Метод Array.prototype.sort був серед останніх вбудованих можливостей, реалізованих у власному JavaScript усередині V8. Перенесення його дало нам змогу експериментувати з різними алгоритмами та стратегіями реалізації та, нарешті, зробити його стабільним у V8 v7.0 і Chrome 70.
Цей переклад виконано для потреб проєкту webdoky.org – українського перекладу документації MDN Web Docs. Приходьте до нас у робочий чат Webdoky, беріть участь у обговореннях адаптації термінів, а може й самі перекладайте, вичитуйте готові тексти, беріться за розвиток функціональності сайту.
Передумови
Сортування на JavaScript – це важко. Цей допис розглядає деякі особливості взаємодії між алгоритмом сортування та мовою JavaScript, а також описує наш шлях переходу V8 до стабільного алгоритму та більш передбачуваної продуктивності.
Порівнюючи різні алгоритми сортування, аналізують їх найгіршу та середню продуктивність, вказану в вигляді асимптотичного зростання (тобто нотації «Великого O») кількості операцій з пам'яттю або порівнянь. Зверніть увагу, що у динамічних мовах, таких як JavaScript, операція порівняння зазвичай в декілька разів дорожча за звертання до пам'яті. Це пов'язано з тим, що порівняння двох значень під час сортування зазвичай включає виклики користувацького коду.
Погляньмо на простий приклад сортування декількох чисел у порядку зростання на основі функції порівняння, наданої користувачем. Послідовна функція порівняння повертає -1 (або будь-яке інше від'ємне значення), 0 або 1 (або будь-яке інше додатне значення), коли два надані значення менші, рівні або більші одне одного, відповідно. Функція порівняння, яка не відповідає цьому шаблону, є непослідовною і може мати які завгодно побічні ефекти, такі як зміна масиву, який вона повинна була б упорядковувати.
const array = [4, 2, 5, 3, 1];
function compare(a, b) {
// Сюди – довільний код, наприклад, `array.push(1);`.
return a - b;
}
// "Типовий" виклик sort.
array.sort(compare);Навіть у наступному прикладі можуть відбуватися виклики користувацького коду. "Усталена" функція порівняння викликає на обох значеннях toString – і виконує над рядковим представленням лексикографічне порівняння.
const array = [4, 2, 5, 3, 1];
array.push({
toString() {
// Сюди – довільний код, наприклад, `array.push(1);`.
return "42";
},
});
// Сортувати без функції порівняння.
array.sort();Ще більше веселощів з аксесорами та взаємодією з ланцюгом прототипів
Це та частина, в якій ми залишаємо специфікацію позаду і прямуємо в край «визначеної реалізацією» поведінки. У специфікації є цілий перелік умов, які, якщо вони виконуються, дозволяють рушієві сортувати об'єкт чи масив так, як він вважає за потрібне – або взагалі не сортувати. Рушії, так чи інакше, повинні дотримуватися певних основних правил, але все інше практично підвішено в повітрі. З одного боку, це дає розробникам рушіїв змогу експериментувати з різними реалізаціями. З іншого боку, користувачі очікують певної адекватної логіки, навіть якщо специфікація не вимагає її. Це ускладнюється тим, що «адекватну логіку» не завжди просто сформулювати.
Цей розділ демонструє те, що досі є певні аспекти Array#sort, в яких поведінка рушіїв сильно відрізняється. Є важкі крайові випадки, і, як зазначено вище, не завжди ясно, що ж насправді є «правильним». Ми наполегливо рекомендуємо не писати код таким чином; рушії не оптимізують таке.
Перший приклад демонструє масив з кількома аксесорами (тобто гетерами та сетерами) і «журналом викликів» у різних рушіях JavaScript. Аксесори – це перша ситуація, коли порядок сортування – визначений реалізацією:
const array = [0, 1, 2];
Object.defineProperty(array, "0", {
get() {
console.log("get 0");
return 0;
},
set(v) {
console.log("set 0");
},
});
Object.defineProperty(array, "1", {
get() {
console.log("get 1");
return 1;
},
set(v) {
console.log("set 1");
},
});
array.sort();Ось вивід цього фрагменту коду у різних рушіях. Зверніть увагу, що тут немає «правильних» чи «неправильних» відповідей – специфікація залишає це на розсуд реалізації!
