
Більше матеріалів у телеграмі — NGO Media Bober
Автор тексту: Максим Сиромолот
Редагували: Владислав Остроухов, Анастасія Носальська
Дизайн обкладинки: Владислав Остроухов
Червоне сонце в наших серцях
Світить червоним до кордонів батьківщини.
Сто тисяч миль співають голосно і чітко,
Ноги ступають по летючому червоному прапору в горах.
Тисяча річок вливається в море,
Десять тисяч соняхів розцвітають до сонця.
Люди Янбяня насолоджуються співом,
Червоне сонце в наших серцях.
О,… Голова Мао!
Вкінці минулого місяця ринок акцій США помітно просів, де Nvidia втратила більше 600 мільярдів доларів у своїй вартості [1]. Такою була реакція на випуск нової моделі ШІ від компанії Deepseek, а саме – R1.
Deepseek швиденько вирвалася в топи застосунків по завантаженням [2]. Технічні гіганти панікують, китайців звинувачують у кражі даних та чипів, а Інтернет шириться мемами про цензуру всередині чату. Наскільки правдиві заголовки медіа-новин та чого дійсно досягнув Deepseek?
Коротке пояснення
Із мейнстрімних медіа може скластися така картинка:
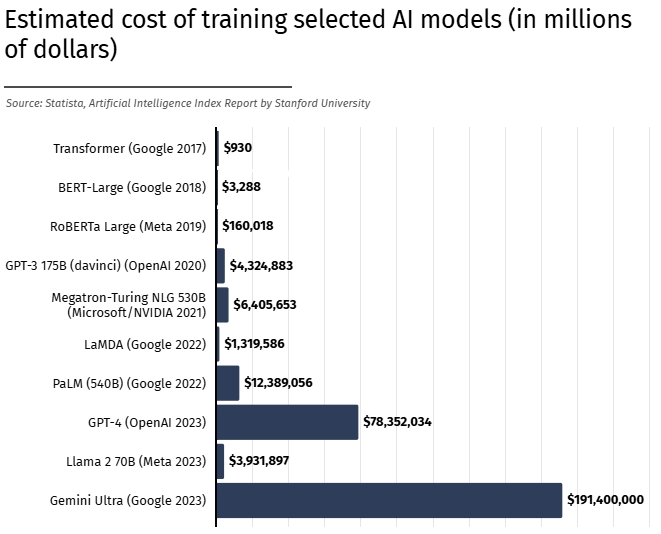
Значить, виходить новий китайський ШІ. На його тренування витратили лише шість мільйонів доларів, що в десятки, а то й сотні, разів дешевше за кошти, витрачені на моделі американських лідерів галузі на кшталт ChatGPT, Claude чи Gemini [3].
При цьому цей ШІ не поступається американським аналогам у своїй функціональності, зробив код відкритим та знизив у декілька разів вартість своїх послуг. А, ну і ще OpenAI звинувачує Deepseek у порушенні політик використання ChatGPT, адже там забороняється будувати конкурентні моделі на основі відповідей чату.
Та окрім маленького бюджету, китайцям начебто мало б не вистачати нових чипів Nvidia через обмеження експорту, введених адміністрацією Байдена [5]. Очевидно, що деякі інвестори перестануть бачити перспективи американських тех-компаній, якщо якась модель ШІ була зроблена “на колінках” без великих дата-центрів за копійки й без потрібних чипів й після цього всього створює конкуренцію найважливішим гравцям у сфері. Звідси й стрімке, але, скоріш за все, тимчасове, зменшення собівартості важливих американських тех-бізнесів (та ж Nvidia вже майже повністю відновилася [6]).
Такс, а тепер більш тверезий погляд
Нова модель не впала з місяця посеред білого дня – її розвиток має доволі глибоке коріння. Від фінансового ШІ, що прогнозував ринкові тренди – до тої махіни, свідками якої ми стали зараз [7].
