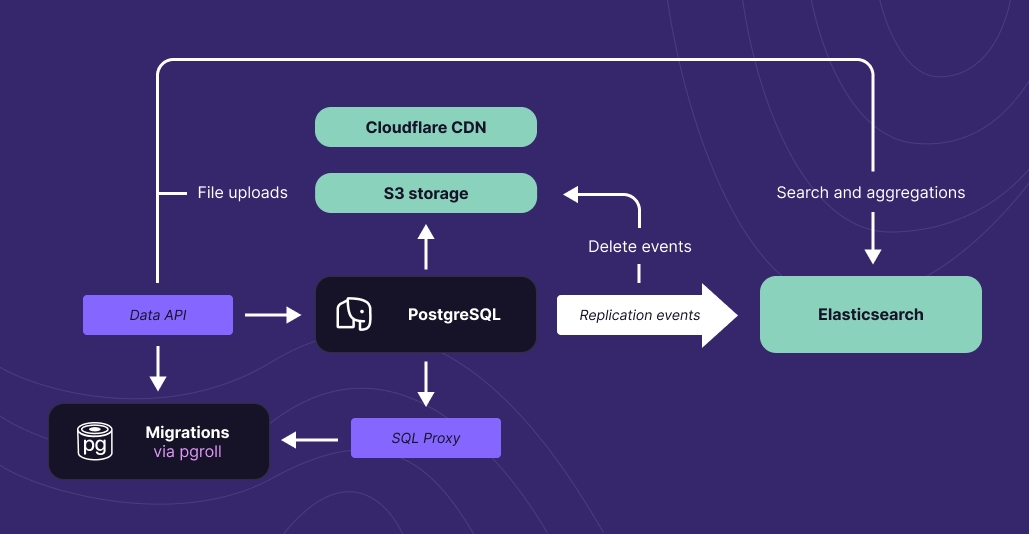
Дані автоматично реплікуються, включаючи зміни схеми через міграції, за допомогою реплікації в Elasticsearch, яка обслуговує наш пошук, векторний пошук та агрегаційні точки доступу, в яких вона виявляється найкраще. Файли зберігаються в S3 та обслуговуються через CDN Cloudflare. Події реплікації використовуються для збереження лічильника посилань на файли, тому вони можуть бути спільно використані між гілками, або видалені, коли вони більше не потрібні.
Якщо важливі для вашого додатка вкладення файлів або повнотекстовий пошук або векторний/гібридний пошук, Xata ймовірно, запропонує вам кращу платформу для побудови на її основі, ніж класичний DBaaS. І це лише початок, ми плануємо мати подібні тісно інтегровані рішення для часових рядів, інтелектуального кешування, черг, тощо.
Реалізація
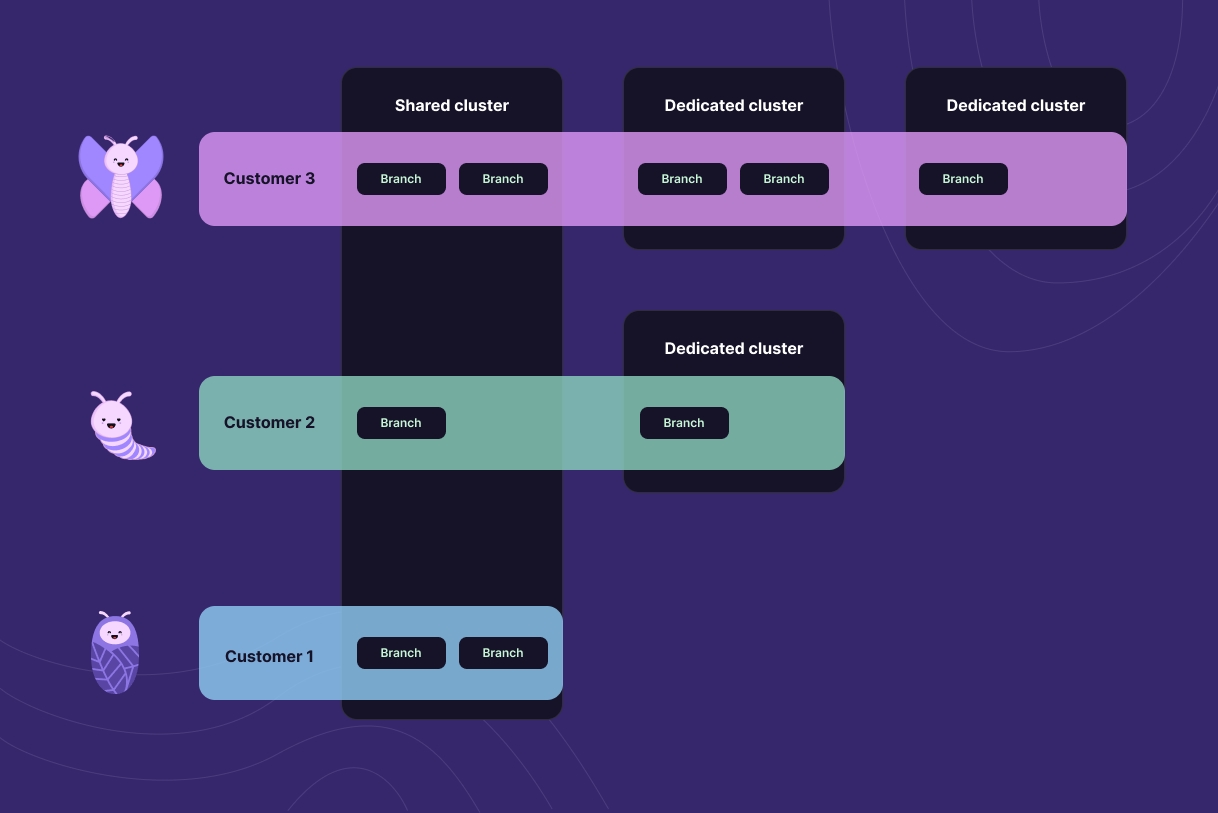
Одним із ключових понять в реалізації Xata є поняття логічних гілок баз даних. База даних може мати кілька гілок, і завжди має принаймні одну, яка за замовчуванням називається main. Гілка бази даних представлена в Postgres як схема і може бути розміщена на одному з багатьох кластерів Postgres по всьому світу, а також переміщена з одного кластера на інший.
Це призводить до рівня роз'єднання між логічними базами даних та гілками, які відчуває застосування, і основними екземплярами Postgres, на яких вони працюють. Оскільки кластери вже заздалегідь надані, логічні бази даних та гілки можуть бути запущені миттєво і розподілені та переміщені в залежності від бізнес-потреб. Це розблоковує деякі цікаві використання, такі як шардування на кожного користувача, де кожен користувач - це гілка, використання логічної бази даних для кожної мікро-служби або автоматичне створення гілок розробника для кожного запиту на злиття. Ми використовуємо це логічне розділення в нашому безкоштовному рівні, де багато невеликих баз даних та гілок використовують один і той же відносно великий базовий кластер Postgres.
Щоб це стало можливим, нам довелося вирішити кілька проблем:
маршрутизування трафіку до правильного кластера на основі метаданих про гілку бази даних.
забезпечити, щоб з'єднання на рівні гілки могло отримати доступ тільки до цієї єдиної гілки.
забезпечити, що зловмисники не зможуть викликати небезпечні SQL-функції.
обмежити проблеми з "шумними сусідами" у загальних кластерах.
