Вітаю, мене звати Олег і я цікавлюсь ШІ-генерацією зображень. Нещодавно мій алгоритм XFutuRestyle привернув увагу OpenAI, а результати його роботи потрапили на міжнародну виставку цифрового мистецтва. І зараз я розповім, як це сталось.
Як з’явився XFutuRestyle
Почав експериментувати з новими візуальними ефектами ще на Bing Image Creator, коли він був на DALL-E 2, і з виходом DALL-E 3 почав відкривати ще цікавіші можливості.
Переломний момент настав, коли OpenAI випустили GPTs — ось тоді я знайшов новий спосіб створювати зображення з декількох фото.
Щоправда, реалізація такої технології виявилась доволі складною і я кожного дня проводив тести, поступово налаштовуючи алгоритм і мінімізуючи кількість помилок. Кожна ітерація налаштування містила три етапи:
Специфічні вимоги до аналізу зображення. Кожне наявне зображення потрібно аналізувати окремо перед створенням нового. Це вимагає точного і ретельного вивчення властивостей зображення, щоб забезпечити відповідність майбутнього зображення даним вимогам.
Точне слідування інструкціям. Алгоритм має точно слідувати наданим інструкціям, що робить процес розробки і тестування більш тривалим і складним, оскільки кожна маленька деталь має велике значення.
Постійне тестування і налаштування. Оскільки алгоритм складний і має багато нюансів, необхідно проводити численні тести для забезпечення його стабільності та відповідності очікуванням. А через те, що фото можуть бути зовсім не сумісні, то результат може бути дуже непередбачуваним
Зрештою, я розробив алгоритм XFutuRestyle, який здатний автоматично поєднати до чотирьох фото або зображень.
Ось як це працює:
завантажується декілька зображень;
кожне зображення аналізується і на основі вхідних даних створюється дуже складна підказка;
після цього на основі цієї підказки створюється зображення з поєднанням всіх елементів. Таке поєднання виявляється доволі складним, тому DALL-E 3 не завжди може його відтворити.
Інтерфейс розробника GPT і приклад успішного тесту
Такий вигляд має інтерфейс розробника, розділений на два вікна. В першому вікні задаються інструкції для керування GPT, навчання моделі та відладка, а в другому — відбувається тестування внесених змін.
Знизу є можливість завантажити свою базу даних і також залучити використання вебпошуку, DALL-E та інтерпретатор коду, який також дає можливість виконувати аналіз даних з комп’ютерним баченням.
Ось один з успішних тестів алгоритму:
Так виглядає результат перенесення і трансформації об’єктів з трьох фото:
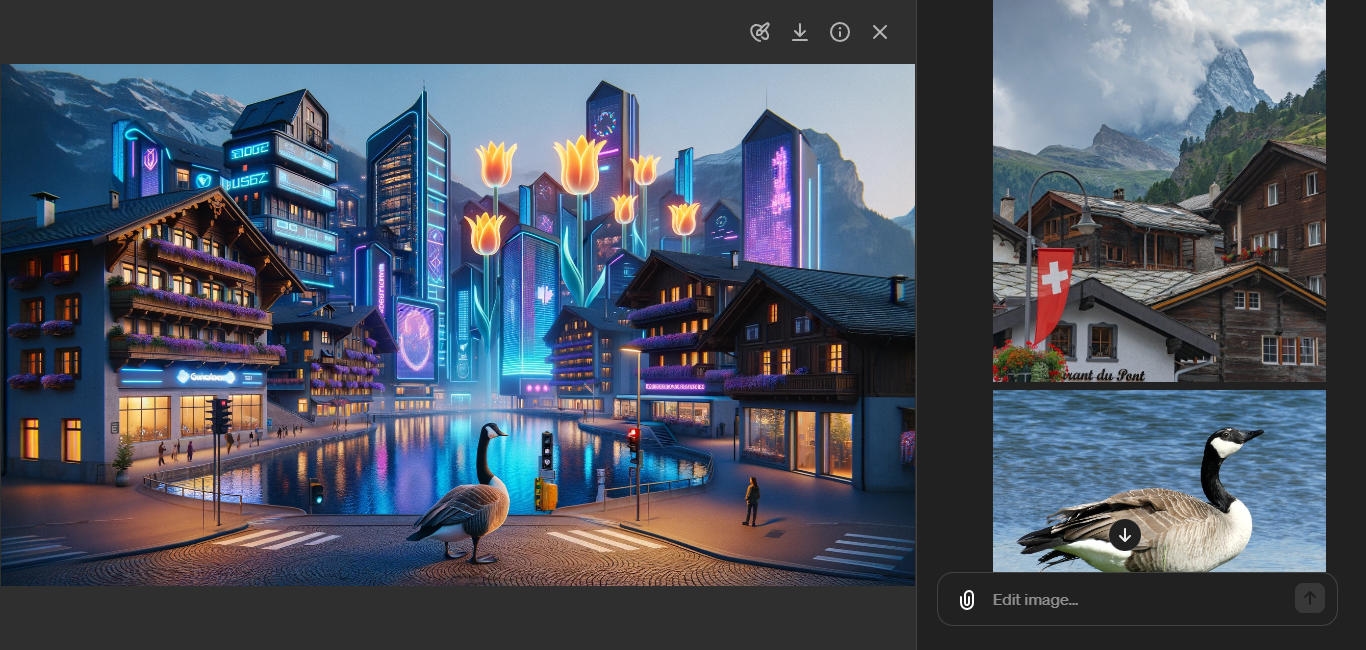
Сенс в тому, що з мінімальної кількості вхідних даних створюється багатошарова складна сцена.
Процес побудови сцени може навіть в дечому нагадувати Sora (цей метод реалізував, коли Sora ще не було навіть анонсовано) у створенні зображень для прикладу як ось тут. Тобто всі елементи вписуються оптимально в сцену.
Переваги, які дозволяє отримати цей метод: отримання тимчасових датасетів на основі вхідних даних, імітація творчого мислення шляхом створення неймовірної кількості комбінацій під час аналізу.
Промт
Якщо казати про побудову промту, то ось наскільки складний вдалось створити запит всього з трьох фото:
Ширококутний абстрактний футуристичний міський пейзаж у сутінках з високою роздільною здатністю, що поєднує індустріальну сутність пивоварні з органічними елементами природи та величним заходом сонця. Візуалізуйте великі металеві резервуари та трубопроводи, пронизані природною, свіжою зеленню, та яскраві, теплі відтінки західного неба, що відбиваються на їхніх поверхнях. Інтегруйте індустріальні та органічні компоненти, створюючи наповнену неоновим світлом сцену, що втілює злиття технологій та природи. Вся сцена освітлена висококонтрастним світлом, що підкреслює текстури та матеріали, відкидаючи довгі, драматичні тіні та сяйво відблисків, які створюють відчуття глибини та складності. Додайте нотку абстракції до деталей, розмиваючи межі між природним і штучним, з небом, що переходить від ясного заходу сонця до зоряної ночі, пропонуючи плин часу в одному кадрі.