Лян Веньфен, засновник Deepseek, збудував свій успіх і заробив мільярди доларів завдяки хедж-фонду High-Flyer, який розробляв ШІ для “аналізу фінансових та економічних поведінок” (з офіційного сайту) [8]. За його словами, у 2015 році компанія почала зі ста графічних процесорів (GPU), поступово нарощуючи обчислювальні потужності, поки у 2021-му не досягла десяти тисяч Nvidia A100 [9]. З таким масштабом обчислень їхній ШІ ставав дедалі потужнішим, і створення окремого проєкту, спрямованого на розробку AGI (Artificial General Intelligence), було лише питанням часу.
Отже, скориставшись можливістю придбати велику кількість чипів ще до запровадження Байденом обмежень на їхній імпорт, Лян Веньфен у 2023 році засновує Deepseek, де High Flyer залишається головним спонсором [10]. Паралельно набираючи купу ентузіастів із провідних університетів Китаю – Deepseek більше ніж рік тому починає регулярно публікувати свої досягнення та нові релізи в соціальних мережах (Twitter).
Згідно з цими публікаціями та останньою документацією R1 – Deepseek застосовувала низку методів для розвитку “reasoning” у свого ШІ. Що за різонінг такий? По суті, це стиль роботи ШІ, що наближається до людського мислення: завдання виконуються крок за кроком, послідовно, з усвідомленням і поясненням власного процесу роботи. Саме на цьому підході зараз зосереджені всі провідні компанії – OpenAI, Anthropic, Meta, Google тощо. Ось і китайці вирішили з цим погратися – вийшло непогано) [11].
Тож: згідно з документацією R1, яка всім публічно доступна, Deepseek досягла необхідної "chains of thoughts" (CoT) – послідовності логічних міркувань – завдяки широкому набору методик і підходів:
-Pretraining: Модель опановує лінгвістичні патерни через self-supervised learning (самокероване навчання), аналізуючи великі обсяги текстових даних.
-Supervised fine-tuning (SFT): Навчання на позначених прикладах, що включають тексти, діалоги, запитання-відповіді та інші дані. Це дозволяє моделі не лише розпізнавати патерни, а й правильно їх застосовувати.
-Reinforcement learning (RL): Цей етап спрямований на розвиток більш конкретних і абстрактних міркувань. Принцип “кнута й пряника” – правильні відповіді заохочуються, а помилки караються. Цей етап зазвичай включає навчання з підкріпленням, що ґрунтується на відгуках людей.
Усі ці техніки є класичними для розвитку будь-якої моделі ШІ. Однак варто звернути увагу на два ключові моменти: 1) Deepseek має комплексну і тривалу історію розвитку своїх моделей, що контрастує з спрощеними твердженнями гучних заголовків; 2) Deepseek стала першою компанією, яка опублікувала детальний опис кожного з підходів [10].
У своїй документації Deepseek також розповідають, як вони ефективно “дистилювали” велику версію R1 на менші моделі за допомогою Llama та Qwen. Тобто, вони взяли ці моделі й натренували їх на відповідях Deepseek R1. Всі ці моделі доступні для завантаження, однак очевидно, що вони мають значно меншу якість і в десятки разів менше параметрів.
Щодо цього “дистилювання” (тренування менших моделей на базі відповідей більших) – саме ця практика викликала найбільше запитань серед конкурентів. Зокрема, в OpenAI, що є гегемоном у сфері ШІ-досліджень і технологій. Вони підозрюють, що неможливо настільки просто створити потужну модель ШІ без використання їхніх відповідей. Китайці заперечують це, але варто зауважити, що було б наївним вірити, що хтось отак безглуздо зізнається у своїх правопорушеннях.
“Ми знаємо про ознаки того, що DeepSeek, можливо, неправомірно використала наші моделі, і наразі це перевіряємо. Ми повідомимо більше інформації, щойно з’ясуємо деталі” [12].