// Chakra
get 0
get 1
set 0
set 1
// JavaScriptCore
get 0
get 1
get 0
get 0
get 1
get 1
set 0
set 1
// V8
get 0
get 0
get 1
get 1
get 1
get 0
#### SpiderMonkey
get 0
get 1
set 0
set 1Наступний приклад демонструє взаємодію з ланцюжком прототипів. Задля стислості ми не показуємо журнал викликів.
const object = {
1: "d1",
2: "c1",
3: "b1",
4: undefined,
__proto__: {
length: 10000,
1: "e2",
10: "a2",
100: "b2",
1000: "c2",
2000: undefined,
8000: "d2",
12000: "XX",
__proto__: {
0: "e3",
1: "d3",
2: "c3",
3: "b3",
4: "f3",
5: "a3",
6: undefined,
},
},
};
Array.prototype.sort.call(object);Вивід демонструє об'єкт після сортування. Знову таки, тут немає правильної відповіді. Цей приклад просто демонструє, наскільки дивною може бути взаємодія між індексованими властивостями та ланцюжком прототипів:
// Chakra
['a2', 'a3', 'b1', 'b2', 'c1', 'c2', 'd1', 'd2', 'e3', undefined, undefined, undefined]
// JavaScriptCore
['a2', 'a2', 'a3', 'b1', 'b2', 'b2', 'c1', 'c2', 'd1', 'd2', 'e3', undefined]
// V8
['a2', 'a3', 'b1', 'b2', 'c1', 'c2', 'd1', 'd2', 'e3', undefined, undefined, undefined]
// SpiderMonkey
['a2', 'a3', 'b1', 'b2', 'c1', 'c2', 'd1', 'd2', 'e3', undefined, undefined, undefined]Що V8 робить до та після сортування
Примітка: Цей розділ оновлено в червні 2019 року, щоб відповідати змінам у перед- та післяобробці Array#sort у V8 v7.7.
V8 має один крок передобробки, перед тим, як фактично щось сортувати, та один крок післяобробки. Основна ідея полягає в тому, щоб зібрати всі значення, крім значень undefined, у тимчасовий список, відсортувати цей тимчасовий список, а потім записати відсортовані значення назад у вихідний масив чи об'єкт. Це звільняє V8 від турбот про взаємодію з аксесорами чи ланцюжком прототипів під час самого сортування.
Специфікація очікує того, що Array#sort даватиме порядок сортування, який можна уявити як розділений на три сегменти:
Усі значення, крім undefined, сортуються згідно з функцією порівняння.
Усі значення undefined.
Усі дірки, тобто відсутні властивості.
Фактично алгоритм сортування повинен застосовуватися лише до першого сегменту. Щоб цього досягнути, V8 має крок передобробки, який працює приблизно так:
Нехай length матиме значення властивості "length" масиву або об'єкта, що сортується.
Нехай numberOfUndefineds (число значень undefined) буде 0.
Для кожного value (елемента-значення) в діапазоні [0, length):
a. Якщо value – це дірка: нічого не робити
b. Якщо value – це undefined: збільшити numberOfUndefineds на 1.
c. Інакше – додати value до тимчасового списку elements.
Після виконання цих кроків усі значення, крім undefined, уміщені в тимчасовому списку elements. Значення undefined просто перераховуються, а не додаються в elements. Як зазначено вище, специфікація вимагає, щоб undefined були відсортовані в кінець. За винятком того, що значення undefined фактично не передаються до функції порівняння, наданої користувачем, тому можна обійтися лише підрахунком кількості undefined, які зустрілися.
Наступний крок – фактичне сортування elements. Дивіться докладний його опис у розділі про Timsort.
Після завершення сортування відсортовані значення повинні бути записані назад у вихідний масив або об'єкт. Крок післяобробки складається з трьох фаз, які обробляють концептуальні сегменти:
Записати назад усі значення з elements у вихідний масив чи об'єкт у діапазоні [0, elements.length).
Присвоїти усім елементам з діапазону [elements.length, elements.length + numberOfUndefineds) значення undefined.
Видалити всі значення в діапазоні [elements.length + numberOfUndefineds, length).