Виставка Art On LOOP і реакція OpenAI
Ідея виникла, коли я пробував поєднувати зображення і мені раптово стало цікаво: а якщо спробувати поєднати аж елементи з чотирьох фото?
Сонце + акула + східна архітектура + потяг, що їде через міст = результат, що перевершив всі очікування.
Одного разу я натрапив на відео під назвою «Твори мистецтва, створені штучним інтелектом, показали в Гонконгу» — саме тоді я почав дуже активно працювати, втілюючи свою ідею в реальність.
Знайшов виставку, яка пропонує інноваційний формат — це перше у світі представлення зображення на екрані відразу у двох країнах, і мене це зацікавило. Відправив зображення організаторам та отримав відповідь: «Ваш винятковий талант вразив нас, і ми з радістю продемонструємо вашу роботу». Так я потрапив на стіни виставки Art On LOOP. London — Athens.
Моя картина, яка поєднувала одразу чотири фотографії з різним сюжетом, виглядає ось так:

А ось відповідь, яку я отримав від OpenAI ще в березні 2024:
Справді надихає чути про досягнення України у створенні зображення за допомогою GPT-4, яке було визнано на міжнародній виставці цифрового мистецтва в Лондоні. Відзначення таких інноваційних застосувань технології штучного інтелекту не тільки підкреслює творчий потенціал цих інструментів, а й демонструє талант і стійкість спільнот по всьому світу, включаючи значний внесок України.
У OpenAI ми завжди раді бачити різноманітні та ефективні способи використання наших технологій. Визнання таких досягнень не тільки підтримує залучені спільноти, але й відповідає нашій місії — забезпечити, щоб штучний інтелект приносив користь усьому людству. Хоча ми не можемо взяти на себе зобов’язання щодо конкретних рекламних акцій, ми глибоко цінуємо вашу пропозицію та обов’язково розглянемо, як ми можемо підтримати й відзначити досягнення користувачів з усього світу, в тому числі з України.
Ми прагнемо вивчити способи посилення таких історій, визнаючи цінність, яку вони приносять громаді та світу в цілому. Ще раз дякуємо за вашу пропозицію та висвітлення досягнень України. Для нас велика честь відігравати роль у творчих та інноваційних починаннях світової спільноти.
Висновок
ому я взявся створювати настільки складний проєкт? Бо мені було цікаво, як можна отримувати з простих безкоштовних фото цікаві зображення. В процесі я зрозумів, що маю можливості продемонструвати, що Україна дійсно може вийти на новий якісний рівень у сфері ШІ за міжнародними стандартами навіть під час війни.
Постійно вивчав можливості й обмеження DALL-E, GPT-4, щоб мати можливість це реалізувати хоч і не зовсім стабільно. По суті, я намагався створити дуже потужний бенчмарк для DALL-E 3. Це все я намагався реалізувати самостійно після суттєвого життєвого потрясіння. Саме так, виходить що коли багато чого втратив це і послужило причиною створення інноваційного рішення, яке змогло привернути увагу OpenAI до України.
Над чим працюю зараз?

На даний момент працюю над ШІ системою адаптивного дизайну на базі GPT. Яка дозволить завдяки AI алгоритму, з одного фото досягати 2 мільйонів, і в майбутньому теоретично декілька мілярдів візуальних комбінацій, лише з одного набору даних! Це все буде працювати за рахунок зміни внутрішньої структури вхідних даних.
Тому дуже потрібна ваша підтримка.