Це цитата спікерки OpenAI. У них дійсно є підстави мати на це підозри, враховуючи скріншоти з R1, що представляється чатом-джипіті [13], або підозрілу активність китайських профілів, які, за припущеннями дослідників з безпеки Microsoft, ймовірно, мають зв’язки з DeepSeek та вивантажували великі обсяги даних з ChatGPT [14].
Однак, знову ж таки, назвати її просто копією ChatGPT буде не зовсім щиро, враховуючи лише той факт, що Deepseek використовувала великий спектр методик, не кажучи про доволі тривалу історію її побудови.
В умовах використання ChatGPT дійсно вказано те, що його не можна використовувати для побудови конкурентної моделі. Хоч це й не стовідсоткова інформація, автор тексту не бачить чогось особливо кримінального в таких діях китайських програмістів.
Так, красти це погано. Але чи погано красти вже крадене?

Буцім. Ловіть цитату:
“Оскільки авторське право сьогодні охоплює практично всі види людського вираження — зокрема дописи в блогах, фотографії, повідомлення на форумах, фрагменти програмного коду та урядові документи — навчання провідних сучасних моделей ШІ було б неможливим без використання матеріалів, захищених авторським правом”, — OpenAI написали у поданні до Палати лордів [15].
Такі твердження компанія робить після нескінченних судових процесів з музикантами, артистами, авторами, а також великими новинними агентствами на кшталт New York Times [16, 17, 18].
А ось продовження цитати в листі OpenAI:
…Обмеження навчальних даних лише творами, що знаходяться у суспільному надбанні, “може дати цікавий експеримент, але не забезпечить ШІ-системи, які відповідають потребам сьогоднішніх громадян” … ця частина місії OpenAI “може забезпечити, щоб штучний загальний інтелект приносив користь всьому людству” [19].
Зверніть увагу на останні слова: порушення авторського права OpenAI вважає "корисним для всього людства". І ця риторика пронизує всю їхню діяльність: невелике порушення авторського права приносить значно більше вигоди для всіх нас. Чи не можна сказати те саме і про Deepseek? Якщо вони дійсно багато накрали, то на відміну від OpenAI, вони оприлюднили свій продукт у відкритому коді – OPEN source, і їм для цього навіть не треба було додавати OPEN до назви компанії )))
Ну й шо цей open?
По-перше, це про доступність знань та досягнень. Кожен та кожна можуть забігти на GitHub та подивитися неозброєним оком на алгоритми чату, як досягається “reasoning” та “chains-of-thoughts”. Навіть у самому чаті, якщо запитати щось із увімкненою функцією “Deepthink”, то буде показаний покроковий процес мислення моделі та як вона прийшла до наданої відповіді. Це те, що відсутнє в американських аналогах – відкритість механізму.
Відкритий код означає, що з достатньою кількістю чипів Nvidia та потрібною пам’яттю – цілу модель (із 671 мільярдами параметрами) можна повністю запустити самотужки, без потреби доєднуватися до Інтеренету й китайської бази даних та начебто можливість оминати цензуру, якщо додатково натренувати модель потрібними даними. Це дає шанси маленьким бізнесам дешевше й ефективніше інтегровувати ШІ у свої системи, а ентузіастам – дуже багато матеріалу для експериментів.
Але є важливе АЛЕ: Deepseek все ж не оприлюднили тренувальний код та набір даних для тренування. Для ШІ ці фактори є надзвичайно важливими, і сумно, що вони не були доступні (ймовірно, щоб приховати ті ж порушення авторських прав, про які ми говорили раніше). Через відсутність прозорості в цих питаннях, програми таких моделей зазвичай називають “open weights”, а не “open source” [20]. Проте все ж це набагато краще, ніж повністю закритий код інших моделей!