Крок 3 необхідний у тому випадку, коли вихідний об'єкт містить дірки в діапазоні, що сортується. Значення в діапазоні [elements.length + numberOfUndefineds, length) уже перенесені наперед, і невиконання кроку 3 призвело б до дублювання значень.
Історія
Методи Array.prototype.sort і TypedArray.prototype.sort покладалися на одну й ту саму реалізацію швидкого сортування, написану на JavaScript. Сам алгоритм сортування – доволі прямолінійний: його основою є швидке сортування, з сортуванням включенням як запасним варіантом для коротких масивів (з довжиною до 10). Варіант сортування включенням також застосовується, коли рекурсія швидкого сортування доходить до довжини підмасиву, меншої ніж 10. Сортування включенням більш ефективно для коротких масивів. Це пов'язано з тим, що швидке сортування при розділенні викликається двічі. Кожний такий рекурсивний виклик має накладні витрати на створення (і видалення) стекового фрейму.
Вибір підхожого опорного елемента має великий вплив, коли мова про швидке сортування. V8 узяв на озброєння дві стратегії:
Опорник вибирається як медіана першого, останнього та третього елементів у підмасиві, що сортується. У малих масивах цей третій елемент – це просто середній елемент.
У великих масивах береться вибірка, потім вона сортується, і медіана відсортованої вибірки служить третім елементом в обчисленні вище.
Одна з переваг швидкого сортування – те, що цей алгоритм сортує на місці. Накладні витрати щодо пам'яті спричинені виділенням невеликого масиву для вибірки при сортуванні великих масивів, а також стекового простору log(n). Недолік полягає в тому, що це нестабільний алгоритм, і є шанс, що він дійде до найгіршого сценарію, коли швидке сортування деградує до 𝒪(n²).
Знайомтеся – V8 Torque
Як завзятий читач блогу V8, ви, можливо, вже чули про CodeStubAssembler ("складач заглушок коду"), скорочено – CSA. CSA – це компонент V8, що дає змогу писати низькорівневе IR (проміжне представлення) TurboFan безпосередньо на C++, яке потім перекладається на машинний код для відповідної архітектури за допомогою бекенду TurboFan.
CSA потужно використовується для написання так званих «швидких шляхів» для вбудованих можливостей JavaScript. Версія вбудованої можливості зі швидким шляхом зазвичай перевіряє, чи виконуються певні інваріанти (наприклад, немає елементів у ланцюжку прототипів, немає аксесорів тощо), а потім використовує швидші, більш конкретні операції для реалізації можливості. Це може призвести до часу виконання, що в десятки разів швидше, ніж у більш загальної версії.
Недолік CSA полягає в тому, що він насправді не може вважатися асемблерною мовою. Контроль потоку моделюється за допомогою явних міток та переходів, що робить реалізацію складніших алгоритмів у CSA важкою для читання та проблемною щодо помилок.
Знайомтеся – V8 Torque ("момент сили", "момент руху"). Torque – це мова спеціального призначення із синтаксисом, схожим на TypeScript, яка наразі використовує CSA як єдину ціль компіляції. Torque дає майже той самий рівень контролю, що й CSA, але водночас пропонує більш високорівневі конструкції, такі як цикли while і for. Крім того, вона має сильну типізацію й у майбутньому буде містити перевірки безпеки, такі як автоматичні перевірки виходу за межі, що дасть інженерам V8 сильніші гарантії.
Перші ключові вбудовані можливості, що були переписані на V8 Torque, – TypedArray#sort і операції Dataview. І перше, і друге служили також для надання зворотного зв'язку розробникам Torque щодо того, які можливості потрібні цій мові та які ідіоми слід використовувати для ефективного написання вбудованих можливостей. На момент написання цього допису декілька вбудованих можливостей JSArray мали запасні власні реалізації на JavaScript, перенесені на Torque (наприклад, Array#unshift), а інші – повністю переписані на Torque (наприклад, Array#splice та Array#reverse).
Перенесення Array#sort на Torque
Вихідна версія Array#sort на Torque була більш-менш прямолінійним перенесенням реалізації з JavaScript. Єдиною відмінністю було те, що замість вибіркового підходу для великих масивів третій елемент для обчислення опорного елемента вибирався випадковим чином.
