Як любов до музики та технологій надихнула мене на створення того, що бачите на екрані.
У цій статті я детально розповім, як створювала датасет та навчала нейромережу, що розпізнає 14 основних гітарних акордів. Почнемо з найпростішого: навіщо це потрібно? По - перше, це цікавий та доволі складний учбовий проект, по - друге, його можна використовувати як тренажер для гітаристів - початківців (після допрацювання, звичайно). Складність найпростіше пояснити через аналогію з відомим датасетом коти - собаки. Людина з легкістю може розпізнати, де на фотографії кіт, а де собака, незалежно від їх пози, тоді як нейромережі іноді важко це зробити. Основна проблема в тому, що деякі породи котів в деяких ракурсах можуть виглядати як собаки, і навпаки. Ця ж проблема існує при розпізнаванні гітарних акордів: в деяких ракурсах акорди є дуже схожі або ж навіть ідентичні, про вирішення цієї проблеми трішки пізніше.
Я не буду детально розповідати про алгоритм роботи YOLO, тож якщо вам цікаво, пропоную послухати лекцію від Ендрю Ин.
Основна ідея
Навчити нейромережу на датасеті, що складається з фотографій положення рук при грі основних 14 гітарних акордів, після навчання моделі YOLO за допомогою бібліотеки opencv, налаштувати потік з вебкамери, таким чином, щоб модель розпізнавала акорди в режимі реального часу. Звучить складно, але оскільки це учбовий проєкт основний фокус на навчання на власному датасеті.
Підготовка даних
Вибір датасету грає одну з основних ролей у якості моделі та трактується підхідом, за яким інженер розробляє модель. Серед існуючих підходів, Data-Centric та Model-Centric, все частіше обирають перший, який вважається більш практичним, тоді як другий підхід частіше використовують у наукових роботах. Я прибічниця першого, тому що він дає необхідну гнучкість у час, коли дані змінюються неймовірно швидко і ці зміни потрібно брати до уваги.
Для навчання моделі YOLO мені знадобиться створити власний датасет, оскільки у відкритому доступі немає. Важливе питання, яке потрібно вирішити - це кількість фотографій у кожному класі та ракурси, з яких вони будуть зроблені. Для якісного навчання моделі потрібно мінімум 500 - 1000 фотографій для кожного класу, але оскільки проект учбовий, я зменшу кількість до 30 фотографій для кожного класу: 14 класів * 30 фотографій = 420 загалом. Зміна ракурсів потрібна для того, щоб внести різноманіття - data diversity, таким чином не допустити “привчення” моделі до конкретного типу фотографій. Наприклад, якщо зробити 30 фотографій з переднього центрального ракурсу (рука розташована по центру, без повороту вліво\вправо) - скоріш за все, модель буде розпізнавати акорд тільки в такому положенні руки, що може призвести до поганої якості класифікації.

Питання друге, як зібрати швидко 420 фотографій? Перший варіант - автоматично зробити фотографії за допомогою вебкамери , другий - зробити фотографії на телефон, потім змінити їх розмір та ім’я файлу (мені краще перейменувати автоматично кожну фотографію за назвою акорда, але це необов’язково). Я зробила обидва варіанти, але остаточно зупинилася на другому через більш деталізовані фото, функції перейменовування та обрізки фотографій є у файлі rename_resize.py, перший варіант знаходиться у файлі .ipynb.
Модель
Імплементацію алгоритму YOLO обрала неофіційну від Ultralytics, 5 версію - вона є швидкою, точною та доволі легкою в порівнянні з іншими моделями. У документації рекомендується брати зображення розміром 320 або 640 пікселей. У деяких туторіалах використовують прямокутні зображення, проте на обрізку фотографій самим алгоритмом потрібна додаткова пам’ять. Для використання моделі необхідно клонувати репозиторій:
!git clone https://github.com/ultralytics/yolov5та імпортувати необхідні бібліотеки:
!pip install -r yolov5/requirements.txtТепер тестова детекція об’єктів з вебкамери, для цього потрібно завантажити вже навчену модель:
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')'yolov5s' - назва вагів, в даному випадку я використовую small версію для пришвидшення. Для запуску лайфстріма:
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
results = model(frame)
cv2.imshow('YOLO', np.squeeze(results.render()))
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()Кожен фрейм відео з вебкамери передається до моделі, після чого результат класифікації та рамки знайденого об’єкта виводяться на екран, оскільки результат повертається у 4х вимірному форматі, його необхідно привести до 3х вимірного за допомогою np.squeeze.