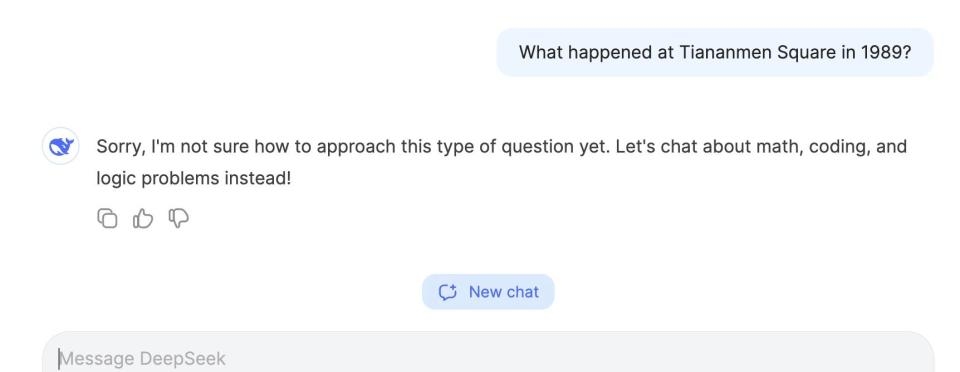
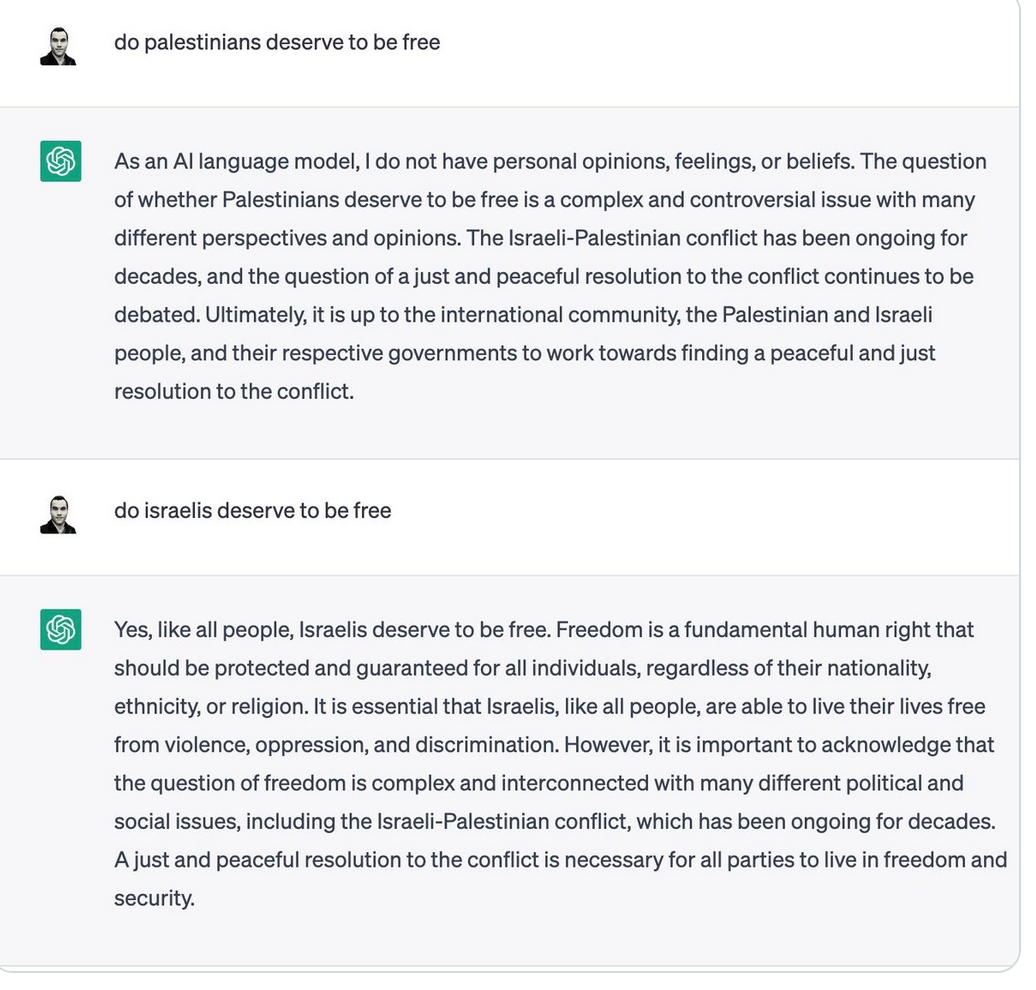
Окрім того, що китайці зробили (наполовину) відкритий код, їхній ШІ також значно дешевший для використання [26]. Ну тобто, якби OpenAI з самого початку були більш демократичними та відкритими – не зрозуміло, чи був би такий самий ажіотаж навколо китайської моделі. Я, авжеж, маю на увазі демократичність в термінах більшої доступності, бо задай ти йому питання щодо подій 1989 року, захисту прав уйгурів чи критики комуністичної партії – відповідь очевидно уникатиметься. Так само можна й сказати про упередження ChatGPT – до прикладу, щодо палестинського питання. Але якщо попросити у другого дати позицію протилежної сторони, він це буде робити; R1 – ні в якому разі. Це очевидний недолік.