Це працювало доволі добре, але оскільки все одно використовувалось швидке сортування, Array#sort залишався нестабільним. Запит на стабільність Array#sort – серед найстаріших карток у трекері вад V8. Експерименти з Timsort як наступним кроком дали нам кілька переваг. По-перше, нам подобається, що алгоритм Timsort стабільний і надає деякі приємні алгоритмічні гарантії (див. наступний розділ). По-друге, мова Torque іще була в розробці, і реалізація складнішої вбудованої можливості, штибу Array#sort з Timsort, призвела до багатьох корисних відгуків, що вплинули на Torque як мову.
Timsort
Timsort, спершу розроблений Тімом Петерсом для мови Python у 2002 році, найкраще може бути описаний як адаптивна стабільна варіація сортування злиттям. Навіть попри те, що подробиці – доволі складні, вони найкраще описані самим автором, а також на сторінці у Вікіпедії, основи цього алгоритму – легкі для розуміння. Коли сортування злиттям працює в рекурсивний спосіб, Timsort працює ітеративно. Він обробляє масив зліва направо та шукає так звані перегони. Перегін – це просто послідовність, що вже відсортована. Це включає послідовності, що відсортовані «неправильним» чином, оскільки їх можна просто розвернути – й утворити перегін. На початку процесу сортування визначається мінімальна довжина перегону, що залежить від довжини вхідного масиву. Якщо Timsort не може знайти природні перегони цієї мінімальної довжини, перегін «штучно підсилюється» за допомогою сортування включенням.
Перегони, знайдені в такий спосіб, відстежуються за допомогою стека, що пам'ятає індекс початку та довжину кожного перемогу. Час від часу перегони на стеку зливаються разом, поки не залишиться лише один відсортований перегін. Timsort намагається підтримувати баланс, коли мова йде про визначення того, які перегони зливати. З одного боку, варто намагатися зливати рано, оскільки дані цих перегонів з високою ймовірністю вже є в кеші, з іншого боку, варто зливати якомога пізніше, щоб скористатися виявленими у даних патернами. Для досягнення цього Timsort підтримує два інваріанти. Припускаючи, що A, B та C – це три перегони найвищого рівня:
|C| > |B| + |A|
|B| > |A|
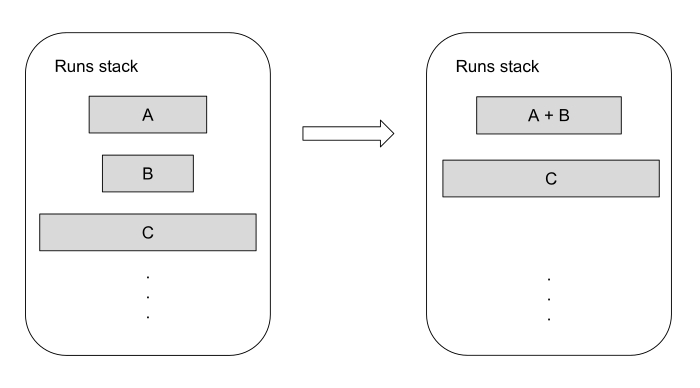
Зображення вище демонструє випадок, коли |A| > |B|, тож B зливається з меншим з двох перегонів.
Зверніть увагу на те, що Timsort зливає лише сусідні перегони; це необхідно для підтримання стабільності, бо інакше рівні елементи переставлялися б місцями. Крім цього, перший інваріант слідкує, щоб довжини перегонів зростали щонайменше так само швидко, як числа Фібоначчі, що дає верхню межу на розмір стека перегонів, коли відома максимальна довжина масиву.
Тепер видно, що вже відсортовані послідовності сортуються за 𝒪(n), оскільки такий масив дав би єдиний перегін, котрому не потрібно злиття. Найгірший випадок – 𝒪(n log n). Такі алгоритмічні властивості вкупі зі стабільною природою Timsort – серед причин, чому ми вибрали Timsort замість швидкого сортування.
Реалізація Timsort на Torque
Вбудовані можливості зазвичай мають різні кодові шляхи, вибір серед яких виконується під час виконання, залежно від різних змінних. Найузагальненіша версія може обробляти об'єкти будь-якого роду, незалежно від того, чи це JSProxy, чи є в них перехоплювачі, чи потрібен пошук у ланцюжку прототипів при отриманні чи присвоєнні властивостей.