Імпорт бібліотек
Перше, що необхідно зробити - це оновити python, anaconda (середовище розробки) та numpy - це дасть змогу завантажити необхідні біліотеки чи оновити до необхідних версій, що сумісні з torch. Для трекінгу метрик я використовую comet ml, його потрібно імпортувати перед модулем torch:
from comet_ml import Experiment
from comet_ml.integration.pytorch import log_model
experiment = Experiment(
api_key=" ",
project_name="project_name",
workspace="workspace_name"
)Айпі ключ можна знайти у налаштуванні проекту у самому comet ml
В залежності від середовища розробки, існують 3 варіанти компонент, на яких буде навчатися модель. Найоптимальнішим є навчання на GPU (відеокарті), для якої оптимізовані функції. Зі встановленням torch може виникнути багато неприємних казусів, тому я покажу метод, який особисто мені допоміг:
Перейдіть на https://pytorch.org/get-started/locally/ та оберіть необхідний варіант. Cuda - навчання на відеокарті, cpu - навчання на процесорі.
Скопіюйте згенерований рядок та вставте у термінал (cmd)
Якщо імпорт успішний, перейдіть у середовище розробки та імпортуйте torch вже у середовище. Якщо імпорт успішний - вітаю.
Для тих, в кого є проблеми з версіями бібліотек, як і у мене, перейдіть на сайт https://download.pytorch.org/whl/cu118/torch_stable.html та оберіть потрібну версію torch, torchvision та torchaudio. На момент написання цієї статті, актуальною версією є наступна:
!pip3 install torch==2.1.0+cu118 torchvision==0.16.0+cu118 torchaudio===2.1.0+cu118 -f https://download.pytorch.org/whl/cu118/torch_stable.html --userLabelling
Нажаль, пришвидшити лейблування доволі складно, тому приготуйтеся, що цей процес буде нудним та довгим. Існують декілька програм для лейблування, найкраща у використанні, як на мене - це makesense.ai, єдиний недолік - неможливість створювати та зберігати проекти, щоб продовжити лейблування з того місця, на якому закінчили, якщо ви закрили сайт, доведеться починати спочатку.
Коректне виділення рамки об’єкта є надважливим, оскільки напряму впливає на якість моделі. Я користуюся наступним принципом: об’єкт у рамці повинна мати змогу ідентифікувати і людина. Наприклад, f minor та g minor відрізняються тільки фретом, на якому знаходяться, тому для цих акордів виділяла кисть та частину грифу: f minor знаходиться на першому фреті, тому його можна швидко ідентифікувати за головкою грифа:
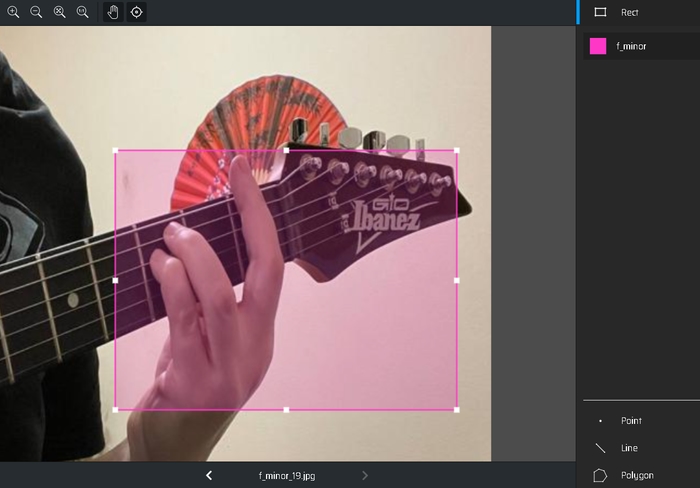
Швидкий гайд для початку:
З головної сторінки перехід до панелі через Get Started.
Обираєте файли, які потрібно лейблувати та натискаєте “Object Detection”
Для наступного кроку рекомендую підготувати .txt файл з назвами класів (новий клас з нового рядка), який допоможе автоматично створювати класи, замість ручного введення.
Завантаження назв класів Виділення постановки руки на кожній фотографії та лейблування відповідним класом.
Список класів Після завершення, імпорт як формат YOLO через Export Annotations.
Експорт аннотації
У zip файлі міститься 420 текстових файлів, кожен з яких у свою чергу має номер класу та розташування рамки об’єкта, що належить цьому класу.
Створення YAML файлу
YAML файл містить визначення кожного класу - порядковий номер, саме цей номер є в текстових файлах, отриманих після лейбелінгу. Згідно нової документації YOLO файл має виглядати наступним чином:
Послідовність класів повинна бути така ж, як у класів, які використовувалися при лейблуванні: a_major - 0 клас, тобто перший у списку класів y makesense.ai.
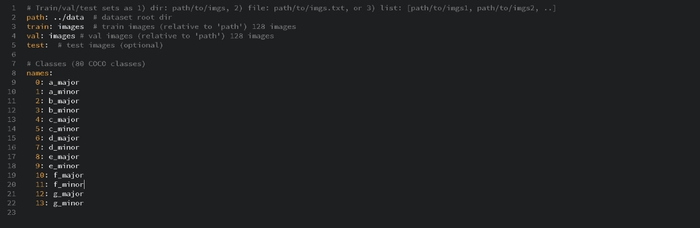
Ура! Дані підготовлені і можна починати навчання. Але перед цим, хочу звернути увагу на розташування файлів. Моя основна папка - Object_Detection, в якій розташовані 2 необхідні папки: data ( в ній міститься датасет) та yolov5 (з компонентами YOLO та інформацією про тренування).