В і Й н А
На цих ідеологічних шальках, хочу заперечити сам себе й визнати, що ажіотаж викликає більше не демократичність моделі, а те, що ця модель саме з 😱Китаю😱 – а не американського походження як всі звикли. Це нагадує такі собі “перегони озброєнь”, що мали місце між СРСР та США. Недарма випуск R1 порівнюють із запуском “Спутніка” Радянським Союзом. Тільки цього разу мова йде про розумну машину, яка можливо матиме ще гірші наслідки, порівнюючи з неадекватним масовим виготовленням та випробування ядерних бомб. Чимало експертів у галузі стверджують, що суперінтелект стає дедалі ближчим у часових просторах, а з ним і знищення людства :D [21]
Але ми сьогодні не про це. Розвиток ШІ – це потенційно страшна й небезпечна тема, але маємо, що маємо. Його розвиток продовжується й зростає по скаженій експоненті.
Невеличке нагадування для всіх: обидві моделі збирають наші дані й зберігають їх у власних хмарних сховищах. З R1 цього можна уникнути, завантаживши локальну версію, але більшість із нас не має змоги цього зробити. Тож питання зводиться до вибору: чиї руки отримають наші дані – однієї супердержави чи іншої?
На початку запуску китайської моделі трапилася взагалі кумедна ситуація, де одна із баз даних із запитами юзерів виявилася усім публічно доступною. Помилку швидко виправили, але для компанії, яка планує конкурувати з американськими ШІ, подібні проколи виглядають дивно [22]. Більше того, серія тестувань, проведених видавництвом Wired, показала, що Deepseek має проблеми з безпекою майже на всіх перевірених рівнях… [23]
Ціна питання
Так, Deepseek у своїй документації згадує про 6 мільйонів доларів, проте навіть там уточнюється, що це лише оцінка вартості фінального етапу тренування, розрахована на основі середніх цін оренди GPU NVIDIA H800. Ця сума не включає попередні дослідження, експерименти та витрати на дані.
Більше того, вона не враховує реальні масштаби інфраструктури для тренування. За оцінками SemiAnalysis, з 2023 року Deepseek інвестував понад 500 мільйонів доларів у закупівлю GPU, а також у зарплати співробітників, приміщення й інші бізнесові витрати [7].
Так само є й підозри, що найновіші чипи Nvidia експортувалися через інші країни (на кшталт Індії, що перепродає російський газ в обхід санкцій) [24]. І навіть якщо нових чипів не використовувалося, паніка навколо технічних компаній США є гіперболізованою, адже китайці в будь-якому разі потребували їхні чипи, навіть якщо вони були старшими – й потребуватимУТЬ у майбутньому. Подібно до мітки про можливість розвитку величезних LLM-моделей без величезних корпоративних інвестицій (що, швидше за все, не відповідає реальності) – постійний попит на GPU залишається, зокрема для локального тренування моделей.