Узагальнений шлях у більшості випадків є доволі повільним, адже повинен враховувати всі можливі випадки. Але якщо заздалегідь відомо, що об'єкт для сортування – це простий JSArray, котрий містить лише малі цілі числа (в оригіналі "smi" – small integer, ціле число, що на 64-бітових платформах лежить в діапазоні від -2^31 до 2^31 - 1 – прим.пер.), то всі ці дорогі операції [[Get]] і [[Set]] можна замінити простими завантаженнями та збереженнями до FixedArray. Основним чинником є ElementsKind (різновид елементів).
Тепер проблема в тому, як реалізувати швидкий шлях. Ключовий алгоритм залишається тим же, але спосіб доступу до елементів змінюється в залежності від ElementsKind. Один зі способів, яким цього можна досягти – це викликати правильний "аксесор" на кожному місці виклику. Уявіть собі оператор switch для кожної операції "завантаження"-"збереження", де обираються різні гілки в залежності від обраного швидкого шляху.
Іще одне рішення (і це був перший підхід, котрий ми спробували) – просто скопіювати всю вбудовану можливість для кожного швидкого шляху та вбудувати коректний метод завантаження та збереження. Цей підхід виявився неможливим для Timsort, адже це великий шмат коду, і створення копії для кожного швидкого шляху, як виявилось, вимагає в сумі 106 КБ, що надто багато для однієї вбудованої можливості.
Остаточне рішення виявилось дещо інакшим. Кожна операція завантаження-збереження для кожного швидкого шляху кладеться до власної "вбудованої мініможливості". Дивіться приклад коду, що демонструє операцію "завантаження" для структури даних FixedDoubleArray (фіксований масив чисел з рухомою комою).
Load<FastDoubleElements>(
context: Context, sortState: FixedArray, elements: HeapObject,
index: Smi): Object {
try {
const elems: FixedDoubleArray = UnsafeCast<FixedDoubleArray>(elements);
const value: float64 =
LoadDoubleWithHoleCheck(elems, index) otherwise Bailout;
return AllocateHeapNumberWithValue(value);
}
label Bailout {
// Крок передобробки прибрав усі дірки, склавши всі елементи
// на початку масиву. Зустріч з діркою означає, що функція cmp або
// ToString змінює масив.
return Failure(sortState);
}
}Для порівняння, найузагальненіша операція "завантаження" – це простий виклик GetProperty. Але хоч версія вище генерує ефективний та швидкий машинний код для завантаження та перетворення Number, однак GetProperty – це виклик іншої вбудованої можливості, що потенційно може включати пошук у ланцюжку прототипів або заклик аксесорної функції.
builtin Load<ElementsAccessor : type>(
context: Context, sortState: FixedArray, elements: HeapObject,
index: Smi): Object {
return GetProperty(context, elements, index);
}Потім швидкий шлях просто стає набором функційних вказівників. Це означає, що потрібна лише одна копія ключового алгоритму, а всі відповідні функційні вказівники готуються наперед. Хоч це суттєво зменшує необхідний кодовий простір (до 20 КБ), це призводить до непрямих розгалужень на кожному місці доступу. Це ще більше погіршується останніми змінами, що використовують вбудовні можливості (в оригіналі “embedded builtins” – прим. пер.).
Стан сортування
Індекс | Вміст комірки |
|---|---|
00 | Отримувач |
01 | Відображення початкового отримувача |
02 | Довжина початкового отримувача |
03 | вказівник на користувацьку JSFunction порівняння |
04 | Вказівник Torque FN на вбудовану можливість “compare” |
05 | Вказівник Torque FN на вбудовану можливість “load” |
06 | Вказівник Torque FN на вбудовану можливість “store” |
07 | Вказівник Torque FN на вбудовану можливість “check” |
08 | Стан аварійного виходу |
09 | min_gallop |
10 | Розмір стека перегонів |
11 | Вказівник на стек перегонів |
12 | Розмір тимчасового масиву |
13 | Вказівник на тимчасовий масив |
14 | Ідентифікатор швидкого шляху |
Таблиця вище демонструє "стан сортування". Це FixedArray (фіксований масив), що відстежує все, що необхідно при сортуванні. Щоразу, коли викликається Array#sort, формується такий стан сортування. Елементи від 4 до 7 – це функційні вказівники, що згадувалися вище, і які утворюють швидкий шлях.
