
Що таке ChatGPT
Ну якщо дуже спростити, то це Т9 на стероїдах з вашого смартфону, який вгадує наступне слово. Для прикладу я пишу “Я зараз їду до”, то клавіатура підказує, що наступним словом може бути “дому”, “тебе”, “вас”
ChatGPT являється представником сімейства моделей GPT (Generative Pre-trained Transformer). Про трансформерів ми ще потім згадаємо. А зараз почнемо з простих залежностей та простенькі нейронок.
Залежності
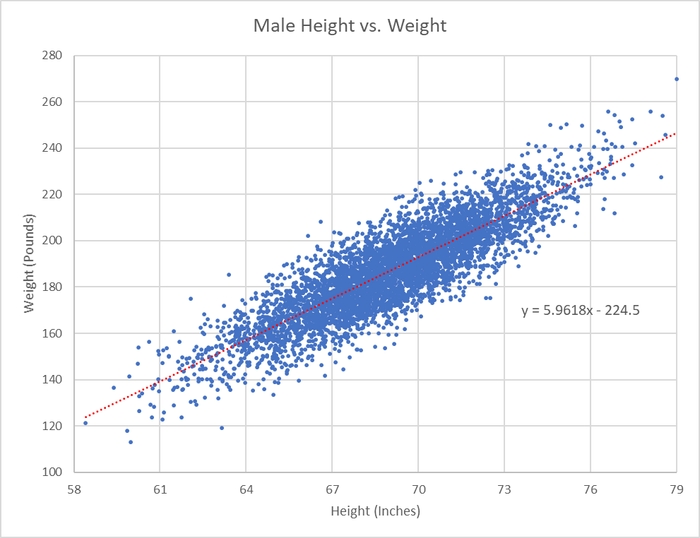
Уявіть, що вам треба вгадати вагу чоловіка, залежно від його віку. На графіку нижче можемо побачити цю лінійну залежність. Якщо ми додамо сюди більше параметрів, таких як вік, так точність у нас збільшиться. У вас може виникнути питання: “ну окей, з ростом та вагою все ясно, але до чого тут мовні моделі?” А до того, що це те саме, але з на багато (дуже багато) більшою кількістю параметрів. Тобто наша задача знайти таке рівняння, яке б дало найбільш точний варіант того, яке наступне слово. Так, ми слово за словом шукаємо те, яке найкраще підходить (Хоча ні, не завжди те, яке найкраще 😅)
Нейронні мережі
Окей, щоб зрозуміти звідки ми беремо кофіцієнти, - треба розібратися з тим, як працюють нейронні мережі. Ми задаємо вхідні дані, а на виході отримуємо кофіцієнти. Уявимо, що нам треба, щоб наша нейронка розпізнавали що написано в 3×3 пікселях. У нас буде 1 вхідний рівень, 2 приховані рівні та 1 вихідний.
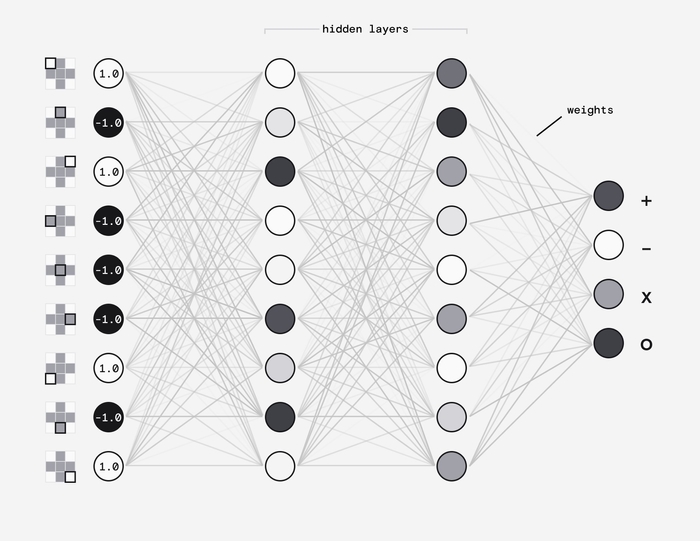
На вході у нас 9 найронів, які приймають значення від -1 до 1, а на виході у нас 4 нейрони, які матимуть значення імовірності від 0 до 1. В прихованих рівнях нейрони повʼязані та впливають на результат наступного рівня за допомогою ваг (Може бути від -1 до 1). Як правильно розставити ваги? Ну тут ми займаємося навчанням нейронки. Даємо картинку 3×3 дивимося результат, та намагаємося знайти такі ваги, при яких буде найточніший результат. На етапі тренування ми маємо вхідні дані та очікуваний результат. Повторюємо це багато разів і шукаємо той випадок, який дає найкращий результат, відносно очікуваного результату.