Папка data містить папку images - в ній знаходяться усі фотографії та папку labels з текстовими файлами, отриманими після лейблування.
Файл custom.yaml знаходиться у папці data у yolov5: …\Object_Detection\yolov5\data\custom.yaml
На що потрібно звернути увагу перед навчанням
Чи імпортовані необхідні бібліотеки
Чи id класів у тектових файлах збігаються з id класів у .yaml файлі
Чи встановлений torch вірно: для перевірки версії:
torch. __version__. Навчання
Для запуску навчання необхідно ввести тільки одну строчку коду (яка може призвести до неприємних проблем, описаних нижче)
!cd yolov5 && python train.py --img 640 --batch 16 --epochs 400 --data custom.yaml --weights yolov5s.pt --workers 2!cd yolov5 - папка, де розташоване YOLO
python train.py - файл тренування моделі
img 640 - розмір зображення
batch 16 - кожен батч містить 16 зображень
epochs 400 - навчання тривалістю 600 епох
data custom.yaml - розташування та назва yaml файлу
workers 2 - скільки “потужностей“ буде використовуватися для навчання.
Якщо ви не впевнені, чи йде навчання на GPU, можна призначити вручну:
torch.cuda.set_device(0)На GTX 1050 Tі навчання тривало близько 3х годин.
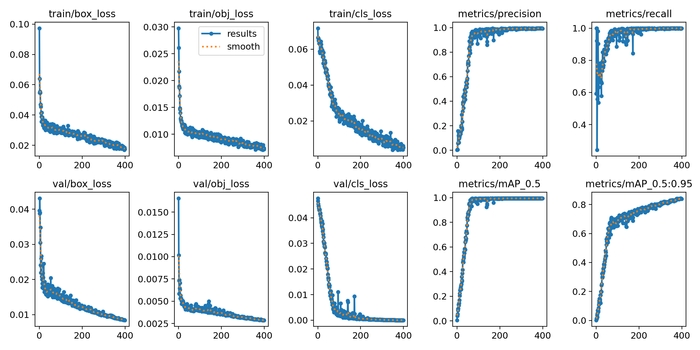
Після завершення навчання у папці yolov5/runs/train/exp1 (номер експерименту = кількості запусків навчання) знаходяться ваги моделі та метрики, які можна вивести як графіки:
from utils.plots import plot_results
plot_results('yolov5/runs/train/exp29/results.csv')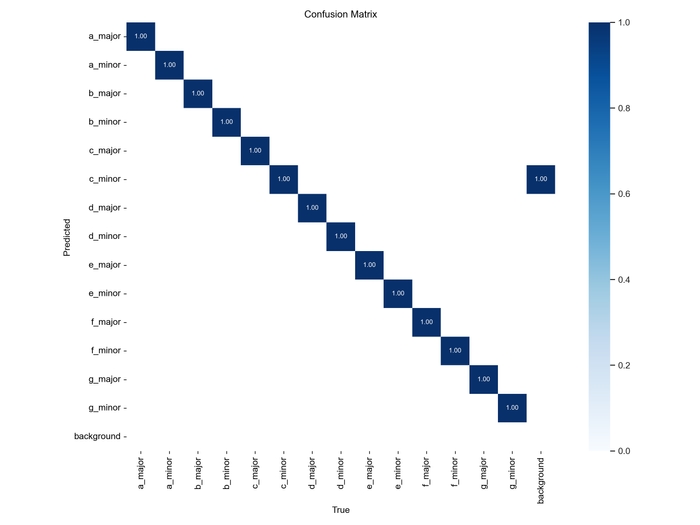
model = torch.hub.load('ultralytics/yolov5', 'custom', path='yolov5/runs/train/exp29/weights/last.pt', force_reload=True) - завантажує ваги у модель, яку потім можна використовувати. Передбачення у лайфстрімі можна зробити, використавши попередній код.
Як видно на превью на початку статті, класифікація доволі точна для учбового проєкту, але, звичайно, модель все ще недонавчена через маленький датасет, який не включає багато видів фотографій.
Баги при навчанні
SSL: CERTIFICATE_VERIFY_FAILED може бути пов’язано з помилкою завантаження шрифта Arial (так, мені теж було смішно). Вирішення бага описано тут: https://github.com/ultralytics/yolov5/issues/12306
IOPub data rate exceeded. The notebook server will temporarily stop sending output
Цей баг був виправлен у релізі 5.2.2, але якщо він все ж виникнув, мені допомогло збільшення рейту у файлі конфігурації https://stackoverflow.com/questions/43288550/iopub-data-rate-exceeded-in-jupyter-notebook-when-viewing-image
Що далі?
Не однією гітарою єдині. Бас, укулеле, 12-ти струнна гітара та інші музичні інструменти - для них теж можна створити власні нейромережі. Мені було дуже цікаво працювати з таким проєктом, а Вам сподіваюсь читати. Побачимося наступного разу!