Вбудована можливість "check" (перевірити) вживається щоразу, коли відбувається повернення з користувацького коду JavaScript, аби перевірити, чи можна продовжити виконання на поточному швидкому шляху. Вона використовує для цього "відображення початкового отримувача" та "довжину початкового отримувача". Якщо користувацький код змінив поточний об'єкт, то перегін сортування просто покидається, всі вказівники скидаються на свої якнайбільше узагальнені версії, і процес сортування починається спочатку. Значення "bailout status" (стан аварійного виходу) у комірці 8 використовується для сповіщення про таке скидання.
Запис "compare" (порівняти) може вказувати на дві різні вбудовані можливості. Одна з них викликає передану користувачем функцію порівняння, а друга реалізовує усталене порівняння, котре викликає на обох аргументах toString і виконує лексикографічне порівняння.
Решта полів (окрім ідентифікатора швидкого шляху) – це поля, що властиві Timsort. Стек перегонів (описаний вище) ініціалізується розміром 85, що достатньо для сортування масивів довжиною 2^64. Тимчасовий масив використовується для злиття перегонів. Він збільшується за потреби, але ніколи не перевищує n/2, де n – це довжина вхідного масиву.
Компроміси щодо продуктивності
Перехід сортування від власної реалізації на JavaScript до Torque приніс компроміси щодо продуктивності. Оскільки Array#sort написаний на Torque, він тепер є статично скомпільованим шматком коду, що означає, що ми все ще можемо створювати швидкі шляхи для певних ElementsKind, але він ніколи не буде таким швидким, як високооптимізована версія TurboFan, котра може використовувати зворотний зв'язок типів. З іншого боку, у випадках, коли код є недостатньо гарячим, щоб виправдати компіляцію JIT, або коли місце виклику є мегаморфним, ситуація обтяжується інтерпретатором або повільною та узагальненою версією. Розбір, компіляція та можлива оптимізація власної реалізації на JavaScript – це також накладні витрати, що не потрібні для реалізації на Torque.
Хоч підхід із Torque не призводить до такої ж пікової продуктивності для сортування, він уникає різких падінь продуктивності. Результат – це сортування, що має набагато більш передбачувану продуктивність, ніж раніше. Пам'ятайте, що Torque досі дуже змінюється, і крім того, що він спрямований на CSA, він може спрямовуватися на TurboFan у майбутньому, що дозволить JIT-компіляцію коду, написаного на Torque.
Мікровимірювання
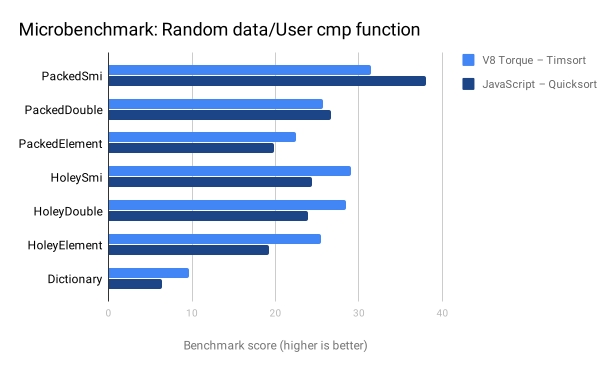
До початку роботи над Array#sort ми додали чимало різних мікровимірювань, щоб отримати краще розуміння впливу, який мала б повторна реалізація. Перша діаграма демонструє "звичайний" варіант використання сортування різних ElementsKind з користувацькою функцією порівняння.
Майте на увазі, що в цих випадках JIT-компілятор може робити чимало, адже сортування – це майже все, що робиться. Також це дозволяє оптимізаційному компілятору вбудовувати функцію порівняння у версію на JavaScript, тоді як у нас є накладні витрати від вбудованої можливості на JavaScript у випадку Torque. А проте, наш варіант працює краще в майже всіх випадках.