Мовні моделі
Вхідний текст розбивається на токени, якими можуть бути слова, знаки, символи та інші частини мови. Усі ці токени зберігаються в багатовимірному векторі, де групуються між собою. Нижче, для спрощення, побачимо це на 2-ох вимірній площині
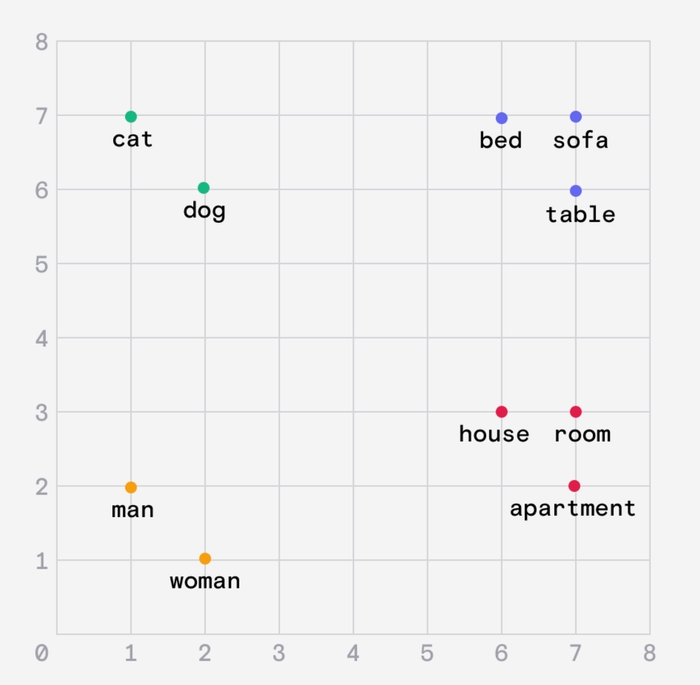
Тобто, якщо нам треба додати слово “цуценя”, то воно буде поруч із “собака” та “кіт“
Мовні моделі намагаються вгадати наступне слово, зважаючи на контекст, але в той же час, відповідь буде кожного разу різна. Модель не шукає лише те слово, що найбільше підходить, але й бере до уваги на випадковість, адже саме вона дає найкращий результат. Тут така собі функція random()

Трансформер
Памʼятаєте фільм “Трансформери“? Так ось, вони нічого спільного з розробкою Google не мають. Трансформер – це назва архітектури нейромережі, придуманої в Google у 2017 році. Розробка цієї архітектури сильно повпливала на долю штучного інтелекту та почала використовуватися в перекладах, обробці зображень, відео, звуку та генерації тексту. Трансформер приймає на вхід один тип послідовностей, а на виході вертає інший, перетворенний по певному алгоритму. Його головною фішкою стала гнучкість та легка маштабовуваність. На початку, моделі обробляли вхідні дані один за одним, тому вони “губилися” на 2-3 абзаці тексту. Трансформери ж дозволяють дивитися на всі дані одночасно, що дає набагато кращі результати.
Як навчати мовні моделі
Якщо вам треба навчити модель розрізняти що є на фото, то вам перед тим потрібно описати всіх їх. Це може зайняти значний шматок часу

З мовними моделями все набагато легше, бо всі тексти, що написали люди - це вже готові дані для тренування. Що ж, ми скачуємо всі тексти з Wikipedia, Reddit, Stackoverflow та інших відкритих ресурсів. Вот накачали ми 40 гігабайт текстів, починаємо навчання.
Кількість параметів в GPT-2 - 1,5 міліарда, або 6 гігабайт. Чим більше параметів - тим кращий у нас буде результат генерації тексту. Наш транформер дозволяє нам легко масштабуватися, то чому ж не закинути більше даних? Так в 2020 році компанія OpenAI вже мала модель, яка містила 175 мільярдів параметів і важила 700 гігабайт (Навчали її на 420 гігабайт даних). Так в GPT-3 обʼям параметів моделі був більший ніж обʼєм тексту, на якій вона була навчена. На такій великій кількості текстів вона почала краще справлятися з перекладом за моделі, які під це створювалися, а також начилася матиматики, програмування та іних штук.
Цікаво, що якщо написати в ChatGPT «let’s think step by step» (Давай подумаємо крок за кроком), то результат буде кращий. Звідси почалася розроблятися списки “промтів” (Це спосіб задати запит так, щоб нейронка в даному випадку, дала відповідь так, як нам треба). Її можна попросити поводитися як професійний програміст, пʼяний друг, викладач з англійської і тд.
Окей, наша мовна модель може писати різні тексти, але ми не хочемо, щоб вона дала інструкцію, як зробити вибухівку. Тут нам треба підключити людей, які будуть оцінювати відповіді і ставити оцінки. Ось тут і пояляється версія GPT-3.5, яка намагається отримати найкращу оцінку від людини.
В чому секрет ChatGPT від OpenAI?
Цікаво, що саме зручний інтерфейс у вигляді всім знайомого “чатіку” та доступу до нього усім, хто, навіть, не дотичний до програмування - став цим ключовим фактором, який зробив його успішним. Люди почали вигадувати різні способи роботи з чатом та поширювати свої результати в соціальних мережах. Так в ChatGPT за 2 місяці зареєструвалося 100 міліонів користувачів (Spotify - 55 місяців, Instagram - 30, TikTok - 9)
Висновики
ChatGPT дав великий поштовх для нейронних мереж в зручному інтерфейсі та показав їх можливості. В майбутньому багато компаній будуть впроваджувати нейронки, які зміннять наш світ, тому необіхідно навчитися працювати з ними
