Гіперболічне дисконтування - зменшення цінності винагороди по мірі збільшення її віддаленості в часі. Простіше кажучи, ми надаємо перевагу отримати 100$ тут і зараз, ніж 120$ через рік. Або обираємо з'їсти декілька тістечок зараз, а не хорошу фігуру літом.

Вперше явище гіперболічного дисконтування задокументував американський вчений Б.Ф. Скіннер в процесі експериментів над голубами. В своїх дослідженнях вчений нагороджував тварин їжею за різні дії, такі як натискання на важіль, чи клювання кнопок. З часом дослідник помітив, що в ситуації коли тварина отримує нагороду не відразу, а через деякий час вона набагато довше вчиться. І що загалом нагороди віддалені в часі менше впливають на поведінку.
Один із послідовників Скіннера Говард Рахлін провів експеримент в якому помістив до клітки тварини два важелі:
А - важіль, який видавав одну гранулу корму відразу
В - важіль натискаючи на який голуб отримував дві гранули, але через чотири секунди
Як і очікувалося тварина обирала більше тут і зараз натискаючи на важіль А. Схожі закономірності справедливості і для людей, з поправкою на те, що люди приблизно в сорок разів менш чутливі до гіперболічного дисконтування, ніж голуби.
Поведінкові економісти Деніал Канеман та Річард Таллер вирахували, що цінність винагороди падає приблизно на 10% зі збільшенням кількості очікування на один проміжок часу.
Що цікаво, люди не є найбільш терплячим видом. Ворони та папуги можуть терпляче чекати нагороди в два, або три рази більше, ніж люди.
А як же із самоконтролем?
Вищезгаданий дослідник Говард Рахлін провів ще одне дослідження де до вже знайомих нам важелів А та В додав третій важіль С. Важіль С не давав ніякої винагороди, його єдиною функцією було блокувати важіль А (той який давав швидку винагороду). Як не дивно, але голуб швидко вчився позбавлятися короткострокових заохочень задля більш вагомих винагород в майбутньому.
Наші рішення змінюються з часом.
Подальші дослідження виявили, що дія часової затримки залежить від загальної кількості часу очікування. Якщо нас помістити в "ситуацію 1" запропонувати сто гривень зараз, або сто десять через тиждень, ми оберемо сто відразу. Проте, в умовах "ситуації 2" де нам пропонують сто гривень через тридцять днів, або сто десять через тридцять сім днів. Ми оберемо другий варіант. Тиждень, який був вирішальним в першому випадку не зіграв такої ролі в другому.
Через цю закономірнісь нам важко передбачити свої дії в майбутньому та діяти згідно планів. Уявимо що, ми лягаємо спати і накручуємо будильник, щоб не запізнитися на співбесіду. Зараз, коли до співбесіди та моменту коли потрібно прокинутися ще багато часу ми обираємо саме піти на співбесіду, а не поспати ще годину. В момент накручування будильника ми знаходимося в "ситуації 1". Інакше кажучи ми обираємо між поспати лишню годину через вісім годин і піти на співбесіду через дев'ять.
Однак, коли ми прокидаємось зранку ми опиняємось в "ситуації 2", де обираємо поспати лишню годину тут і зараз та піти на співбесіду через годину. І як наслідок наше рішення змінюється.
Вчені навіть вивели рівняння для опису цього явища. Формула і приклад розрахунків зображені на картинці нижче.
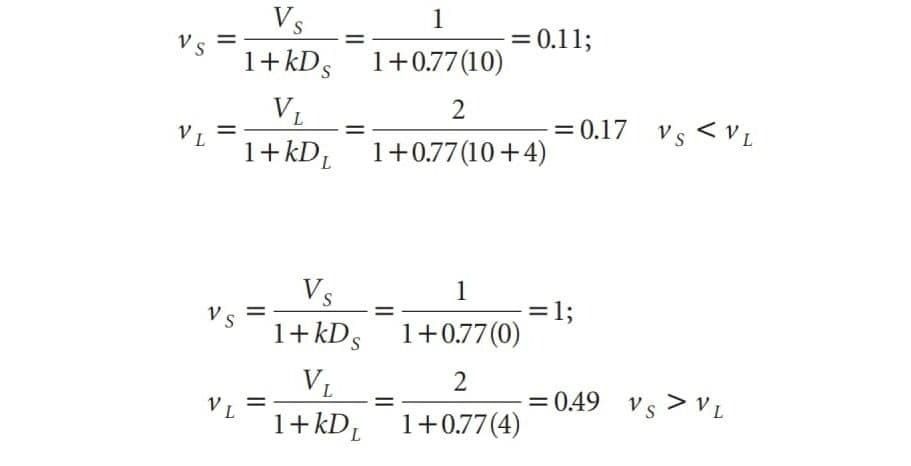
v - дисконтована цінність нагороди в даній ситуації
V - не дисконтова абсолютна цінність
D - час затримки
k - сталий коофіцієнт (0,77)