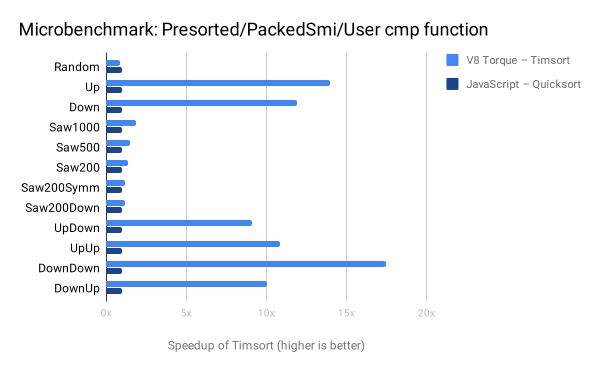
Наступна діаграма демонструє вплив Timsort при обробці масивів, що вже майже повністю відсортовані, або мають всередині послідовності, що вже так чи інакше відсортовані. Ця діаграма використовує швидке сортування як базову лінію та демонструє пришвидшення Timsort (до 17 разів у випадку "DownDown", коли масив містить дві послідовності, відсортовані у зворотному порядку). Як можна помітити, окрім випадку випадкових даних, Timsort більш продуктивний у всій решті випадків, навіть попри те, що сортуються PACKED_SMI_ELEMENTS (запаковані малі цілі числа), для яких швидке сортування виявилося продуктивнішим за Timsort на мікровимірюваннях вище.
Вимірювання на вебінструментах
Вимірювання на вебінструментах - це колекція задач для інструментів, що зазвичай використовуються веброзробниками, наприклад, Babel і TypeScript. Діаграма показує швидке сортування на JavaScript як базову лінію та порівнює з нею пришвидшення Timsort. Майже при всіх вимірюваннях ми зберігаємо ту саму продуктивність, за винятком chai.
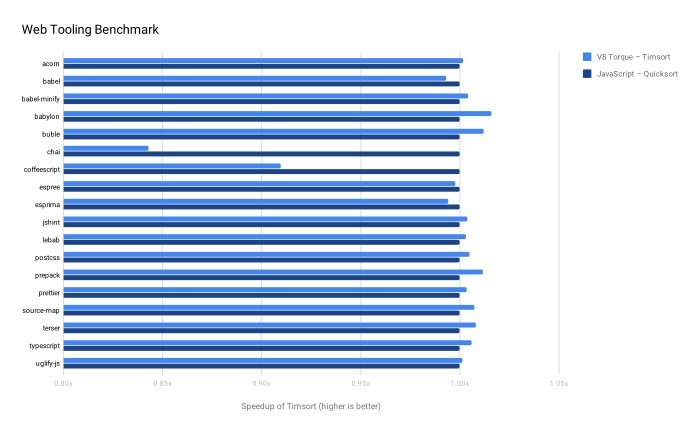
Вимірювання chai витрачає третину свого часу в межах однієї функції порівняння (вимірювання віддаленості рядків). Вимірювання – це набір тестів самого chai. Через такі дані Timsort потребує додаткових порівнянь у цьому випадку, що має більший вплив на загальний час виконання, оскільки така велика частина часу витрачається всередині цієї конкретної функції порівняння.
Вплив на пам'ять
Аналіз знімків купи V8 при перегляді десь 50 сайтів (і на мобільному, і на настільному комп'ютері) не показує жодних регресу чи покращень. З одного боку, це дивує: перехід від швидкого сортування до Timsort призвів до необхідності тимчасового масиву для злиття перегонів, що може зростати набагато більше, ніж тимчасові масиви, що використовуються для вибірок. З іншого боку, ці тимчасові масиви існують дуже короткий час (лише протягом виклику сортування) і можуть бути швидко виділені та відкинуті в новому просторі V8.
Висновок
У підсумку ми почуваємося набагато краще щодо алгоритмічних властивостей та передбачуваної продуктивності Timsort, реалізованого на Torque. Timsort доступний починаючи з V8 v7.0 та Chrome 70. Щасливого сортування!
Автор оригінального тексту – Симон Зюнд, @nimODota.
Оригінальний текст: Getting things sorted in V8, Simon Zünd, 28.09.2018
Цей переклад виконано для потреб проєкту webdoky.org – українського перекладу документації MDN Web Docs. Приходьте до нас у робочий чат Webdoky, беріть участь у обговореннях адаптації термінів, а може й самі перекладайте, вичитуйте готові тексти, беріться за розвиток функціональності сайту.
На цю статтю посилається стаття про Array.prototype.sort().