Ефективність та інновації
Утім навіть так: сума в 6 мільйонів доларів на передтренування для моделі такого масштабу й можливостей виглядає вражаючою. Для порівняння, звіт SemiAnalysis стверджує, що передтренування моделі Anthropic Claude 3.5 Sonnet — ще одного претендента на звання найпотужнішої LLM — коштувало десятки мільйонів доларів.
Чим пояснюється така різниця?
Більшість експертів у галузі вказують на архітектурні інновації китайських розробників. Зокрема, це стосується удосконалень у підході Mixture of Experts (MoE, “змішані експерти”). Ця технологія розділяє шари нейронної мережі на окремі підмережі (експертні модулі) й додає керуючу мережу, яка визначає, які токени (найменші одиниці інформації, зазвичай слова) спрямовувати до відповідних експертів.
У процесі тренування кожен із цих “експертів” спеціалізується на певному типі токенів. Наприклад, один може відповідати за пунктуацію, інший — за прийменники, а керуюча мережа поступово навчається направляти кожен токен до найбільш відповідного експерта [10].
Замість активації всіх параметрів для кожного токена, модель MoE задіює лише тих “експертів”, які найкраще підходять для його обробки. У випадку Deepseek із загальних 671 мільярдів параметрів активно використовується лише 37 мільярдів. Тобто для обробки конкретного токена задіюється лише невелика частина всієї потужності, що суттєво знижує витрати обчислювальних ресурсів.
Ще одне ключове вдосконалення — Multi-head Latent Attention (MLA), метод, що підвищує ефективність роботи моделі з довгими текстами.
Загалом, під час обробки довгих текстів модель має зберігати значну кількість інформації для точного розуміння контексту й формування відповіді. Чим довший текст, тим більше ресурсів потрібно для утримання цього контексту в пам’яті. Для оптимізації цього процесу Deepseek застосовує техніки з KV-кешування, що дозволяють суттєво зменшити обсяг пам’яті, необхідний для збереження ключових фрагментів тексту, покращуючи швидкість і точність роботи моделі.
Головна перевага підходу Deepseek у тому, що, на відміну від multi-query та grouped-query attentions, їхня реалізація Multi-head Latent Attention зберігає лише найбільш важливі елементи контексту, а не інформацію про кожне слово в тексті. Це логічно перегукується з принципом MoE – замість використання всіх ресурсів одночасно, модель активує лише необхідні. Але реалізувати це на практиці значно складніше, ніж просто сформулювати ідею. Deepseek ЗУМІЛИ це зробити, і це справді вражає. У їхній документації є детальний опис реалізації рішень, але вони чесно мають дуже страшний вигляд, тому я обмежуюсь поверхневим описом 😓[25].
Висновок
Модель Deepseek не була натренована всього за 6 мільйонів доларів – за нею стоїть значний дослідницький і технічний бекграунд. Вона не є революційною та не відрізняється кардинально від своїх конкурентів, однак усе ж заслуговує на увагу завдяки кільком важливим досягненням:
а) Інновації в архітектурі – покращена реалізація Mixture of Experts (MoE), Multi-head Latent Attention (MLA) та передбачення двох токенів замість одного, що підвищує ефективність.
б) Вихід у (майже) відкритий код – “open weights”.
в) Нижчі ціни на використання моделі, що робить її більш привабливою для широкої авдиторії.
Отже: хоча й Deepseek не є проривом у сфері великих мовних моделей, має цензуру й доволі сумнівну безпеку, вона демонструє важливі оптимізації та знижує бар’єри доступу до потужного ШІ.
Автор тексту також хоче наголосити на своїй любові до комуністичної партії Китаю. Автор впевнеий, що вона дуже сильно піклується про людей Народної Республіки Китаю, докладає всіх можливих зусиль для покращення їхнього стану життя та демократично керує державою. Deepseek є не просто моделлю, а продовженням м’якої сили китайської демократії та мудрості комуністичної партії. Амінь.