SQL-проксі
Ключем до рішення більшості цих проблем є наша технологія SQL-проксі. Хоча існує багато проксі-серверів Postgres (наприклад, pgbouncer, pgcat, Supavisor), які служать різним цілям, SQL-проксі Xata не тільки говорить на мові Postgres, але також розуміє SQL на досить глибокому рівні. Наприклад, він може знати, які таблиці використовуються, які стовпці запитуються, які функції викликаються з якими параметрами і так далі. Це дозволяє нам блокувати дії, які були б небезпечними для кластера Postgres. Хоча безпека в основному забезпечується за допомогою ролей Postgres, Проксі може обмежувати швидкість та одночасність на загальних кластерах (ми цього не робимо для присвячених кластерів).
Проксі дозволяє нам "віртуалізувати" доступ не тільки до даних у гілці, але і до каталогу Postgres таблиць, функцій, послідовностей та іншого. ОРМ, такі як Prisma та Drizzle, роблять досить складну інтроспекцію, щоб побачити таблиці та стовпці, які наразі визначені, і ми хотіли б впевнитися, що вони працюють без будь-яких змін.
Ви, можливо, хочете знати, чому ми вирішили представляти гілки баз даних як схеми Postgres, а не окремі бази даних Postgres. Причина пов'язана з логічною реплікацією, яка є ключовим компонентом платформи баз даних, оскільки надійний захоплення змін даних (CDC) є такою важливою функцією для синхронізації декількох сховищ даних. Окремі бази даних змусили б нас робити слот реплікації для кожної.
Події логічної реплікації
Говорячи про логічну реплікацію, то ще одна проблема, яку нам довелося вирішити, - це отримання не тільки подій даних, але й подій схеми від Postgres. Добре відомим обмеженням системи логічної реплікації Postgres є те, що вона включає тільки зміни даних, а не зміни DDL. Проте наявність змін схеми в тому ж потоці подій значно спрощує споживачів наступного рівня для подій логічної реплікації. Спосіб, яким ми вирішуємо це, полягає в установці тригерів подій DDL, які записують зміни схеми у таблицю "вихідної скриньки", яка реплікується за допомогою того ж слота реплікації.
Ми вважаємо, що ця технологія буде корисною для багатьох додатків Postgres, тому ми плануємо в найближчому часі відкрити її код проєкту.
Інтегрований pgroll
Ще одним ключовим елементом нової архітектури Xata є pgroll, наш проект з відкритим кодом для zero-downtime міграцій схеми.
Хоча pgroll є інструментом командного рядка, щоб надати його переваги всім користувачам Xata, ми розробили обгортку для нього. Ця обгортка пропонує API для конкретних міграцій, а також автоматично перехоплює DDL. Це дозволяє нам надати доступ до pgroll нативно в платформі Xata, навіть не знаючи, що ви використовуєте pgroll!
Хоча ще є робота з повною інтеграцією pgroll, ви вже отримуєте деякі важливі переваги: збереження історії міграцій, автоматичне уникнення проблем з блокуванням та увімкнення більш складних міграцій, які потребують резервного копіювання даних. Ми ще не показуємо багато версій схеми одночасно, але ми плануємо це зробити в майбутньому. Це буде ключем до створення простого і безпечного робочого процесу для міграцій схеми будь-якого типу, і ми з нетерпінням чекаємо на це майбутнє.
Цього тижня очікуйте детального допису в блозі про pgroll та про те, як ми інтегрували його в Xata.
Дізнайтеся більше
Дізнайтеся більше про розробку Xata від людей, які створили цей продукт, і перегляньте швидке демо, щоб побачити його в дії. Перегляньте нашу останню сесію зустрічей з творцями тут:
https://www.youtube.com/watch?v=d-u2Naheqc4&ab_channel=Xata
Заходьте у Discord і скажіть привіт 👋
Якщо у вас ще немає облікового запису Xata, це найкращий час для щоб створити його!
Підтримати автора можна зареєструвавшись на сайті Whitebit за реферальним посиланням https://whitebit.com/referral/6f7c7706-ec7d-4a60-8021-adf88b3a9559
